
【Python3】pandas.read_csv詳解
阿新 • • 發佈:2018-12-17
Python資料分析,一般第一步就是讀取資料,這篇詳解pandas讀取資料read_csv。
-
read_csv函式引數
幾個常用的引數包括path、sep、header、index_col、names、skiprows、na_values、nrows、skip_footer、encoding。下面主要對這幾個引數解釋 。

-
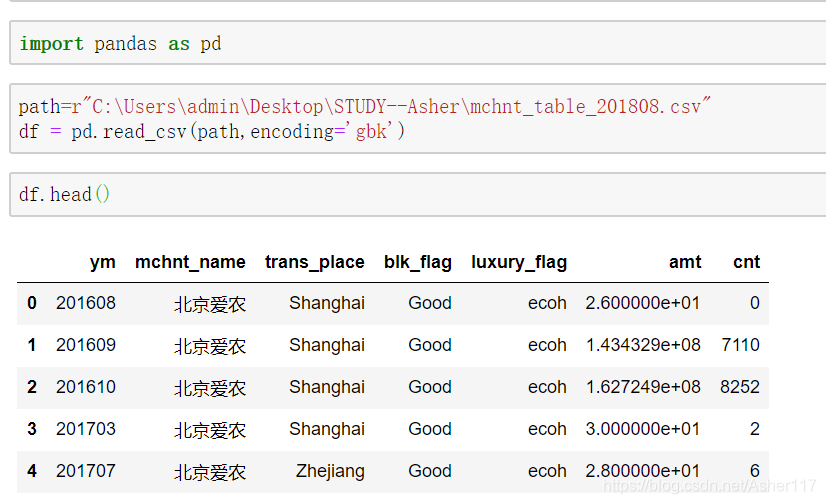
讀取檔案,必要引數path給出檔案路徑,encoding設定csv檔案編碼格式,預設為“utf-8”,這裡檔案格式為“gbk”。
-
sep給出檔案分隔符,預設為‘,’,這裡檔案分隔符也是‘,’,如果分隔符為其他符號,可以用此引數。

-
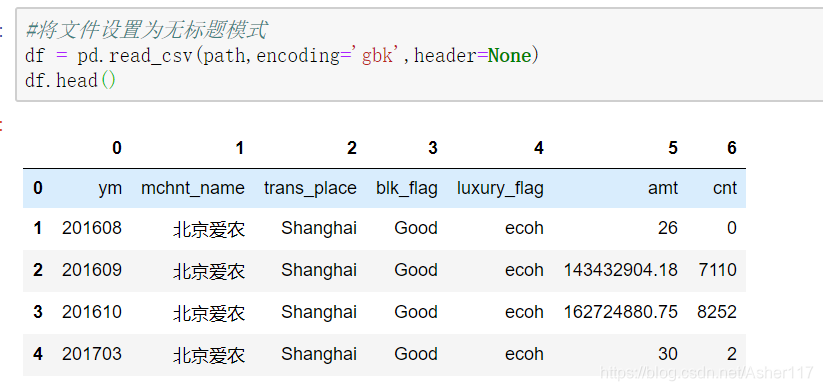
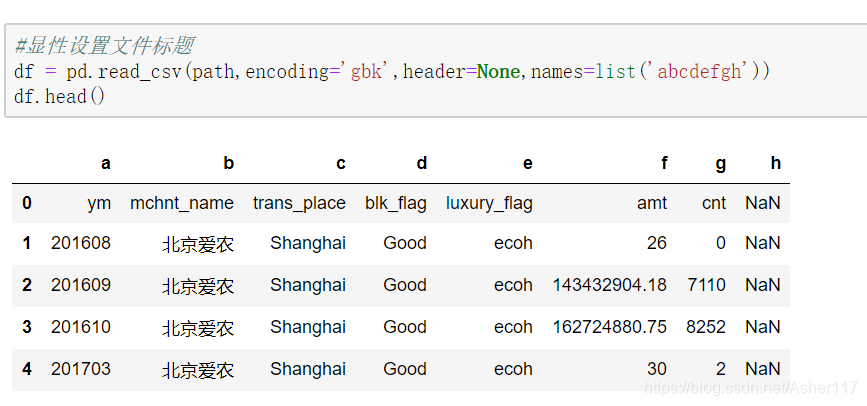
header預設為0,表示第0行為標題,可以給定None表示檔案無標題,同時在header為None時可以給定引數names來給定列名。
-
skiprows可以選擇忽略前面的行數,通過下圖可以對比使用skiprows前後的shape。

-
na_values可以用來替換NA值,當然這裡我的資料沒有NA,如果有的話可以用這個引數。
-
nrows從檔案開始時選取需要讀取的行數。可以看到使用nrows=3之後,資料只有前三行。(df.head()預設讀取前五行)

-
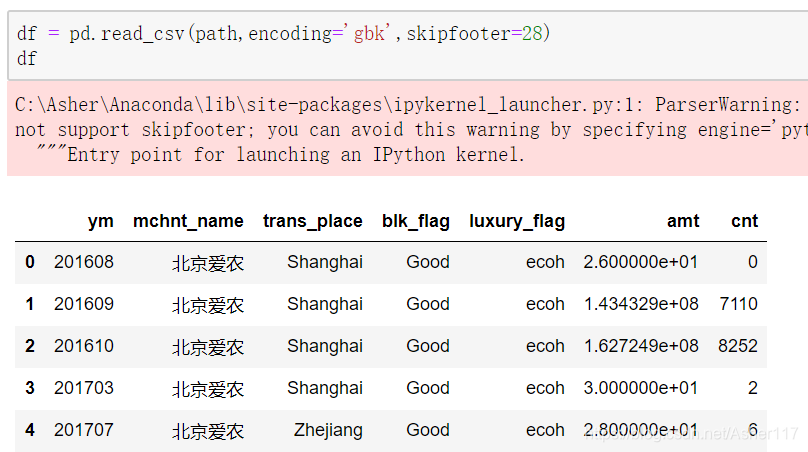
skipfooter從檔案末尾選擇需要忽略的行數。忽略了28行之後,只剩下前五行了。
我們下次再見,如果還有下次的話!!!
歡迎關注微信公眾號:516資料工作室
