
訂單中心專案分析與總結
需求背景:隨著業務的發展,公司逐步上線了多種產品和業務線,每個業務線除了一些基礎的服務(比如支付,資產交割等)使用公共服務外,剩餘的部分都是業務線自行處理,這樣就形成了各個業務線自己的訂單。在業務發展的初期,這樣的方式是很方便快捷的,可以使得產品快速上線,但同時也埋下了一些問題:
1,使用者如果需要查自己的訂單,需要到不同的業務線(網站上不同的tab)進行查詢,使用者體驗差(比如無法按照訂單金額排序等)
2,訂單資料沒有統一整合,不利於訂單的統計與分析
3,如果出現一個業務,需要跨業務線使用訂單,這就坑了
為解決上面的幾個問題,我們引入了訂單中心的概念,訂單中心主要提供以下功能:根據使用者id羅列出訂單列表,根據訂單id查詢詳情,以及其他查詢條件。訂單中心接收各個業務線的訂單變更訊息,用於訂單狀態展示以及相應的訂單提醒等。作為訂單操作的統一入口,分發訂單處理:比如撤銷訂單,訂單中心提供統一入口,由訂單中心負責分發呼叫各個業務線的介面。
1,資料收集
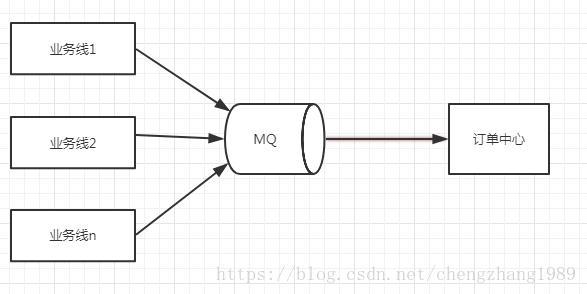
如下圖所示,各個業務線原有的邏輯不變(最大限度的避免改動原有程式碼),在個業務線訂單狀態變更時,傳送mq到訂單中心,訂單中心的資料收集模組作為消費者負責收集資料:
2,資料儲存
(1),資料庫我們使用的是mysql,業務線訂單量的情況如下:
業務線每天產生的訂單總數量在百萬級,未來三年左右,單日最大的增長量應該不會超過500w,所以分庫分表是必須的。
(2),dba有明確規定,分庫分表,最大可分10庫10表,超過不行(可能是資源有限)
(3),只給使用者展示近三年的資料
根據上面的需求和限制,我們分庫分表的方式為10庫10表,按照userId進行取模,每張表的資料容量為1億條資料,所以總共能存100億條資料。100億/365/100w約等於27年左右,意思是按100w的量算這樣的方式可以儲存大約27年的資料,但實際使用中我們只需要展示三年內的資料,超過三年的統統進行歸檔,所以這樣的分庫分表方式大約能夠撐到我們的日訂單量在900w的量級(當前訂單量的9倍左右),完全可以滿足目前的需求,以及架構提出的要求:約10倍資料量的預估。既然有了分庫分表,那資料庫中介軟體就必不可少了,公司選擇的是 tddl(這玩意兒幾年前就推出,後續沒有看到有相關的維護,不如mycat的社群活躍,不過就目前來說足以滿足我們的需求了).
3,資料查詢
第一期需求中我們主要的查詢條件是根據userid和orderid進行查詢,輔以根據使用者手機號,身份證號等進行查詢,查詢時使用者一定要在登陸態,而我們的分庫分表規則是按照userid維度,所以,是能夠滿足需求的,唯一比較彆扭的是每次的查詢條件中必須要有使用者id。
4,後續優化
必須要使用者登陸才能查詢訂單這個要求有一定的侷限性,有時運營人員可能需要根據訂單號或者手機號或者身份證進行查詢,他並不知道使用者id,解決這個問題大致有兩種方式:
(1),進行冗餘的分庫分表,比如根據身份證號或者手機號再進行一次分庫分表
(2),保持原有的分庫分表方式不變,引入elasticsearch,當運營人員進行查詢時,全部走elasticsearch進行查詢
首先我們資源有限,進行冗餘的分庫分表不大現實,其次,如果後續的查詢條件再增加,不可能再根據新增的查詢條件進行冗餘的分庫分表,再者,絕大多數請求都是根據訂單id或者userid進行查詢,所以我們採取的方式為:
保持按照userid維度進行分庫分表的方式不變,但是在訂單id的生成方式上,我們要改變下,具體可看之前總結的分散式系統唯一id的生成,這裡我們只需要保證訂單id的最後兩位與使用者id的左右兩位一致即可,這樣可以直接對訂單id進行取模定位到具體的資料庫,至於其他查詢條件如按手機號查詢等則還是走elasticsearch!