
基於神經網路的驗證碼實驗研究(一)
前言
本次實驗研究完整程式碼 ->進入 From Github
一.CAPTCHA
提到驗證碼,生活中各種各樣的平臺都會在使用者常規操作管理下實行驗證碼機制。對於我淺顯的理解,一是區分人與機器的認證互動,在有行為發生的情況下,我們要判斷是否是使用者主觀操作,本意所為,因此加上驗證碼機制會使得我們的資訊資料和資金數字財產得到一定基礎屏障。二是對於驗證碼,尤其為語言驗證碼,如漢文字驗證碼和其他語言字串驗證碼,對於國外的一些惡意人員也會具有一定作用的防護屏障等等。
那麼這個CAPTCHA,在生活工作中的重大存在意義呢?
Completely Automated Public Turing test to Tell Computers and Humans Apart
譯為全自動區分計算機和人類的圖靈測試
- 其測試內容,主要是利用人類腦中的辨別能力,對一些難以被計算機識別的字元等影象進行辨認,以此用這些 “計算機不能完成”的行為,從根本辨別出“人” 和 “計算機”
。而基於這種測試的程式,必須能生成並評價人類能很容易通過,但計算機卻通不過的測試。因此CAPTCHA通俗點的名字,才叫人機驗證。- reCAPTCHA,是在原 CAPTCHA 測試基礎上進行延展的技術,相比傳統的人機驗證,其本質更像是 “讓計算機求助於人類”,在 2009 年被 Google 收購,並以此基礎進行再開發。
- 它實際上由 “NoCAPTCHA” 和 “reCAPTCHA” 兩部分組成,其一是一個簡單的認證系統,上面只有一句 “我不是機器人”和一個等你打勾的方框,當你確認後,用一系列 “風險分析引擎” 對使用者進行無縫分析,並以此來判斷你是否是一個 “真人” 。
- 很多網站都在註冊、評論系統中使用驗證碼,以防止別人惡意註冊虛假賬號或釋出垃圾評論。
二.研究內容
隨著人工智慧的興起,在計算機視覺(CV)領域上也有重大的突破進展,運用深度神經網路進行影象檢測和研發並投入使用的演算法已相當成熟,不管是從高校、科研處等教育領域,還是在工業化商用化領域上都投以大量的研製演算法用來處理實際問題。這些研發出來的系統模組可以從不同的角度去理解和識別連續動作影象畫面中的人和物體。
以往從影象資料中抽取我們認為有價值的資訊會很難,而這些影象包含大量原始資料,影象的標準編碼單元(畫素)提供的資訊量很少。影象,尤其是照片可能存在一些難以解決的問題,比如模糊不清、離目標太近、光線很暗或太亮、比例失真、殘缺、扭曲等,這會增加計算機系統抽取有用資訊的難度。
基於神經網路識別影象中的字母,從而去自動識別驗證碼。在PycharmIDE,用Python進行資料採集、資料處理、影象識別,並運用網路迭代計算來破解驗證碼。
- 對PIL/Pillow、Ntlk、Numpy、skimage、sklearn的掌握。
- 建立驗證碼和字母資料集。
- 使用神經網路進行分類任務。
- 多層感知機。
- 圖片英文單詞的分割和識別。
- 使用列文斯坦編輯距離提高識別率。
- 進行優化處理提升運作效果。
三.資料集的採集
資料資源來自開源字型檔(Open Font Library),Download所需字型檔案:http://openfontlibrary.org/en/font/bretan
本實驗研究使用的是Coval-Black.ttf
四.訓練研究過程
-
匯入相關模組:
import numpy as np import nltk from nltk.corpus import words from nltk.metrics import edit_distance from matplotlib import pyplot as plt from PIL import Image, ImageDraw, ImageFont from skimage import transform as tf from skimage.transform import resize from skimage.measure import label, regionprops from sklearn.utils import check_random_state from sklearn.neural_network import MLPClassifier from sklearn.model_selection import train_test_split from sklearn.preprocessing import OneHotEncoder from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from operator import itemgetter import warnings warnings.filterwarnings("ignore") -
建立用於生成驗證碼的基礎函式
這個函式接收一個單詞和錯切值(通常在0到0.5之間),返回用numpy陣列格式表示的影象。該函式還提供指定影象大小的引數,因為後面還會用它生成只包含單個字母的測試資料。
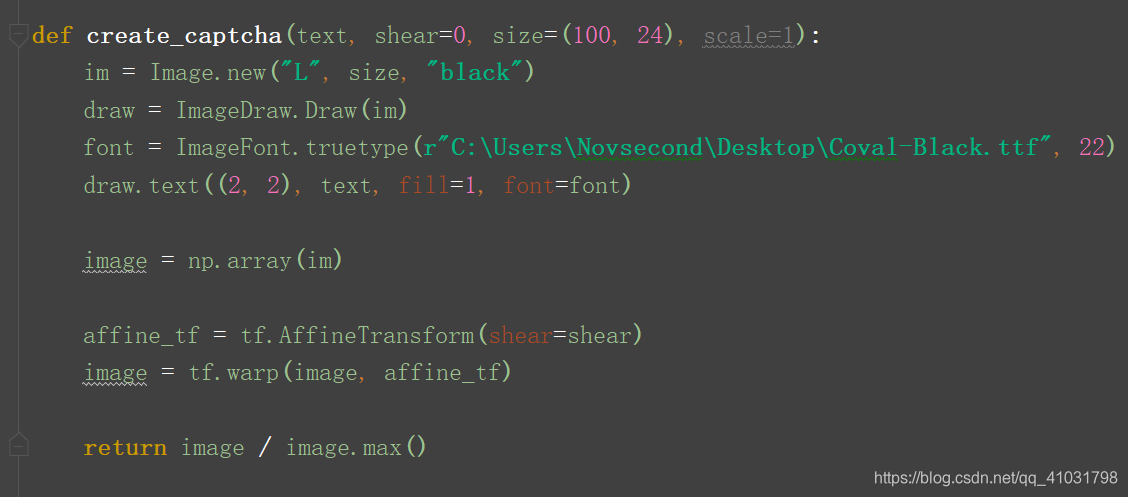
- 用字母’L’來生成一張黑白影象,為
ImageDraw類初始化一個例項。 - 指定驗證碼文字所使用的字型。這裡用到Coval-Black.ttf,
r指向檔案存放位置。 - 把PIL影象轉換為
numpy陣列,以便用scikit-image庫為影象新增錯切變化效果。 - scikit-image
大部分計算都使用numpy`陣列格式。 - 最後
return image / image.max()對影象特徵進行歸一化處理,確保特徵值落在0到1之間。
- 使用pyplot繪製圖像

效果圖片所示: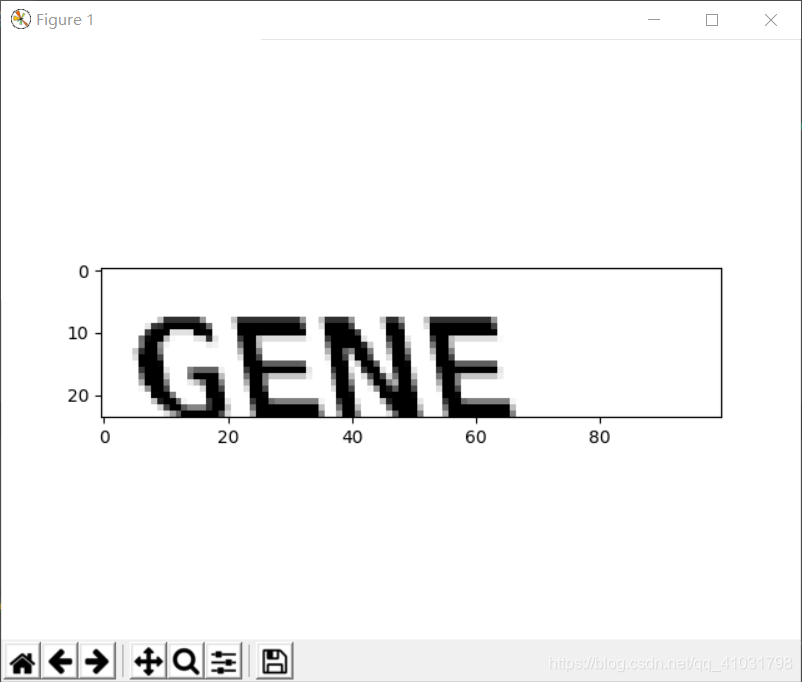
- 分割單詞
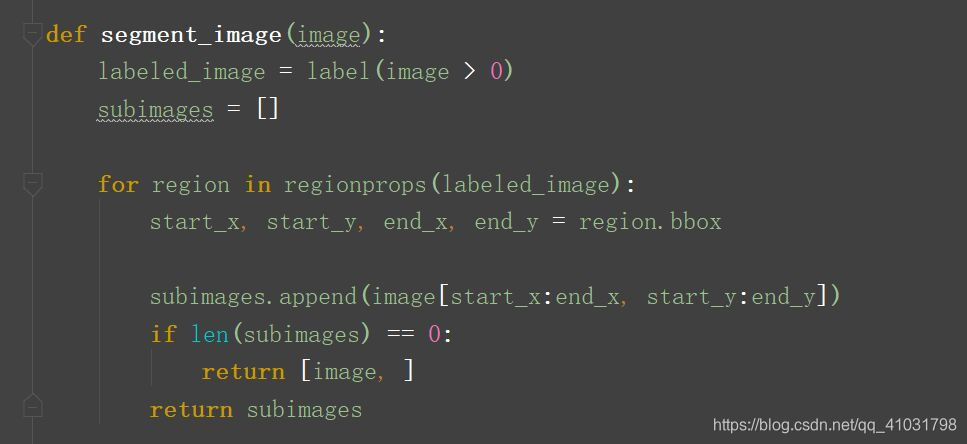
建立一個函式,尋找影象中連續的黑色畫素,抽取它們作為新的小影象。 - 建立訓練集

-
指定隨機狀態值,建立字母列表,指定錯切值。

-
呼叫函式生成一條訓練資料,用pyplot顯示影象。
效果圖片所示:
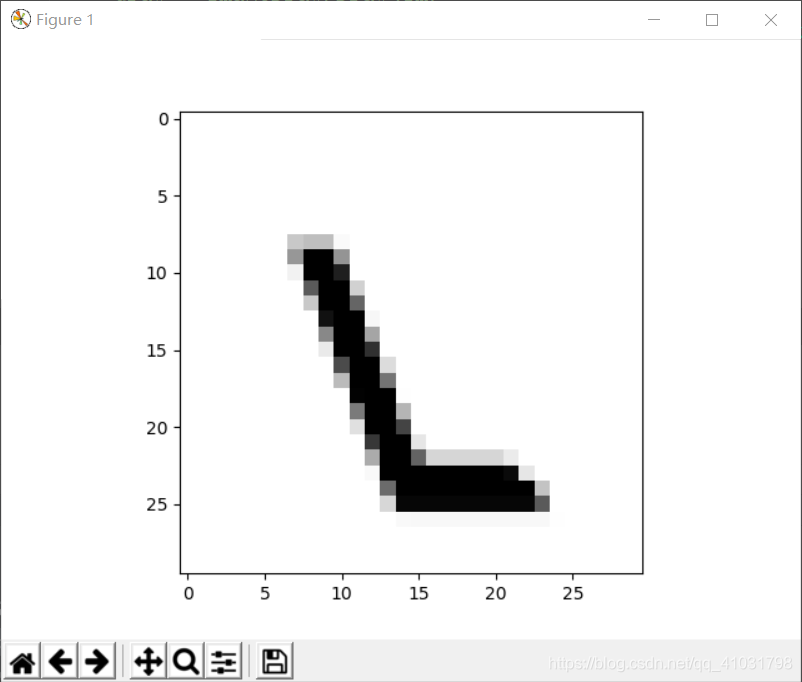
6.呼叫更多次數函式生成資料
- 呼叫更多次數的該函式,生成足夠的訓練資料。
- 把這些資料傳入到numpy的數組裡。
- 在
sklearn包中,OneHotEncoder函式非常實用,可以實現將分類特徵的每個元素轉化為一個可以用來計算的值。
String字串轉換成索引IndexDouble
索引轉換成SparseVector
OneHotEncoder = String > IndexDouble > SparseVector
更多的瞭解OneHotEncoder
y=y.todense()將稀疏矩陣轉換為密集矩陣。(相關庫不支援稀疏矩陣)

7.根據抽取方法調整訓練資料集
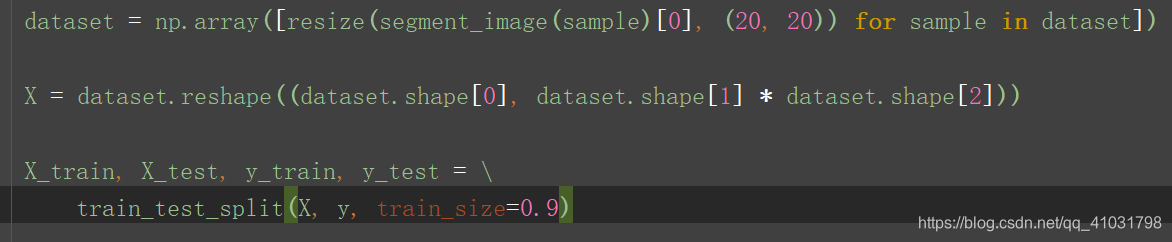
- 在訓練集上執行分割函式,返回分割後得到的字母影象 。
- 用到
scikit-image庫中的resize函式。