
flink架構介紹
前言
flink作為基於流的大資料計算引擎,可以說在大資料領域的紅人,下面對flink-1.7的架構進行邏輯上的分析並和spark做了一些關鍵點的對比。
架構
如圖1,flink架構分為3個部分,client,JobManager(簡稱jm)和TaskManager(簡稱tm)。client負責提交使用者的應用拓撲到jm,注意這和spark的driver用法不同,flink的client只是單純的將使用者提交的拓撲進行優化,然後提交到jm,不涉及任何的執行操作。jm負責task的排程,協調checkpoints,協調故障恢復等。tm負責管理和執行task。通過flink的架構我們可以瞭解到,flink把任務排程管理和真正執行的任務分離,這裡的分離說的是物理分離。而對比spark的排程和執行任務是在一個jvm裡的,也就是driver。分離的好處很明顯,不同任務可以複用同一個任務管理(jm,tm),避免多次提交,缺點可能就是多了一個步驟,需要額外提交維護tm。
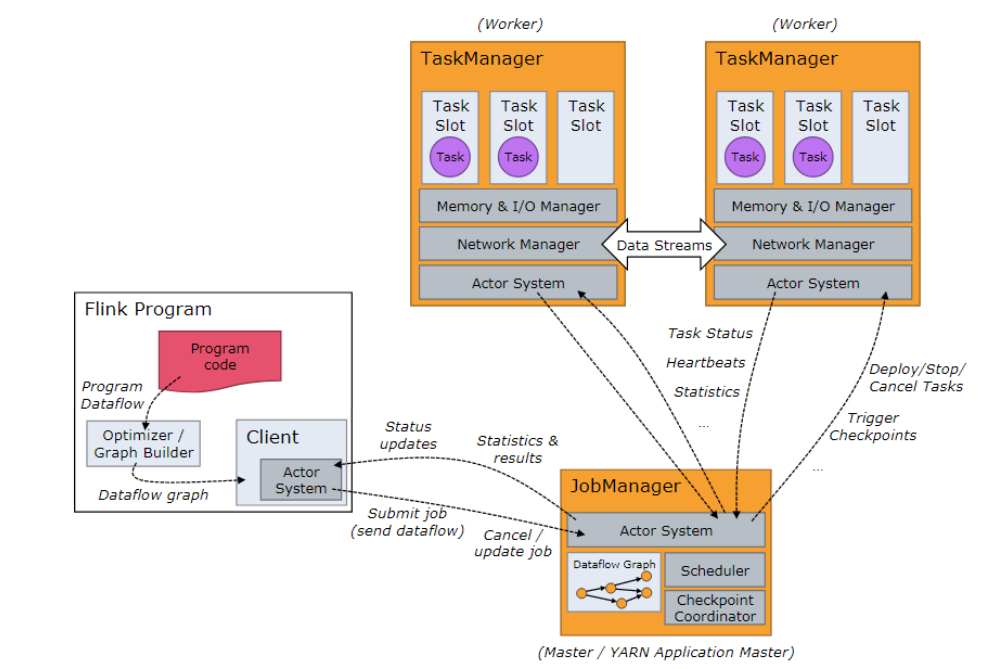
圖1 架構
flink架構中另一個重要的概念是slot,在tm中有一個slot的概念,這個概念類似storm裡的slot,用來控制併發度的,但不同於storm,flink的slot控制的是執行緒。首先1個tm對應1個jvm,然後併發度task對應一個執行緒,而slot就代表1個tm中可以執行的最大的task數。此外,task被tm管理,但是目前只會對記憶體進行管理,cpu是不做限制的。建議slot的數量和該節點的cpu數量保持一致。
部署策略
flink支援多種部署策略,獨立部署模式或者基於其他資源容器yarn,mesos。
standalone
不依賴第三方資源容器進行部署,部署相對麻煩,需要將jm,tm分別部署到多個節點中,然後啟動,一般不建議單獨部署。
yarn
基於yarn的部署是比較常見的,flink提供了兩種基於yarn的提交模式,attached和detached。無論是jb和tm的提交還是任務的提交都支援這兩種模式。和spark基於yarn的兩種模式不同,flink的這兩種模式僅僅只是在client端阻塞和非阻塞的區別,attached模式會hold yarn的session直到任務執行結束,detached模式在提交完任務後就退出client,這個區別是很簡單的。結合flink的架構來看,client不參與任何任務的執行,這點和spark是有很大區別的,不要搞混。
排程
flink同樣採用了基於圖的排程策略,client生成圖然後提交給jm,jm解析後執行。但是flink的對task的執行思路和spark不同,spark是基於一個操作的併發,而flink是基於操作鏈的併發,這裡先解釋一下操作鏈,比如source(),map(),filter()這些都是操作,操作鏈就是多個連續的操作合併到一起,如圖2,source(),map()形成一個操作鏈,keyBy(),window(),apply()[1]形成一個操作鏈。flink這樣設計的目的在於,操作鏈中的所有操作可以使用一個執行緒來執行,這樣可以避免多個操作在不同執行緒執行帶來的上下文切換損失,並且可以直接在一個jvm中共享資料,這個思路可以說是一種新的優化思路。圖3可以從一個任務的角度看到flink的併發思路。
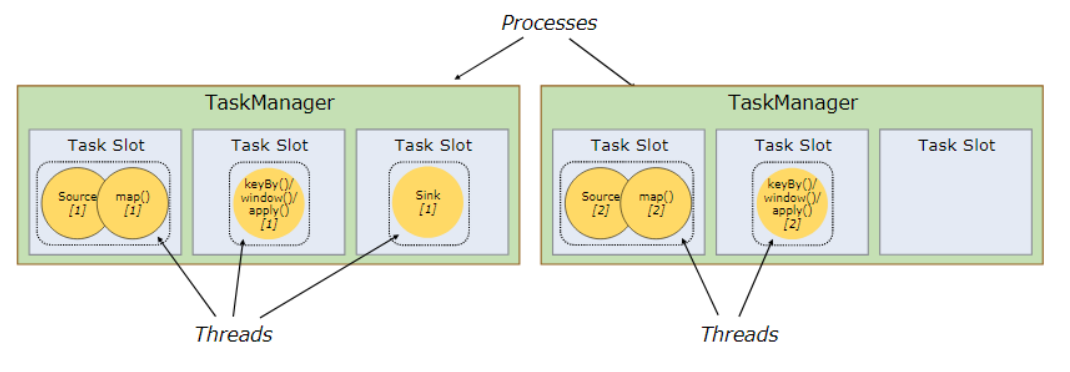
圖2
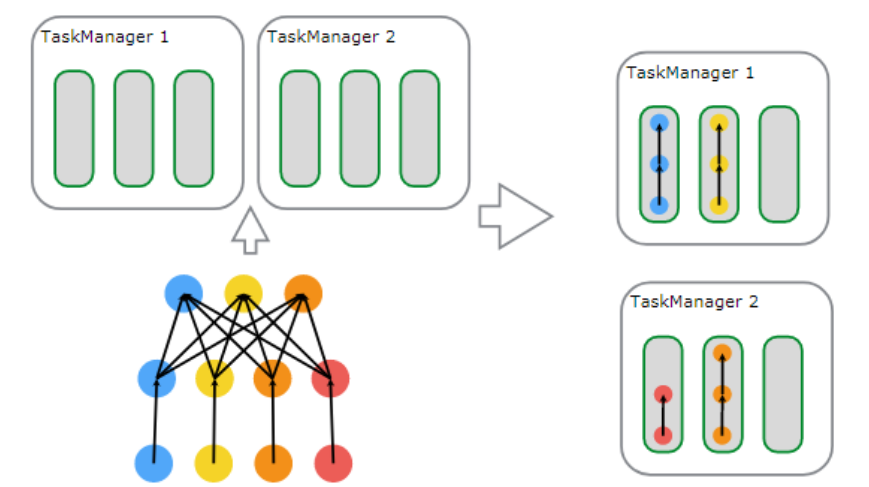
圖3
總結
從架構上來看,flink也採用了常見的主從模型,不過不用擔心flink已經支援了對jm的ha,很多地方可以看到其他大資料計算引擎的影子,在選擇計算引擎的時候可以嘗試一下。
參考
// flink官網對分散式執行環境的介紹
https://ci.apache.org/projects/flink/flink-docs-release-1.7/concepts/runtime.html
// flink官網對排程的介紹
https://ci.apache.org/projects/flink/flink-docs-release-1.7/internals/job_scheduling.html