
通過spark-submit提交hadoop配置的方法
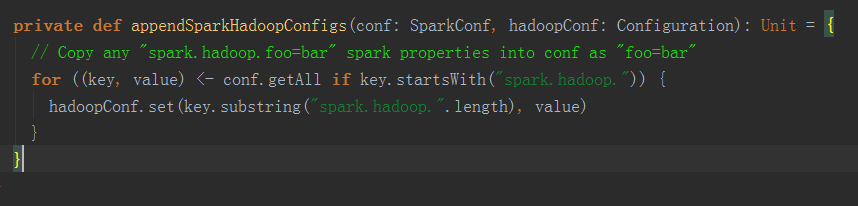
通過spark提交的spark開頭的配置在程式啟動後會新增到SparkConf中,但是hadoop相關的配置非spark開頭會被過濾掉,但是隻要在這些配置的key前面新增spark.hadoop.字首,則該key就不會被過濾,會被放置到SparkConf中;最終會儲存在Configuration 物件中,存入之前會將 spark.hadoop.字首截掉(如:hbase的hbase.zookeeper.quorum,則這樣傳遞:spark-submit --conf spark.hadoop.hbase.zookeeper.quorum),見下方截圖程式碼邏輯
在spark應用中如果要是用這些key,只需要新增如下程式碼即可:
Configuration conf = ss.sparkContext().hadoopConfiguration();
String quorum = conf.get("hbase.zookeeper.quorum");
相關推薦
通過spark-submit提交hadoop配置的方法
通過spark提交的spark開頭的配置在程式啟動後會新增到SparkConf中,但是hadoop相關的配置非spark開頭會被過濾掉,但是隻要在這些配置的key前面新增spark.hadoop.字首,則該key就不會被過濾,會被放置到SparkConf中;最終會儲存在Configuration
php通過shell調用Hadoop的方法
pin start color system info ret -- -c back 1.php代碼(index.php) <!DOCTYPE html> <html> <!-- <style> body{backgroun
idea打jar包與spark-submit提交叢集
一、idea打jar包 project Structure中選擇Aritifacts 選擇+號新建一個要打的jar包 刪除除了 compile output之外的叢集中已經存在的jar包,除非引入了叢集中不存在的jar包 選擇設定主類,再build->
spark-submit 提交任務報錯 java.lang.ClassNotFoundException: Demo02
案例:把sparksql的程式提交到spark的單機模式下執行 package demo01 import org.apache.spark.SparkContext import org.apache.spark.sql.SQLContext import org.apache.spa
spark-submit提交jar包到spark叢集上
一、首先將寫好的程式打包成jar包。在IDEA下使用maven匯出jar包,如下: 在pom.xml中新增以下外掛 <plugin> <groupId>org.apache.maven.plu
spark-submit 提交任務報錯 java.lang.ClassNotFoundException: Demo02
案例:把sparksql的程式提交到spark的單機模式下執行 package demo01 import org.apache.spark.SparkContext import org.apache.spark.sql.SQLContext import org.ap
Spark2.x原始碼分析---spark-submit提交流程
本文以spark on yarn的yarn-cluster模式進行原始碼解析,如有不妥之處,歡迎吐槽。 步驟1.spark-submit提交任務指令碼 spark-submit --class 主類路徑 \ --master yarn \ --deploy-mode c
spark submit提交任務報錯Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/stream
1.問題描述 提交spark任務: bin/spark-submit --master local[2] \ --class _0924MoocProject.ImoocStatStreamingApp_product \ /opt/datas/project/scala
使用spark-submit提交jar包到spark standalone叢集(續)
繼續上篇文章利用Intellij Idea在windows搭建spark 開發環境(含打jar包過程)(一) 以及Sparksql處理json日誌[要求sparksql統計json日誌條數存入mysql資料庫] 本章將把打好
蝸龍徒行-Spark學習筆記【四】Spark叢集中使用spark-submit提交jar任務包實戰經驗
一、所遇問題 由於在IDEA下可以方便快捷地執行scala程式,所以先前並沒有在終端下使用spark-submit提交打包好的jar任務包的習慣,但是其只能在local模式下執行,在網上搜了好多帖子設定VM引數都不能啟動spark叢集,由於實驗任務緊急只能暫時
spark-submit提交任務到叢集
1.引數選取 當我們的程式碼寫完,打好jar,就可以通過bin/spark-submit 提交到叢集,命令如下: ./bin/spark-submit \ --class <main-class> --master <master-url>
平臺搭建---Spark Submit提交應用程式
本部分來源,也可以到spark官網檢視英文版。 spark-submit 是在spark安裝目錄中bin目錄下的一個shell指令碼檔案,用於在叢集中啟動應用程式(如*.py指令碼);對於spark支援的叢集模式,spark-submit提交應用的時候有統一的
[轉] spark-submit 提交任務及參數說明
https 不包含 dep apache 沖突 哪裏 mas repo ado 【From】 https://www.cnblogs.com/weiweifeng/p/8073553.html#undefined spark-submit 可以提交任務到 spark
Spark spark-submit 提交的幾種模式
local 模式 程式碼 package com.imooc.spark.Test import org.apache.spark.sql.types.{StringType, StructField, StructType} import org
Spark 通過 spark-submit 設定日誌級別
前言 Spark有多種方式設定日誌級別,這次主要記錄一下如何在spark-submit設定Spark的日誌級別。 1、需求 因為Spark的日誌級別預設為INFO(log4j.rootCategory=INFO, console),這樣在執行程式的時候有很多我
Hadoop 2.0中的日誌收集以及配置方法
命名 tail his als 作業 fix enable 決定 RM Hadoop中的日誌包含三個部分,Application Master產生的運行日誌和Container的日誌。 一、ApplicationMaster產生的作業運行日誌 Application Mas
Spark提交應用程序之Spark-Submit分析
需要 使用 please requested 建議 eas -m rfs export 1.提交應用程序 在提交應用程序的時候,用到 spark-submit 腳本。我們來看下這個腳本: if [ -z "${SPARK_HOME}" ]; then export
hadoop dfs.datanode.du.reserved 預留空間配置方法
rep 目錄 可能 dfs sad property pro AI reserve 對於datanode配置預留空間的方法 為:在hdfs-site.xml添加如下配置 <property> <name>dfs.datanode.du.re
Crontab執行java/spark-shell/spark-submit 異常解決方法
現象: java/spark-shell/spark-submit 語句在linux shell中直接執行時沒有任何問題,但是放到crontab中就出異常,且異常一般都拋在一些基礎庫裡,讓人感覺非常莫名,比如這種: Traceback (most recent call last): &
使用ssm框架 通過ajax非同步提交資料具體實現方法
以前是一名php開發人員,最近公司開始一個java開發的erp專案,從新學起的感覺倍爽,各種問題各種遇到,從通過ajax非同步提交資料具體實現方法這裡開始,以後在部落格上慢慢呈現,話不多說,下面就是我通過springMvc和ajax非同步實現資料更新的解決方法。 雖然網上已經有好多的解決的方