
【Python3 爬蟲學習筆記】Scrapy框架的使用 1
阿新 • • 發佈:2018-12-17
Scrapy功能非常強大,爬取效率高,相關擴充套件元件多,可配置和可擴充套件程度非常高,它幾乎可以應對所有發爬網站,是目前Python中使用最廣泛的爬蟲框架。
Scrapy框架介紹
Scrapy是一個基於Twisted的非同步處理框架,是純Python實現的爬蟲框架,其架構清晰,模組之間的耦合程度低,可擴充套件性極強,可以靈活完成各種需求。我們只需要定製開發幾個模組就可以輕鬆實現一個爬蟲。
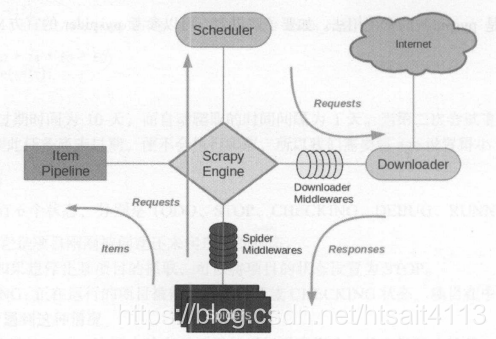
架構介紹
它可以分為如下幾個部分:
- Engine。引擎,處理整個系統的資料流處理、觸發事務,是整個框架的核心。
- Item。專案,它定義了爬取結果的資料結構,爬取的資料會被賦值成該Item物件。
- Scheduler。排程器,接受引擎發過來的請求並將其加入佇列中,在引擎再次請求的時候將請求提供給引擎。
- Downloader。下載器,下載網頁內容,並將網頁內容返回給蜘蛛。
- Spiders。蜘蛛,其內定義了爬取的邏輯和網頁的解析規則,它主要負責解析響應並生成提取結果和新的請求。
- Item Pipeline。專案管道,負責處理由蜘蛛從網頁中抽取的專案,它的主要任務是清洗、驗證和儲存資料。
- Downloader Middlewares。下載器中介軟體,位於引擎和下載器之間的鉤子框架,主要處理引擎和下載器之間的請求及響應。
- Spider Middlewares。蜘蛛中介軟體,位於引擎和蜘蛛之間的鉤子框架,主要處理蜘蛛輸入的響應和輸出的結果及新的請求。
資料流
Scrapy中的資料流由引擎控制,資料流的過程如下。
- Engine首先開啟一個網站,找到該處理網站的Spider,並向該Spider請求第一個爬取的URL。
- Engine從Spider中獲取到第一個要爬取的URL,並通過Scheduler以Request的形式排程。
- Engine想Scheduler請求下一個要爬取的URL。
- Scheduler返回下一個要爬取的URL給Engine,Engine將URL通過Downloader Middlewares轉發給Downloader下載。
- 一旦頁面下載完畢,Downloader生成該頁面的Response,並將其通過Downloader Middlewares傳送給Engine。
- Engine從下載器中接收到Response,並將其通過Spider Middlewares傳送給Spider處理。
- Engine處理Response,並返回爬取到的Item及新的Request給Engine。
- Engine將Spider返回的Item給Item Pipeline,將新的Request給Scheduler。
- 重複第2步到第8步,知道Scheduler中沒有更多的Request,Engine關閉該網站,爬取結束。
通過多個元件的相互寫作、不同元件完成工作的不同、元件對非同步處理的支援,Scrapy最大限度地利用了網路頻寬,大大提高了資料爬取和處理的效率。