
第9章 慕課網日誌實戰
9-1 -課程目錄

9-2 -使用者行為日誌概述
為什麼要記錄使用者訪問行為日誌?
網站頁面的訪問量
網站的粘性
推薦
使用者行為日誌
Nginx ajax
使用者行為日誌:使用者每次訪問網站時所有的行為資料(訪問、瀏覽、搜尋、點選...)
使用者行為軌跡、流量日誌
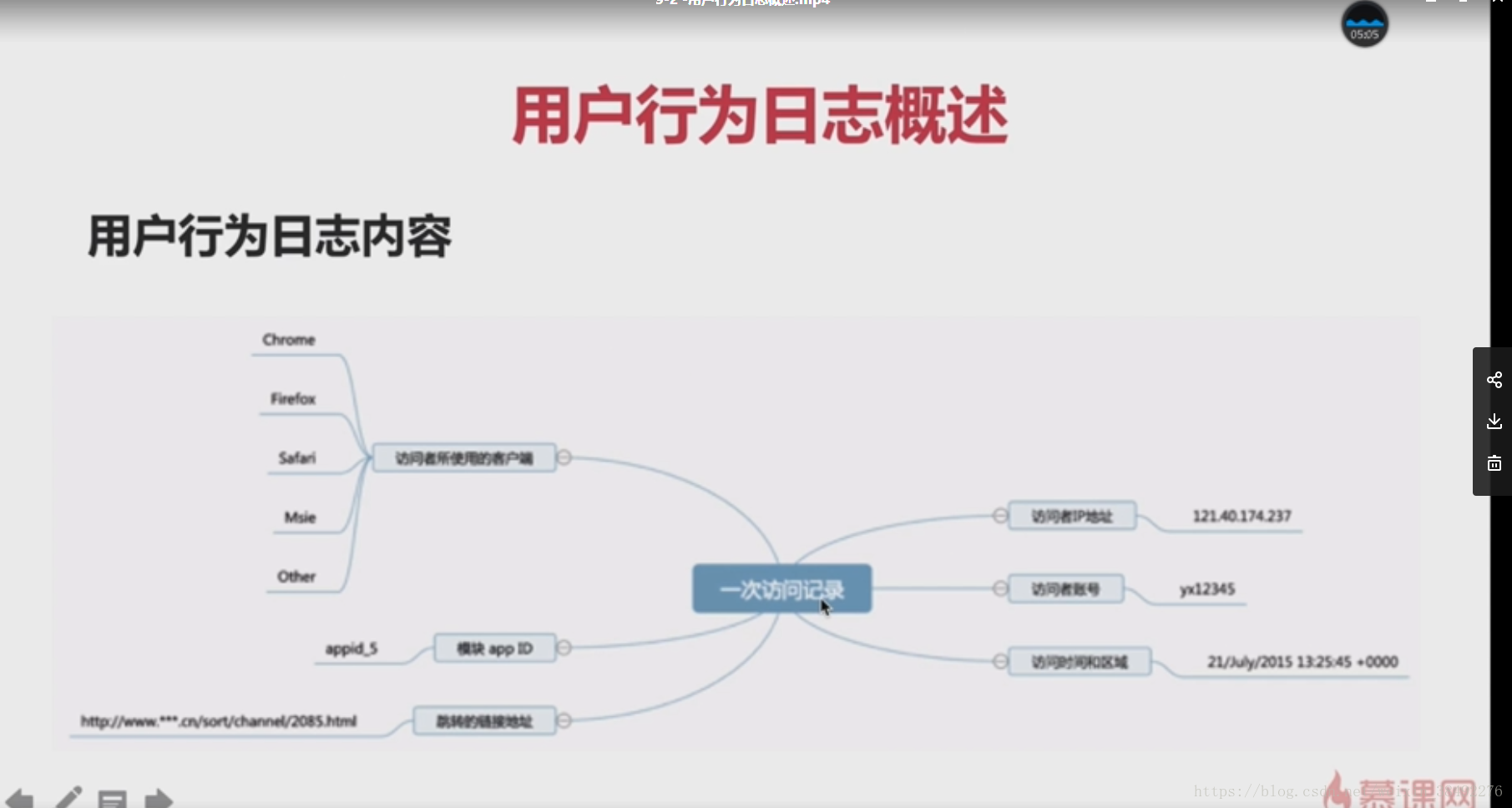
日誌資料內容
1)訪問的系統屬性:作業系統,瀏覽器等等
2)訪問特徵:點選的url,從哪個URL跳轉過來的(referer),頁面上的停留時間等
3) 訪問資訊:session_id,訪問ip(訪問城市)等
使用者行為日誌分析的意義
網站的眼睛 網站的神經 網站的大腦
9-3 -離線資料處理架構
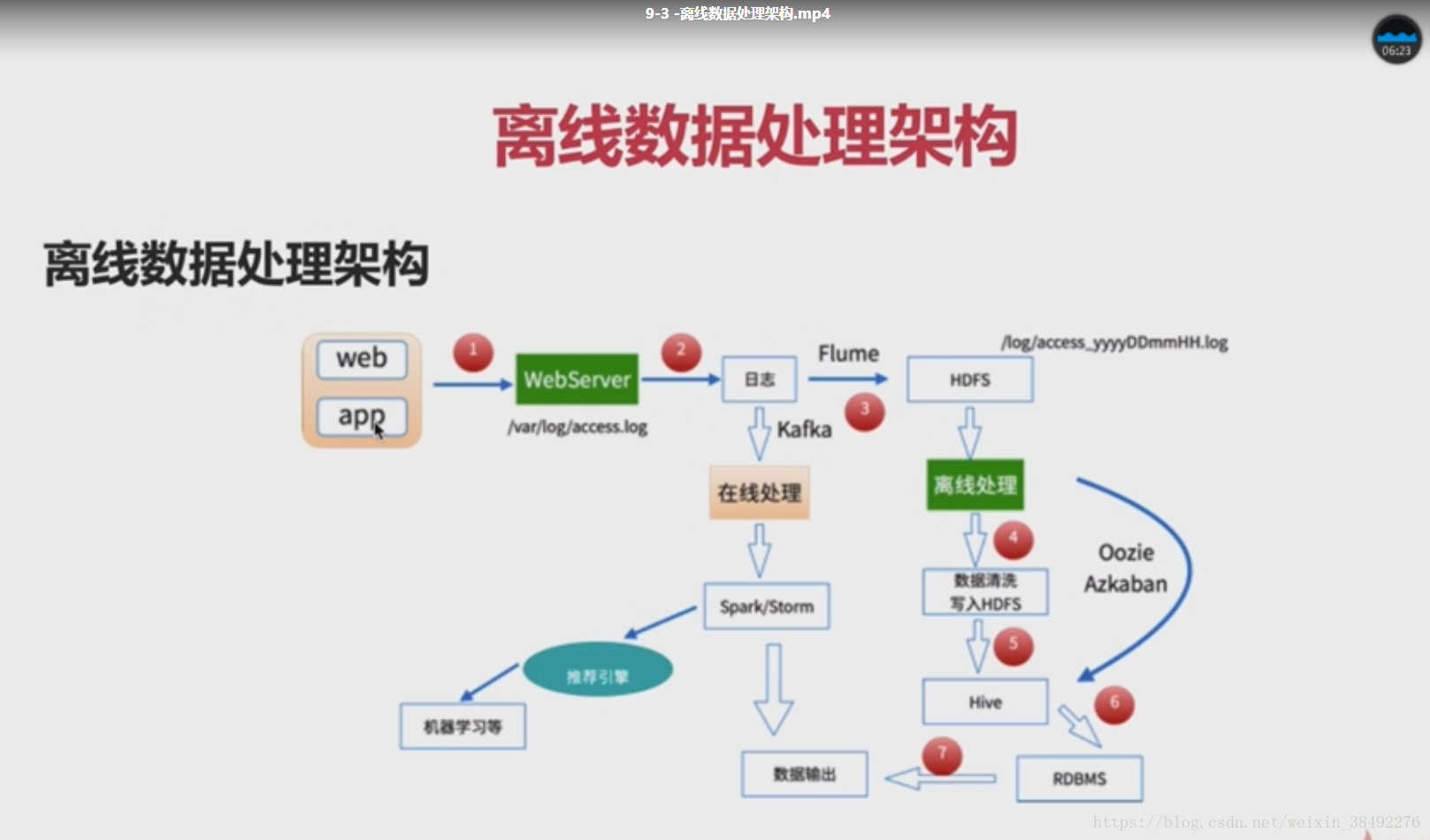
資料處理流程
1)資料採集
flume: web日誌寫入到HDFS
2)資料清洗
髒資料
spark、hive、MapReduce 或者是其他的一些分散式計算框架
清洗完之後的資料可以存放到HDFS(Hive/spark sql)
3)資料處理
按照我們的需要進行相應的統計和分析
spark、hive、MapReduce 或者是其他的一些分散式計算框架
4)處理結果入庫
結果可以存放在RDBMS、Nosql
5)資料的視覺化
通過圖形化展示出來:餅圖、柱狀圖、地圖、折線圖
ECharts、HUE、Zepplin
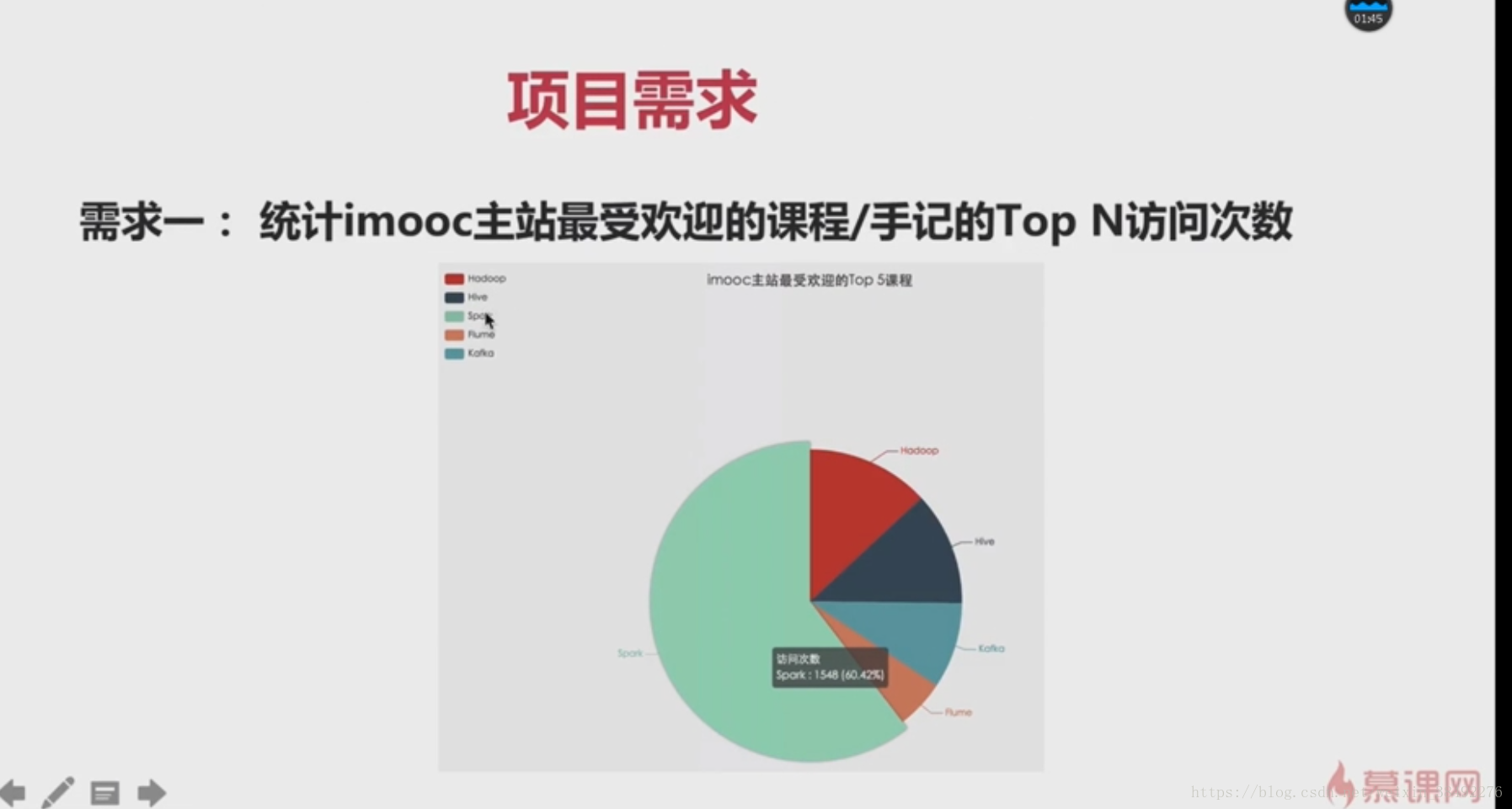
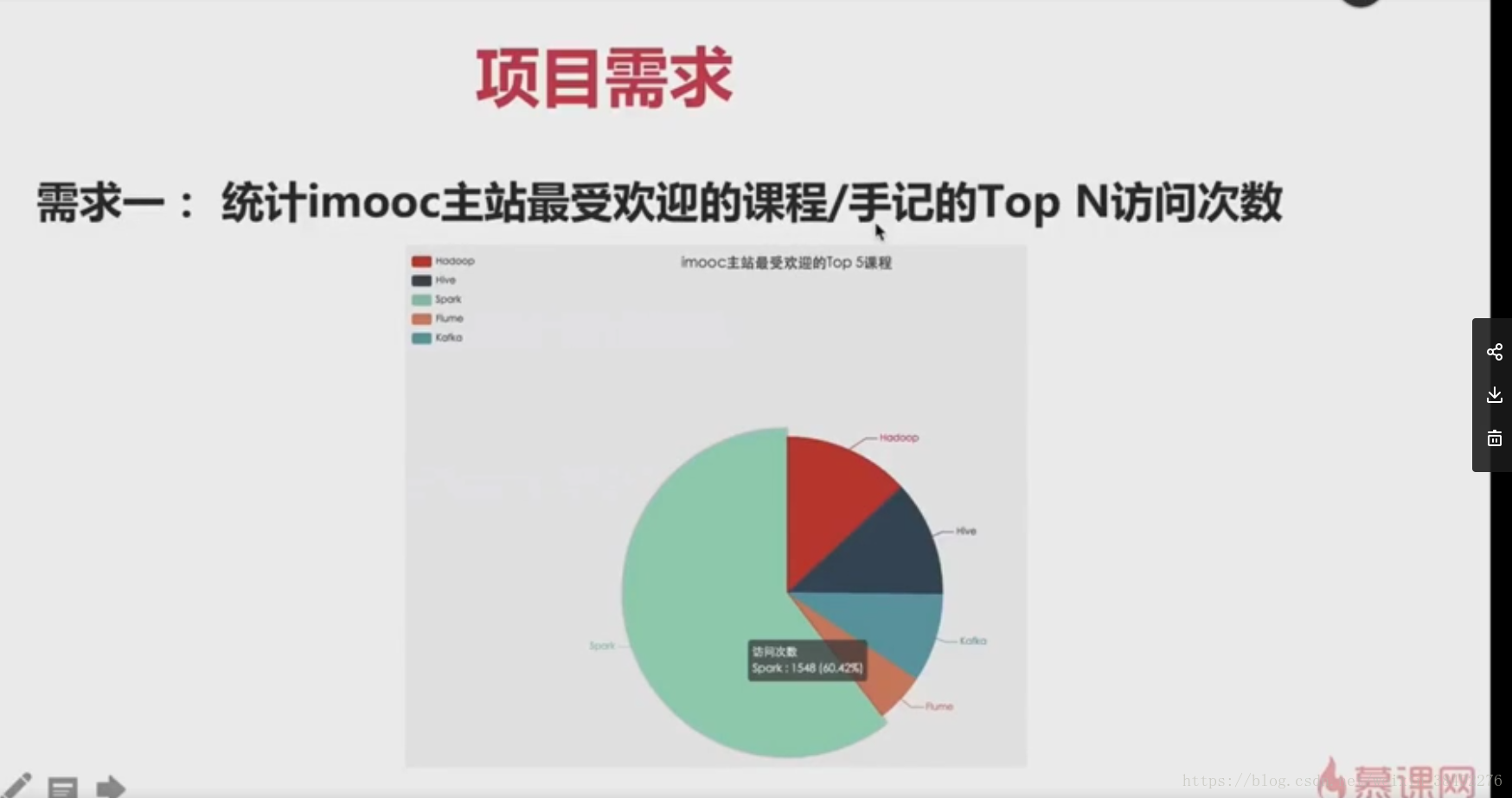
9-4 -專案需求

9-5 imooc網主站日誌內容構成
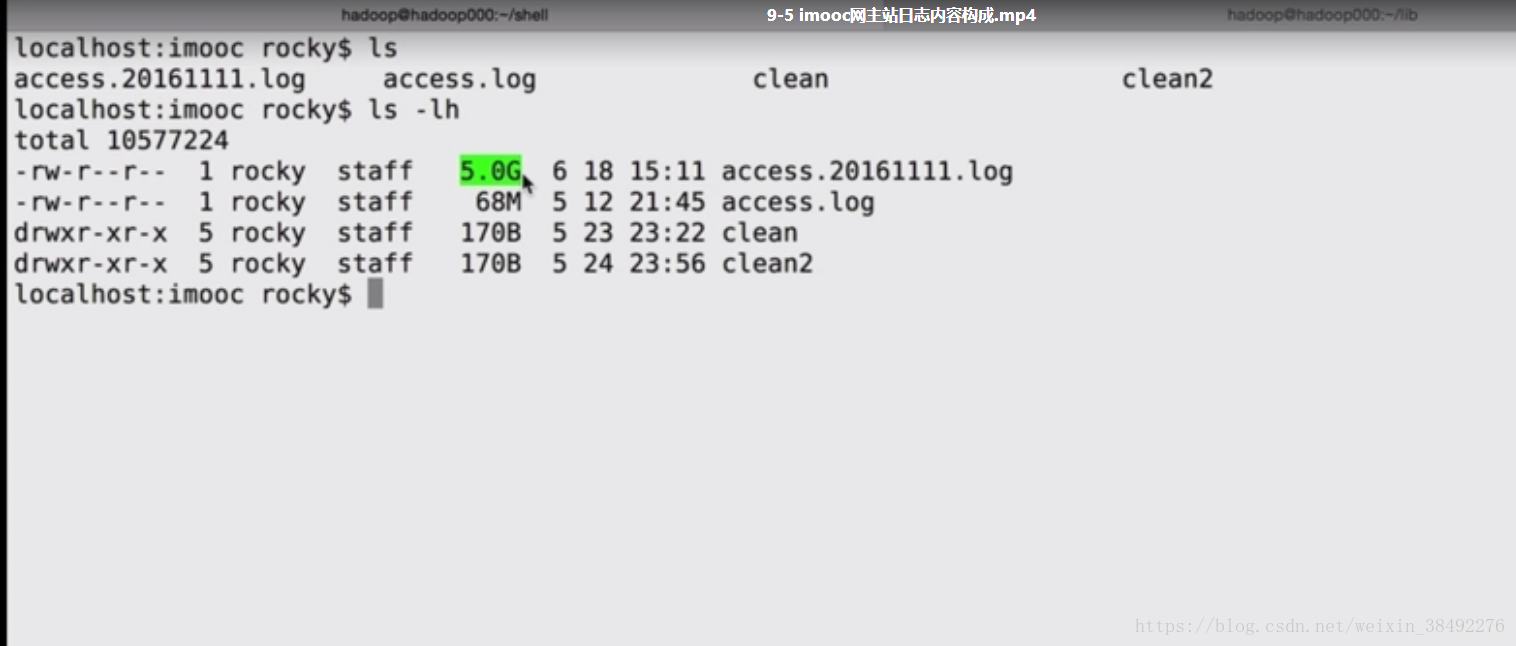
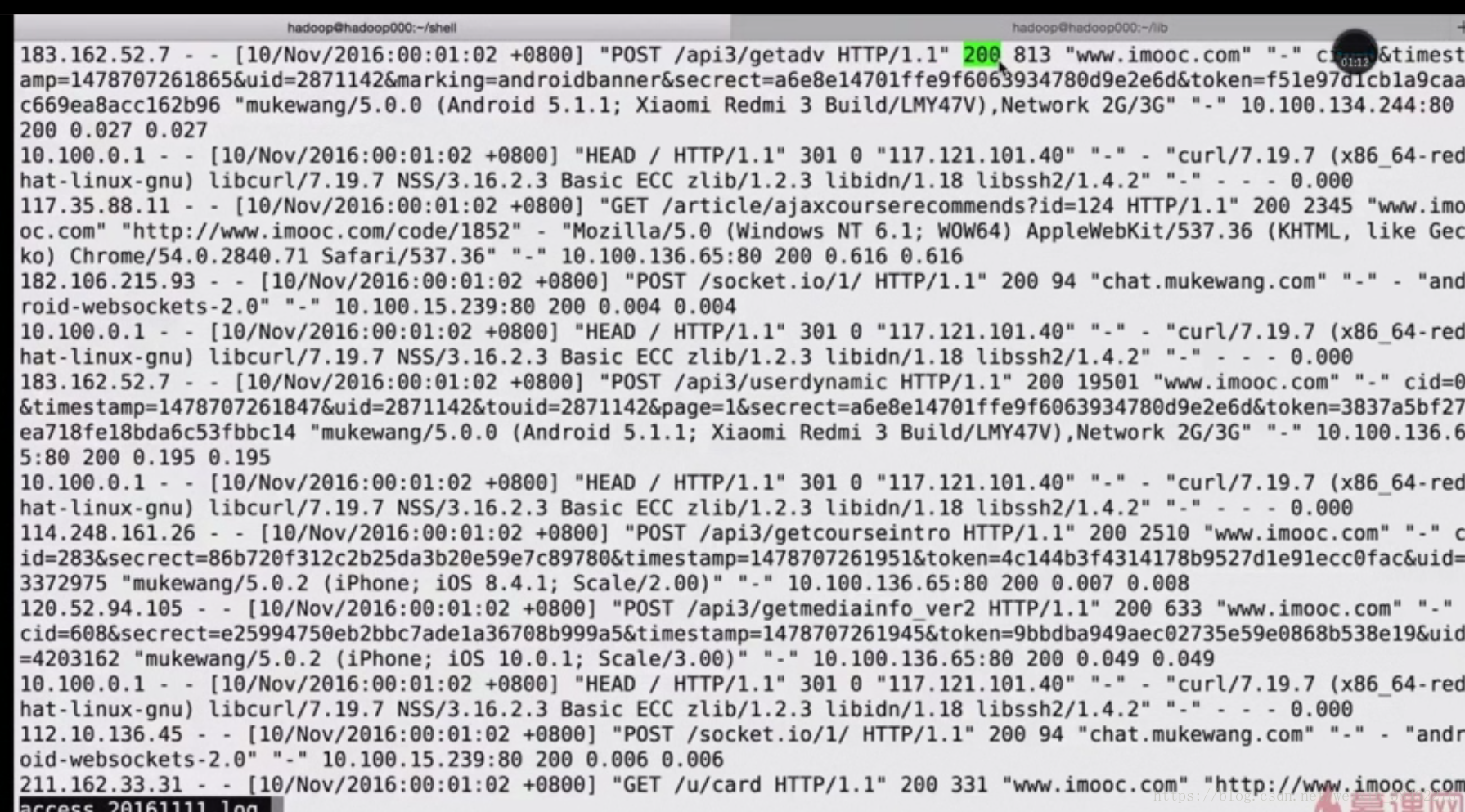

9-6 資料清洗之第一步原始日誌解析
專案地址:
package com.imooc.log
import org.apache.spark.sql.SparkSession
/**
* 第一步清洗:抽取出我們所需要的指定列的資料
*/
object SparkStatFormatJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatFormatJob")
.master("local[2]").getOrCreate()
val acccess = spark.sparkContext.textFile("/Users/rocky/data/imooc/10000_access.log")
//acccess.take(10).foreach(println)
acccess.map(line => {
val splits = line.split(" ")
val ip = splits(0)
/**
* 原始日誌的第三個和第四個欄位拼接起來就是完整的訪問時間:
* [10/Nov/2016:00:01:02 +0800] ==> yyyy-MM-dd HH:mm:ss
*/
val time = splits(3) + " " + splits(4)
val url = splits(11).replaceAll("\"","")
val traffic = splits(9)
// (ip, DateUtils.parse(time), url, traffic)
DateUtils.parse(time) + "\t" + url + "\t" + traffic + "\t" + ip
}).saveAsTextFile("file:///Users/rocky/data/imooc/output/")
spark.stop()
}
}
9-7 -資料清洗之二次清洗概述

一般的日誌處理方式,我們是需要進行分割槽的,
按照日誌的訪問時間進行相應的分割槽,比如:d,h,m5(每五分鐘一個分割槽)
9-8 -資料清洗之日誌解析

清洗工作
package com.imooc.log
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* 使用Spark完成我們的資料清洗操作
*/
object SparkStatCleanJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatCleanJob")
.config("spark.sql.parquet.compression.codec","gzip")
.master("local[2]").getOrCreate()
val accessRDD = spark.sparkContext.textFile("/Users/rocky/data/imooc/access.log")
//accessRDD.take(10).foreach(println)
//RDD ==> DF
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct)
// accessDF.printSchema()
// accessDF.show(false)
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save("/Users/rocky/data/imooc/clean2")
spark.stop
}
}
9-9 -資料清洗之ip地址解析
https://github.com/wzhe06/ipdatabase
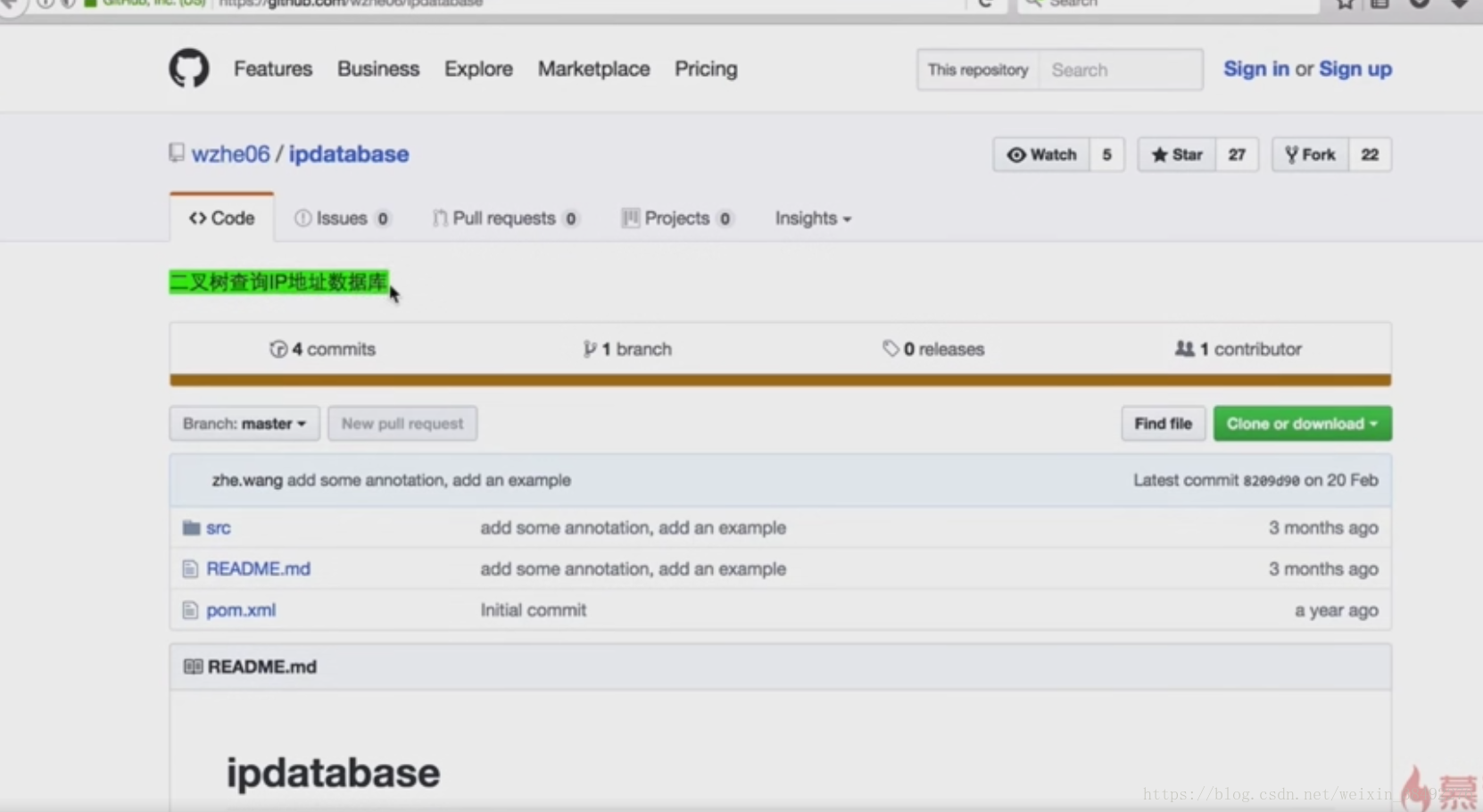
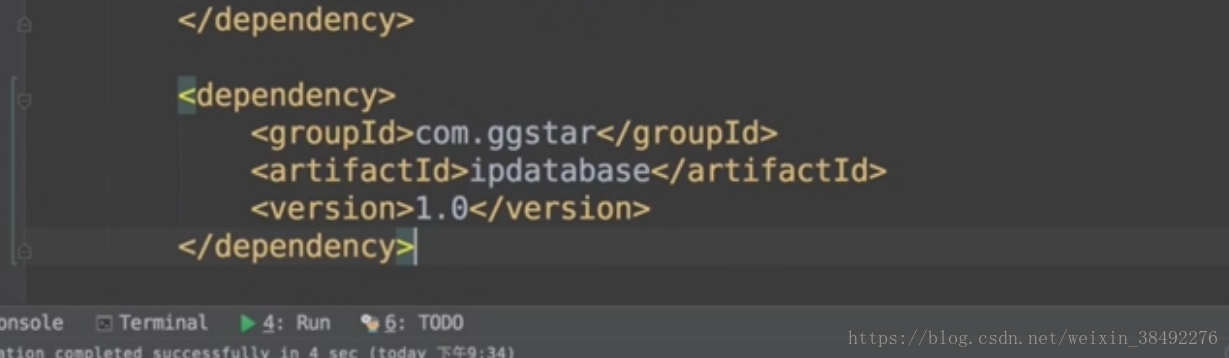
package com.imooc.log
import com.ggstar.util.ip.IpHelper
/**
* IP解析工具類
*/
object IpUtils {
def getCity(ip:String) = {
IpHelper.findRegionByIp(ip)
}
def main(args: Array[String]) {
println(getCity("218.75.35.226"))
}
}
9-10 -資料清洗儲存到目標地址
package com.imooc.log
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* 使用Spark完成我們的資料清洗操作
*/
object SparkStatCleanJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatCleanJob")
.config("spark.sql.parquet.compression.codec","gzip")
.master("local[2]").getOrCreate()
val accessRDD = spark.sparkContext.textFile("/Users/rocky/data/imooc/access.log")
//accessRDD.take(10).foreach(println)
//RDD ==> DF
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct)
// accessDF.printSchema()
// accessDF.show(false)
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save("/Users/rocky/data/imooc/clean2")
spark.stop
}
}

9-11 -需求一統計功能實現

程式碼地址:
原始碼
package com.imooc.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
/**
* TopN統計Spark作業
*/
object TopNStatJob {
def videoAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
/**
* 使用DataFrame的方式進行統計
*/
import spark.implicits._
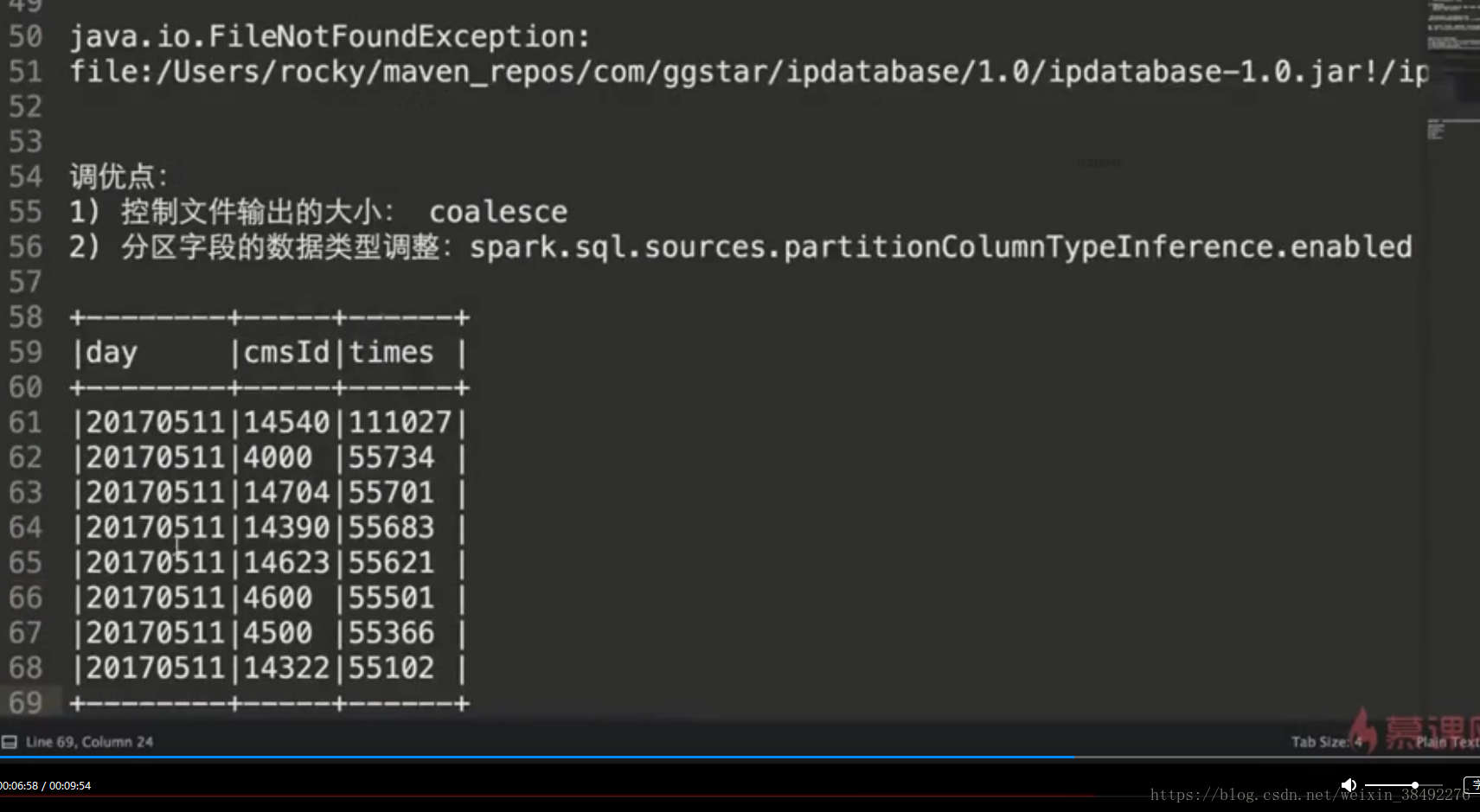
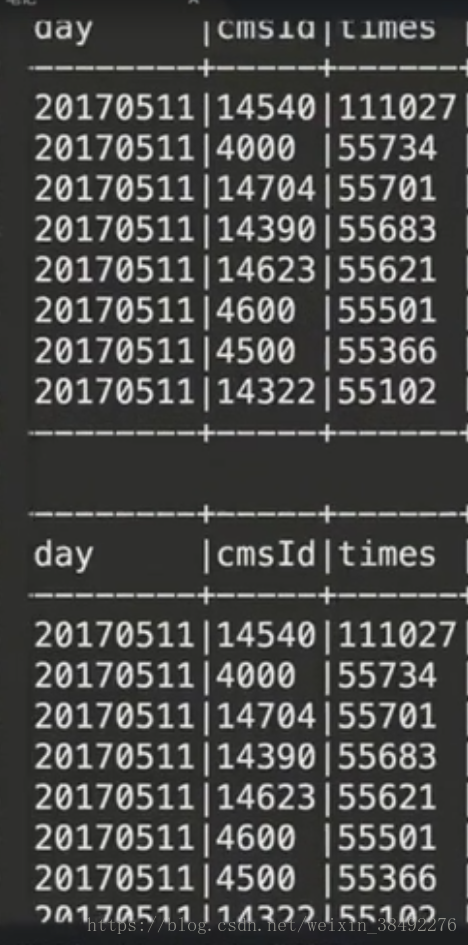
val videoAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","cmsId").agg(count("cmsId").as("times")).orderBy($"times".desc)
videoAccessTopNDF.show(false)
/**
* 使用SQL的方式進行統計
*/
// accessDF.createOrReplaceTempView("access_logs")
// val videoAccessTopNDF = spark.sql("select day,cmsId, count(1) as times from access_logs " +
// "where day='20170511' and cmsType='video' " +
// "group by day,cmsId order by times desc")
//
// videoAccessTopNDF.show(false)
/**
* 將統計結果寫入到MySQL中
*/
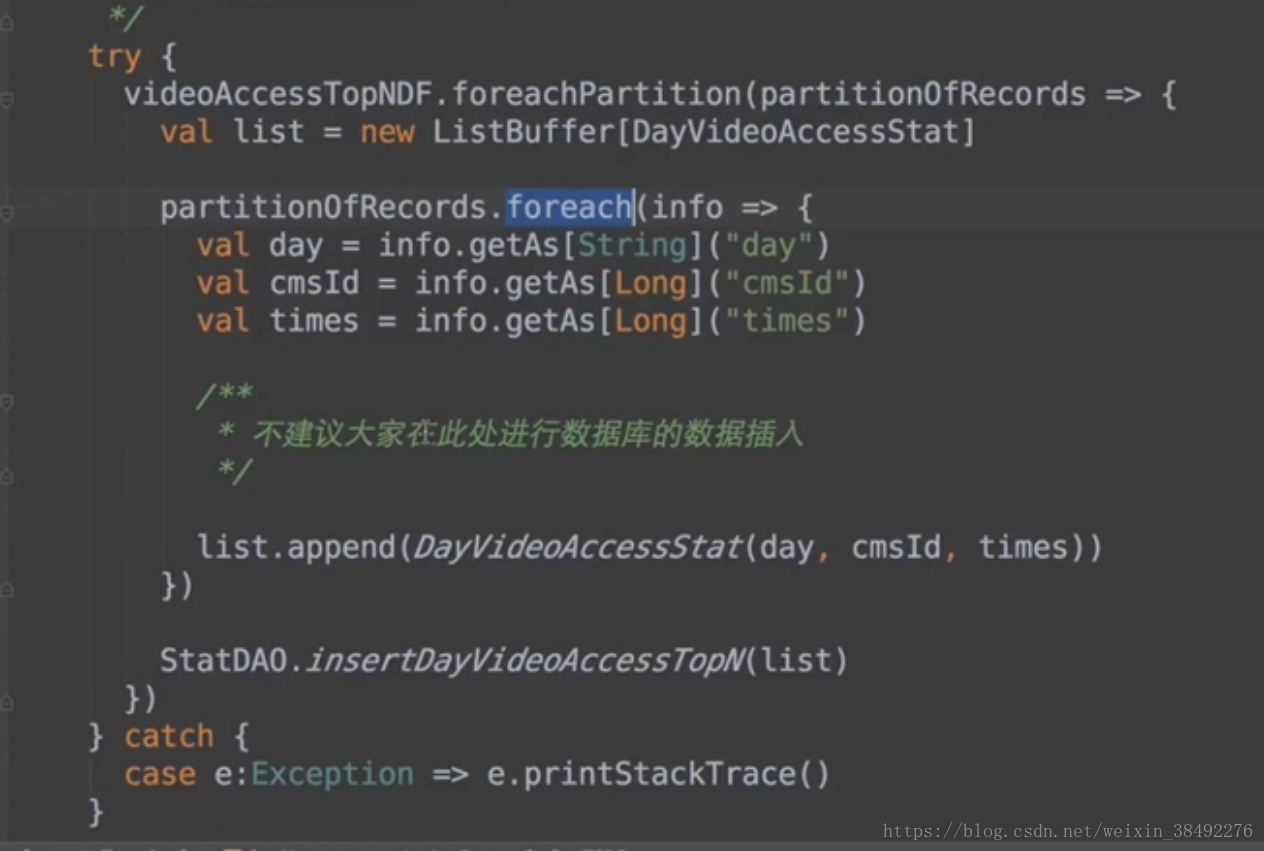
try {
videoAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val times = info.getAs[Long]("times")
/**
* 不建議大家在此處進行資料庫的資料插入
*/
list.append(DayVideoAccessStat(day, cmsId, times))
})
StatDAO.insertDayVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
}
9-12 -Scala操作MySQL工具類開發
原始碼地址:
package com.imooc.log
import java.sql.{Connection, PreparedStatement, DriverManager}
/**
* MySQL操作工具類
*/
object MySQLUtils {
/**
* 獲取資料庫連線
*/
def getConnection() = {
DriverManager.getConnection("jdbc:mysql://localhost:3306/imooc_project?user=root&password=root")
}
/**
* 釋放資料庫連線等資源
* @param connection
* @param pstmt
*/
def release(connection: Connection, pstmt: PreparedStatement): Unit = {
try {
if (pstmt != null) {
pstmt.close()
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (connection != null) {
connection.close()
}
}
}
def main(args: Array[String]) {
println(getConnection())
}
}
9-13 -需求一統計結果寫入到MySQL
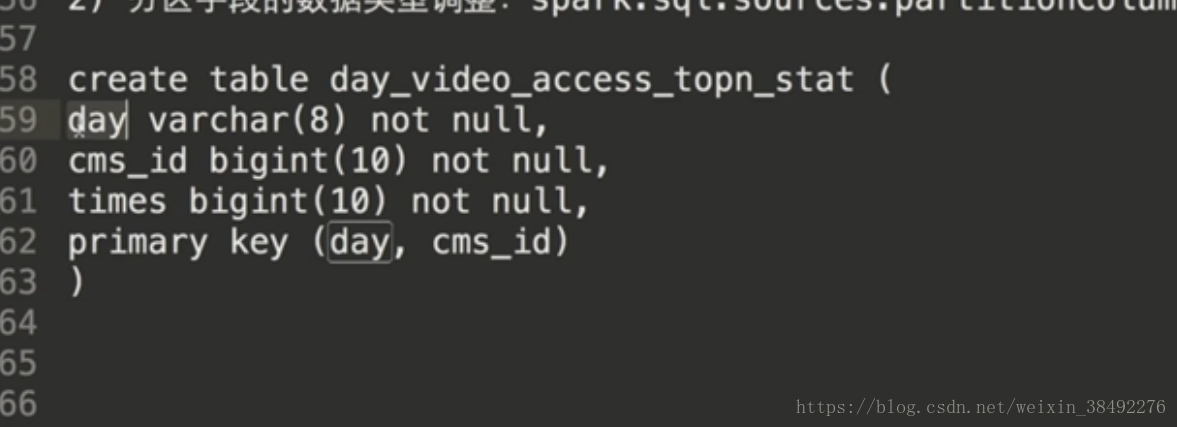
第一步:建立表
第二步:建立model
package com.imooc.log
/**
* 每天課程訪問次數實體類
*/
case class DayVideoAccessStat(day: String, cmsId: Long, times: Long)
第三步:開發Dao層
批量插入資料庫資料,提交使用batch操作
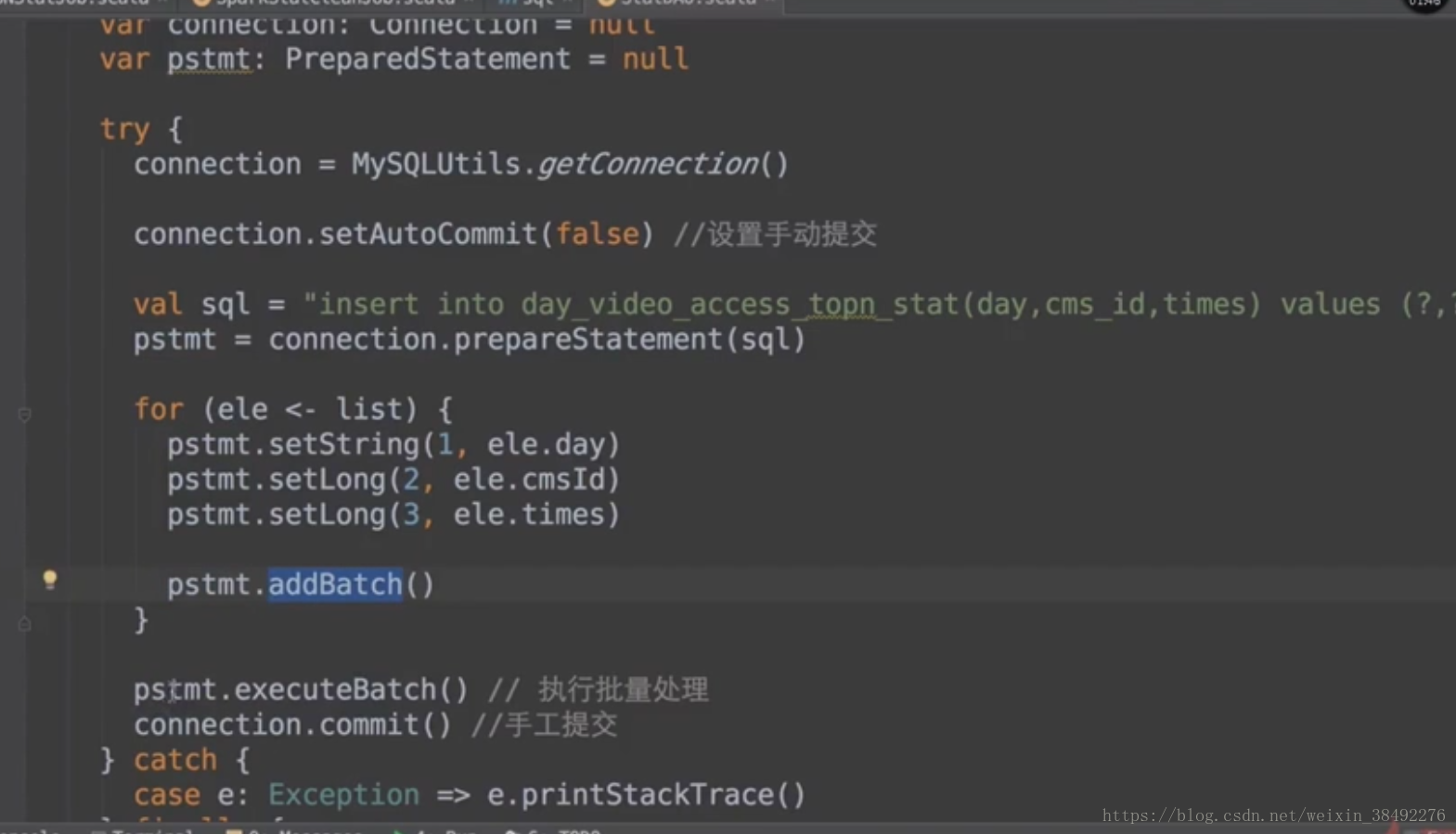
def insertDayVideoAccessTopN(list: ListBuffer[DayVideoAccessStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //設定手動提交
val sql = "insert into day_video_access_topn_stat(day,cms_id,times) values (?,?,?) "
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setLong(3, ele.times)
pstmt.addBatch()
}
pstmt.executeBatch() // 執行批量處理
connection.commit() //手工提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}
第四步:寫入資料
/**
* 將統計結果寫入到MySQL中
*/
try {
videoAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val times = info.getAs[Long]("times")
/**
* 不建議大家在此處進行資料庫的資料插入
*/
list.append(DayVideoAccessStat(day, cmsId, times))
})
StatDAO.insertDayVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
9-14 -需求二統計功能實現
//按照地市進行統計TopN課程
cityAccessTopNStat(spark, accessDF, day)
/**
* 按照地市進行統計TopN課程
*/
def cityAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","city","cmsId")
.agg(count("cmsId").as("times"))
//cityAccessTopNDF.show(false)
//Window函式在Spark SQL的使用
val top3DF = cityAccessTopNDF.select(
cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)
).as("times_rank")
).filter("times_rank <=3") //.show(false) //Top3
}
9-15 -需求二統計結果寫入到MySQL
第一步:建立表
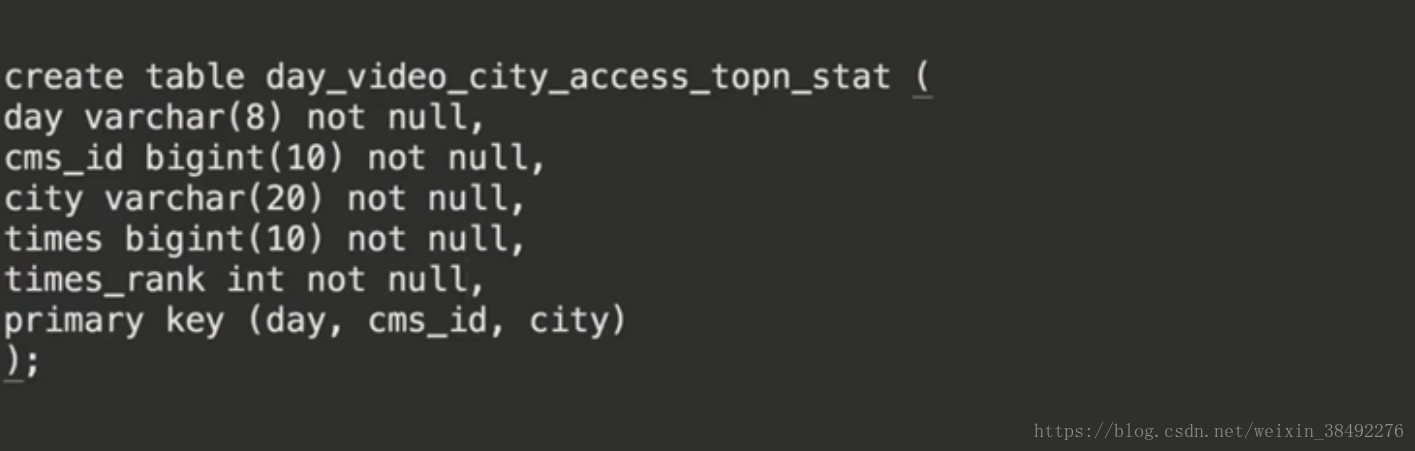
第二步:建立model
package com.imooc.log
case class DayCityVideoAccessStat(day:String, cmsId:Long, city:String,times:Long,timesRank:Int)
第三步:開發Dao層
/**
* 批量儲存DayCityVideoAccessStat到資料庫
*/
def insertDayCityVideoAccessTopN(list: ListBuffer[DayCityVideoAccessStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //設定手動提交
val sql = "insert into day_video_city_access_topn_stat(day,cms_id,city,times,times_rank) values (?,?,?,?,?) "
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setString(3, ele.city)
pstmt.setLong(4, ele.times)
pstmt.setInt(5, ele.timesRank)
pstmt.addBatch()
}
pstmt.executeBatch() // 執行批量處理
connection.commit() //手工提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}
第四步:寫入資料
try {
top3DF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayCityVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
val times = info.getAs[Long]("times")
val timesRank = info.getAs[Int]("times_rank")
list.append(DayCityVideoAccessStat(day, cmsId, city, times, timesRank))
})
StatDAO.insertDayCityVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
9-16 -需求三統計功能實現
//按照流量進行統計
videoTrafficsTopNStat(spark, accessDF, day)
/**
* 按照流量進行統計
*/
def videoTrafficsTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","cmsId").agg(sum("traffic").as("traffics"))
.orderBy($"traffics".desc)
//.show(false)
/**
* 將統計結果寫入到MySQL中
*/
try {
cityAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoTrafficsStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val traffics = info.getAs[Long]("traffics")
list.append(DayVideoTrafficsStat(day, cmsId,traffics))
})
StatDAO.insertDayVideoTrafficsAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
9-17 -需求三統計結果寫入到MySQL
第一步:建立表
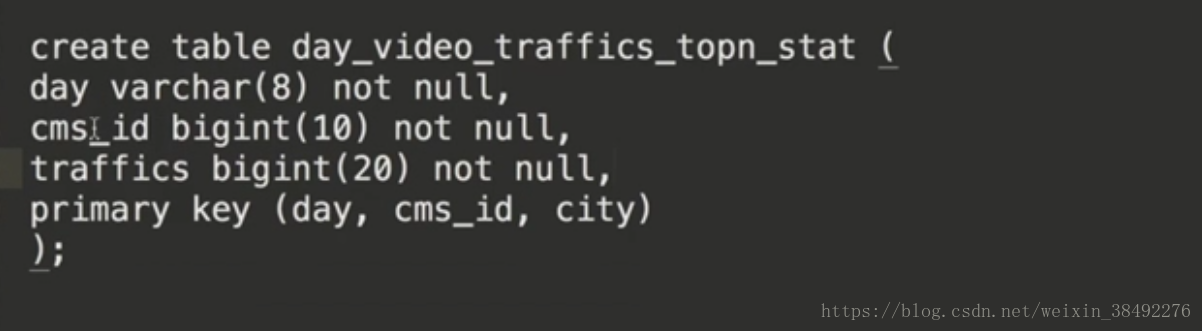
第二步:建立model
package com.imooc.log
case class DayVideoTrafficsStat(day:String,cmsId:Long,traffics:Long)
第三步:開發Dao層
/**
* 批量儲存DayVideoTrafficsStat到資料庫
*/
def insertDayVideoTrafficsAccessTopN(list: ListBuffer[DayVideoTrafficsStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //設定手動提交
val sql = "insert into day_video_traffics_topn_stat(day,cms_id,traffics) values (?,?,?) "
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setLong(3, ele.traffics)
pstmt.addBatch()
}
pstmt.executeBatch() // 執行批量處理
connection.commit() //手工提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}
第四步:寫入資料
/**
* 將統計結果寫入到MySQL中
*/
try {
cityAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoTrafficsStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val traffics = info.getAs[Long]("traffics")
list.append(DayVideoTrafficsStat(day, cmsId,traffics))
})
StatDAO.insertDayVideoTrafficsAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
9-18 -程式碼重構之刪除指定日期已有的資料
StatDAO.deleteData(day)
/**
* 刪除指定日期的資料
*/
def deleteData(day: String): Unit = {
val tables = Array("day_video_access_topn_stat",
"day_video_city_access_topn_stat",
"day_video_traffics_topn_stat")
var connection:Connection = null
var pstmt:PreparedStatement = null
try{
connection = MySQLUtils.getConnection()
for(table <- tables) {
// delete from table ....
val deleteSQL = s"delete from $table where day = ?"
pstmt = connection.prepareStatement(deleteSQL)
pstmt.setString(1, day)
pstmt.executeUpdate()
}
}catch {
case e:Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}
object TopNStatJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("TopNStatJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false")
.master("local[2]").getOrCreate()
val accessDF = spark.read.format("parquet").load("/Users/rocky/data/imooc/clean")
// accessDF.printSchema()
// accessDF.show(false)
val day = "20170511"
StatDAO.deleteData(day)
//最受歡迎的TopN課程
videoAccessTopNStat(spark, accessDF, day)
//按照地市進行統計TopN課程
cityAccessTopNStat(spark, accessDF, day)
//按照流量進行統計
videoTrafficsTopNStat(spark, accessDF, day)
spark.stop()
}
9-19 -功能實現之資料視覺化展示概述

資料視覺化:一副圖片最偉大的價值莫過於它能使我們實際看到的比我們期望看到的內容更加豐富
常見的視覺化框架
1)echarts
2)highcharts
3)D3.JS
4)HUE
5)zeppelin
9-20 -ECharts餅圖靜態資料展示
原始碼地址:
9-21 -ECharts餅圖動態展示之一查詢MySQL中的資料
原始碼地址:
9-22 -ECharts餅圖動態展示之二前端開發
原始碼地址:
9-23 -使用Zeppelin進行統計結果的展示
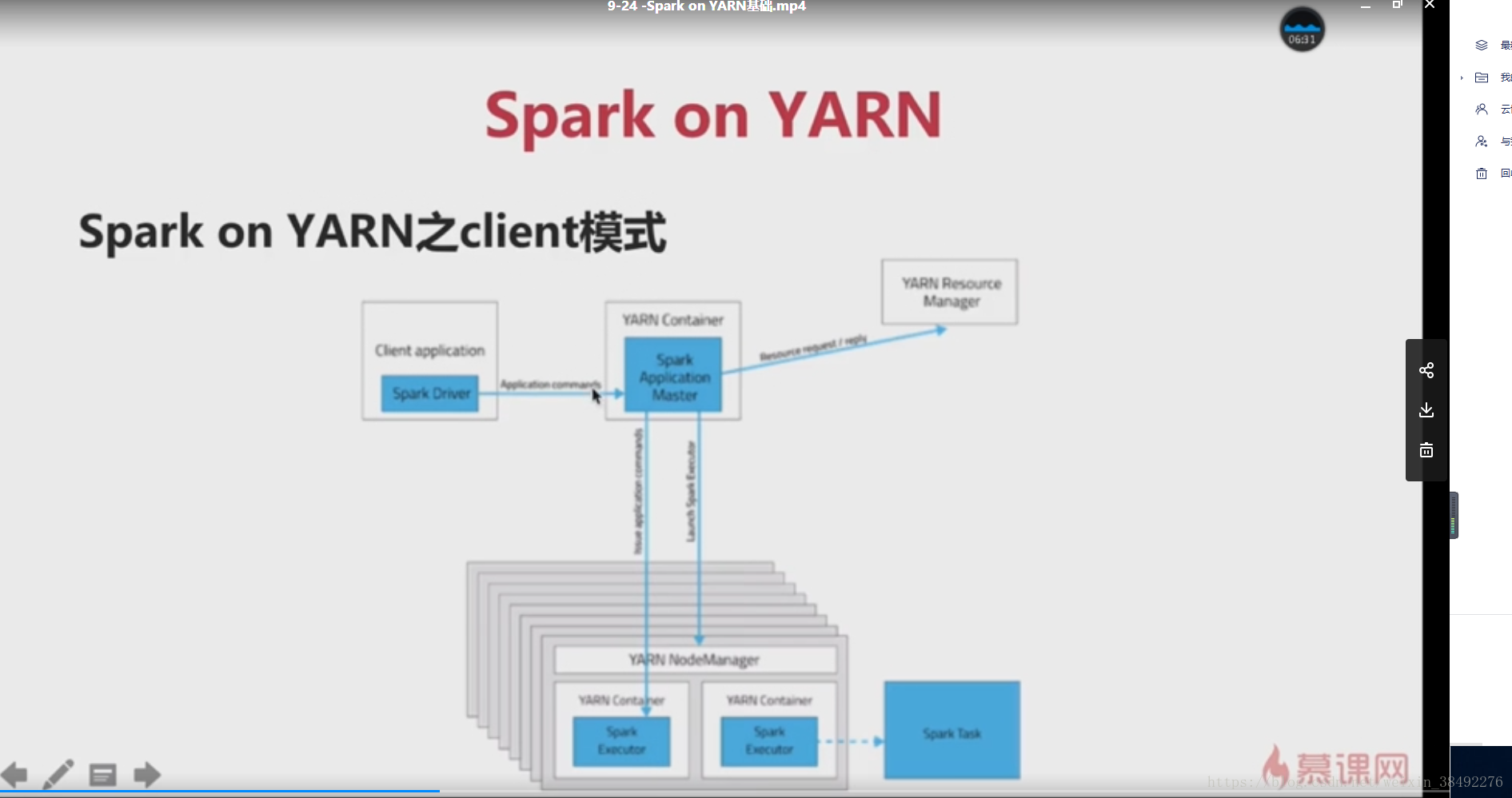
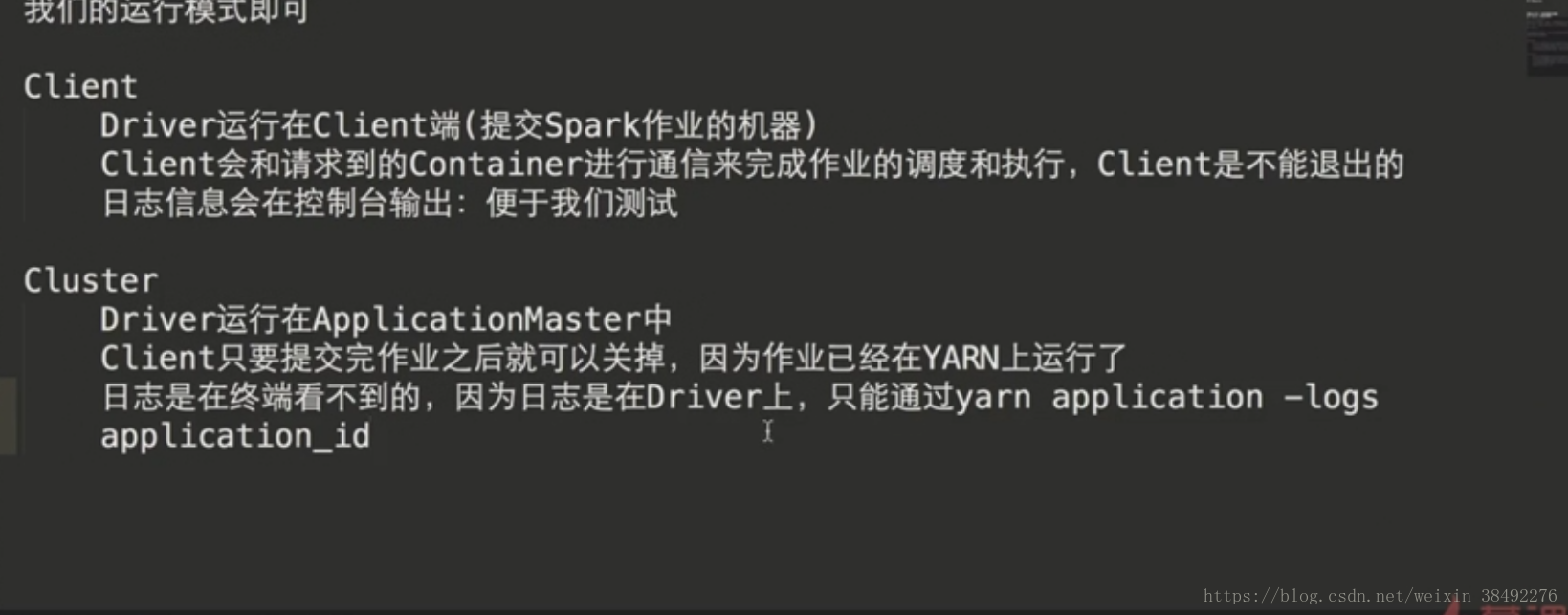
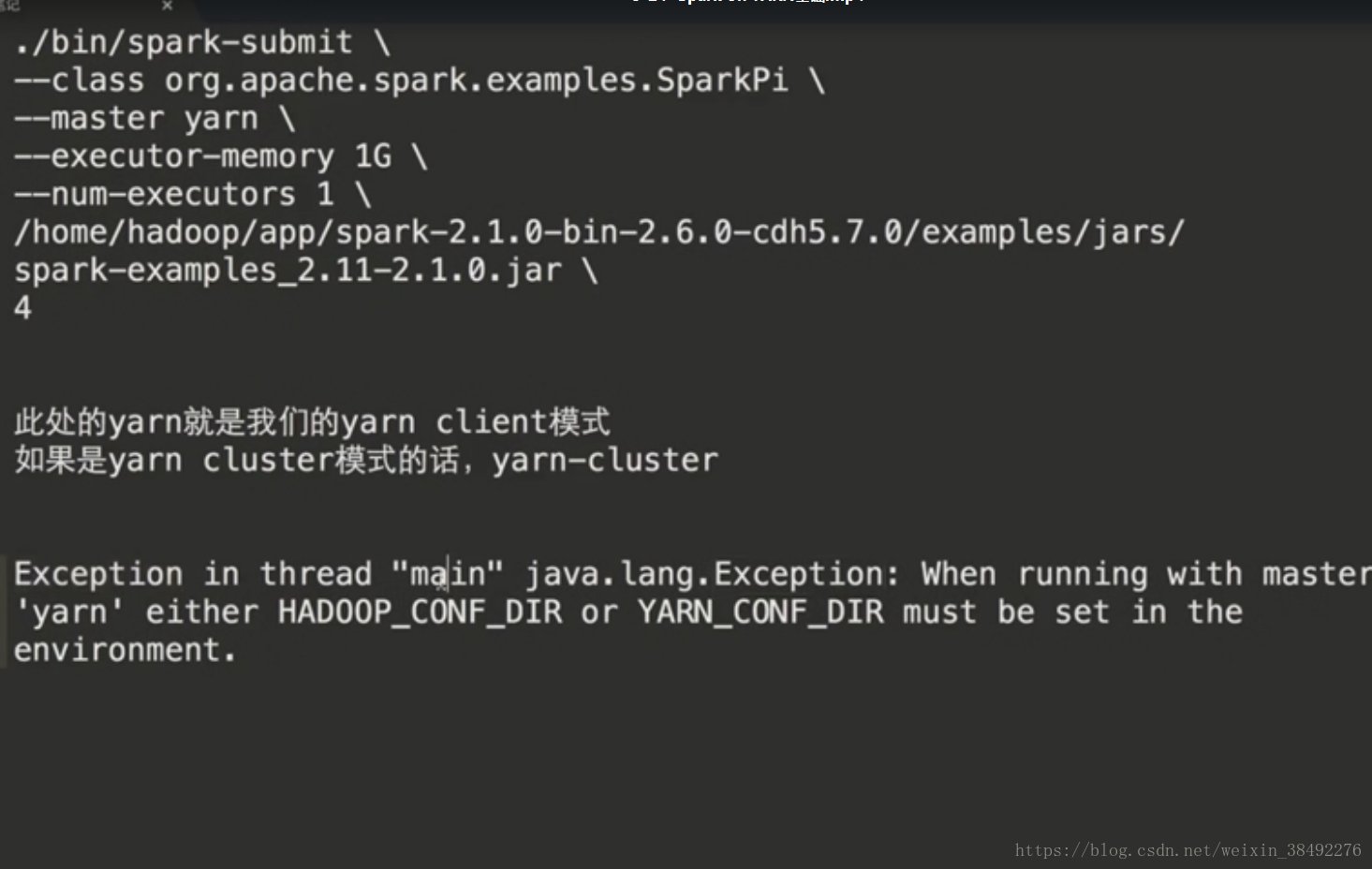
9-24 -Spark on YARN基礎
在spark中,支援4種執行模式
1)local :開發時使用
2)Standalone是spark自帶的,如果叢集是Standalone的話,那麼就需要在多臺機器上同時部署spark環境
3)YARN:建議大家在生產使用該模式,統一使用yarn進行叢集作業(MR、spark)資源排程。
4)Mesos
不管使用什麼模式,程式碼都是一樣



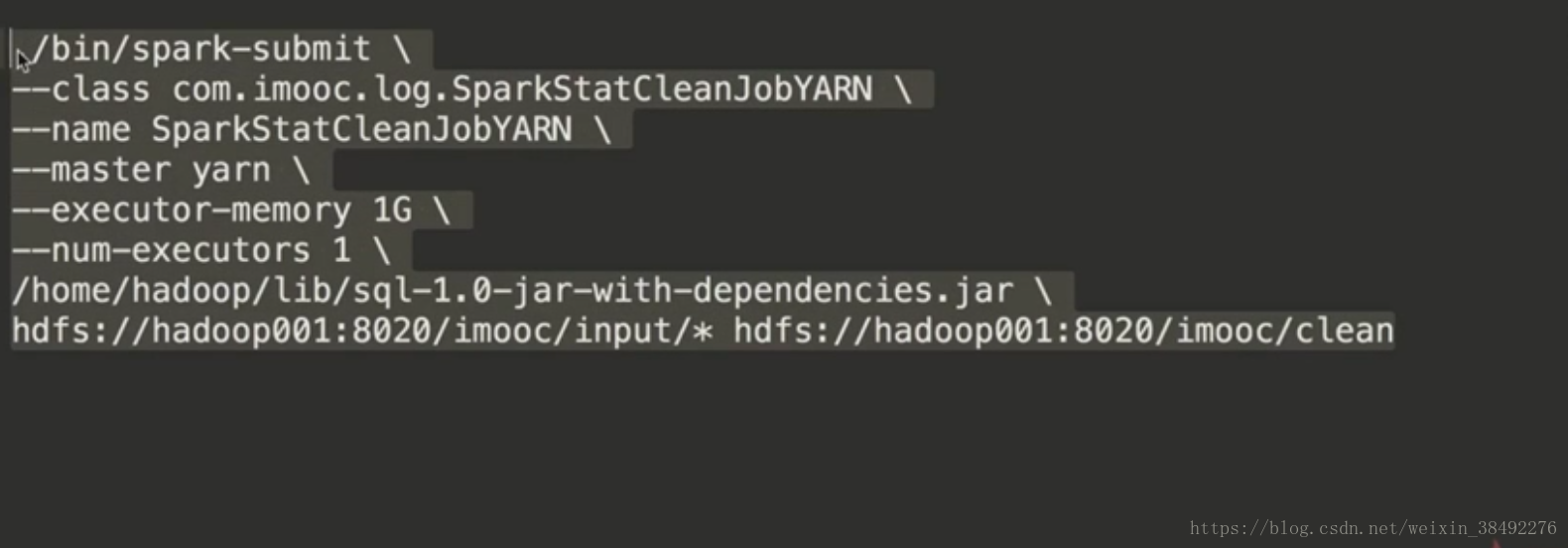
9-25 -資料清洗作業執行到YARN上

9-26 -統計作業執行在YARN上
程式碼地址:
程式碼:
package com.imooc.log
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* 使用Spark完成我們的資料清洗操作:執行在YARN之上
*/
object SparkStatCleanJobYARN {
def main(args: Array[String]) {
if(args.length !=2) {
println("Usage: SparkStatCleanJobYARN <inputPath> <outputPath>")
System.exit(1)
}
val Array(inputPath, outputPath) = args
val spark = SparkSession.builder().getOrCreate()
val accessRDD = spark.sparkContext.textFile(inputPath)
//RDD ==> DF
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct)
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save(outputPath)
spark.stop
}
}
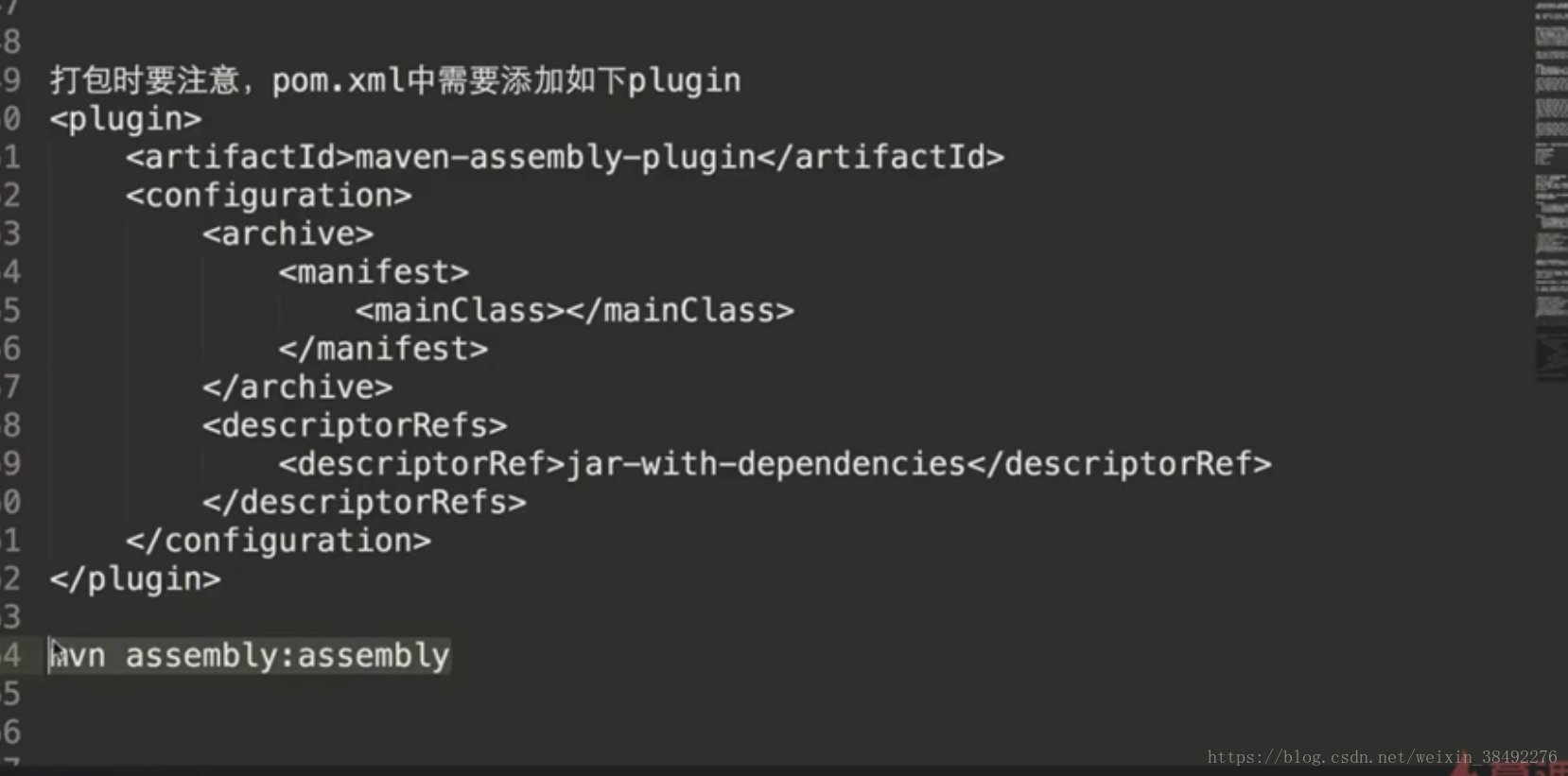
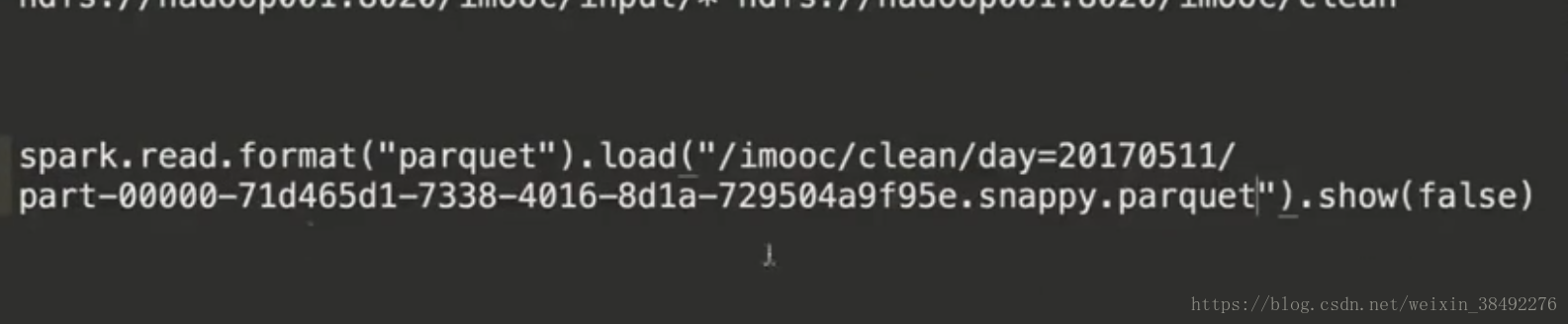
9-27 -效能優化之儲存格式的選擇

accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite) .partitionBy("day").save(outputPath)
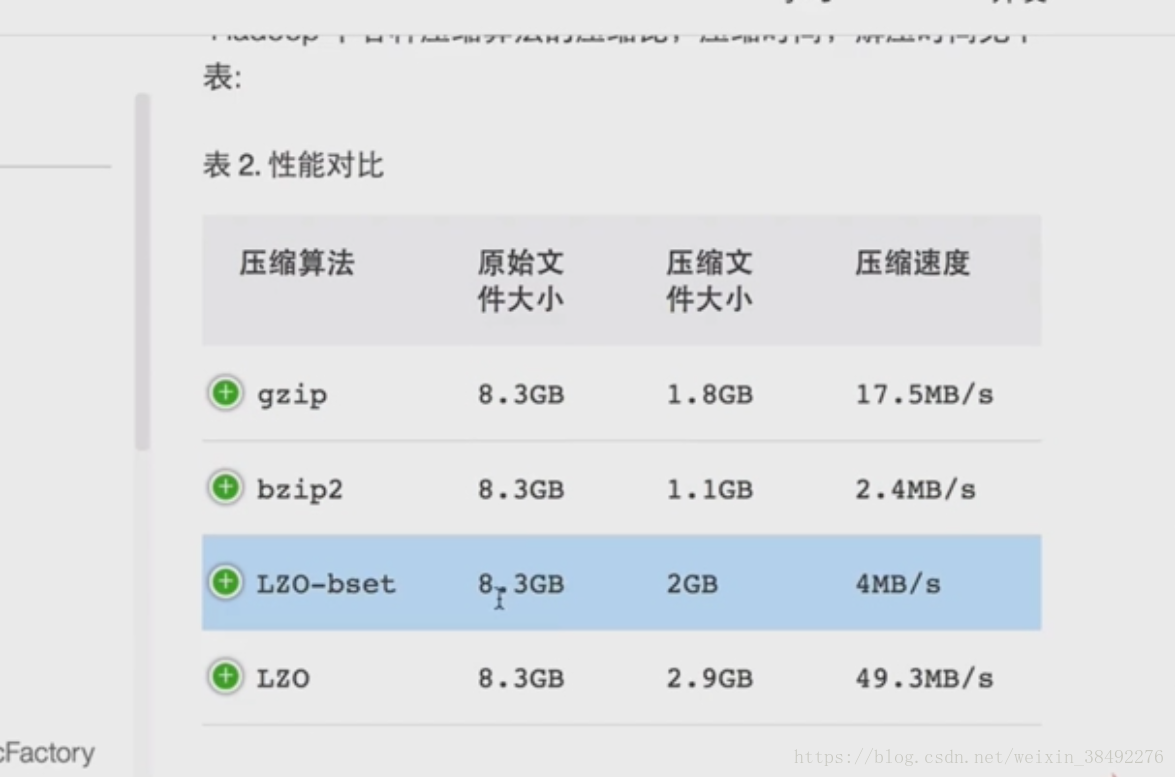
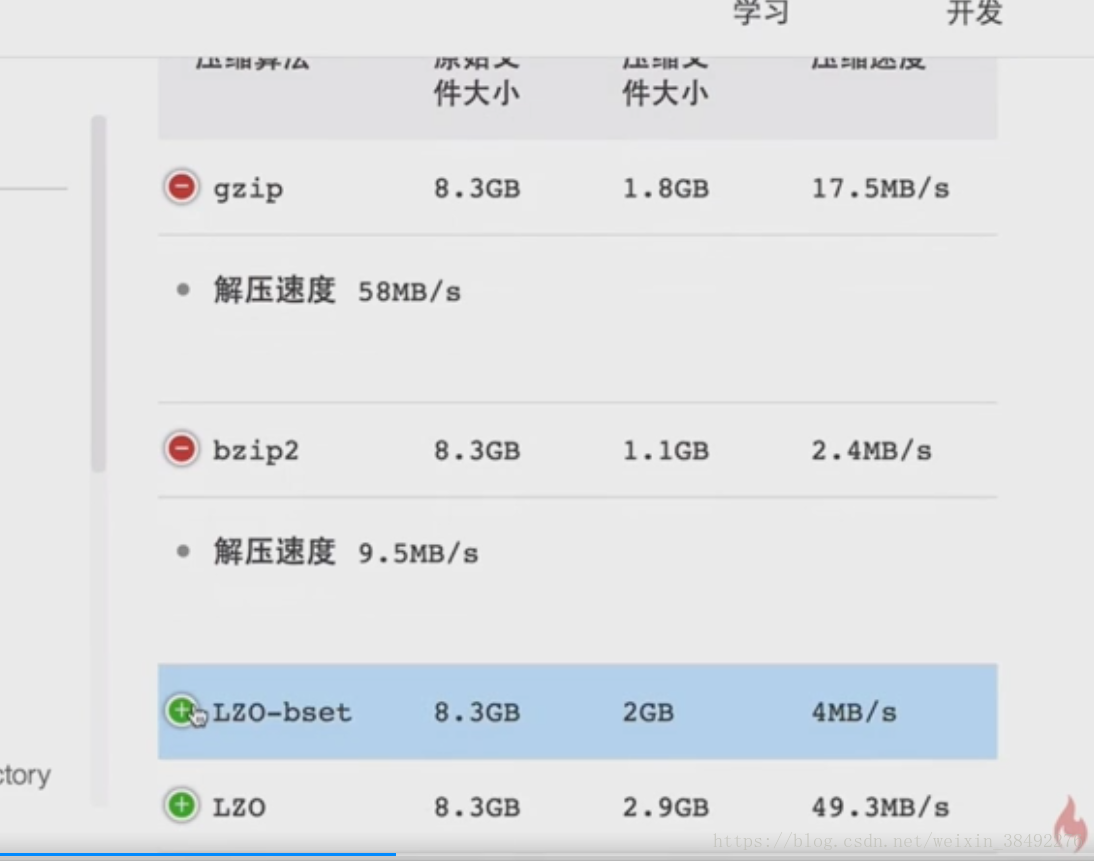
9-28 -效能調優之壓縮格式的選擇

9-29 -效能優化之程式碼優化
原始碼:
package com.imooc.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
/**
* TopN統計Spark作業:複用已有的資料
*/
object TopNStatJob2 {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("TopNStatJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false")
.master("local[2]").getOrCreate()
val accessDF = spark.read.format("parquet").load("/Users/rocky/data/imooc/clean")
// accessDF.printSchema()
// accessDF.show(false)
val day = "20170511"
import spark.implicits._
val commonDF = accessDF.filter($"day" === day && $"cmsType" === "video")
commonDF.cache()
StatDAO.deleteData(day)
//最受歡迎的TopN課程
videoAccessTopNStat(spark, commonDF)
//按照地市進行統計TopN課程
cityAccessTopNStat(spark, commonDF)
//按照流量進行統計
videoTrafficsTopNStat(spark, commonDF)
commonDF.unpersist(true)
spark.stop()
}
/**
* 按照流量進行統計
*/
def videoTrafficsTopNStat(spark: SparkSession, commonDF:DataFrame): Unit = {
import spark.implicits._
val cityAccessTopNDF = commonDF.groupBy("day","cmsId")
.agg(sum("traffic").as("traffics"))
.orderBy($"traffics".desc)
//.show(false)
/**
* 將統計結果寫入到MySQL中
*/
try {
cityAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoTrafficsStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val traffics = info.getAs[Long]("traffics")
list.append(DayVideoTrafficsStat(day, cmsId,traffics))
})
StatDAO.insertDayVideoTrafficsAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
/**
* 按照地市進行統計TopN課程
*/
def cityAccessTopNStat(spark: SparkSession, commonDF:DataFrame): Unit = {
val cityAccessTopNDF = commonDF
.groupBy("day","city","cmsId")
.agg(count("cmsId").as("times"))
//cityAccessTopNDF.show(false)
//Window函式在Spark SQL的使用
val top3DF = cityAccessTopNDF.select(
cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)
).as("times_rank")
).filter("times_rank <=3") //.show(false) //Top3
/**
* 將統計結果寫入到MySQL中
*/
try {
top3DF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayCityVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
val times = info.getAs[Long]("times")
val timesRank = info.getAs[Int]("times_rank")
list.append(DayCityVideoAccessStat(day, cmsId, city, times, timesRank))
})
StatDAO.insertDayCityVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
/**
* 最受歡迎的TopN課程
*/
def videoAccessTopNStat(spark: SparkSession, commonDF:DataFrame): Unit = {
/**
* 使用DataFrame的方式進行統計
*/
import spark.implicits._
val videoAccessTopNDF = commonDF
.groupBy("day","cmsId").agg(count("cmsId").as("times")).orderBy($"times".desc)
videoAccessTopNDF.show(false)
/**
* 使用SQL的方式進行統計
*/
// accessDF.createOrReplaceTempView("access_logs")
// val videoAccessTopNDF = spark.sql("select day,cmsId, count(1) as times from access_logs " +
// "where day='20170511' and cmsType='video' " +
// "group by day,cmsId order by times desc")
//
// videoAccessTopNDF.show(false)
/**
* 將統計結果寫入到MySQL中
*/
try {
videoAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val times = info.getAs[Long]("times")
/**
* 不建議大家在此處進行資料庫的資料插入
*/
list.append(DayVideoAccessStat(day, cmsId, times))
})
StatDAO.insertDayVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
}
9-30 -效能調優之引數優化



val spark = SparkSession.builder().appName("TopNStatJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false")