
YOLO_Online 將深度學習最火的目標檢測做成線上服務實戰經驗分享
部分 YOLO 結果:
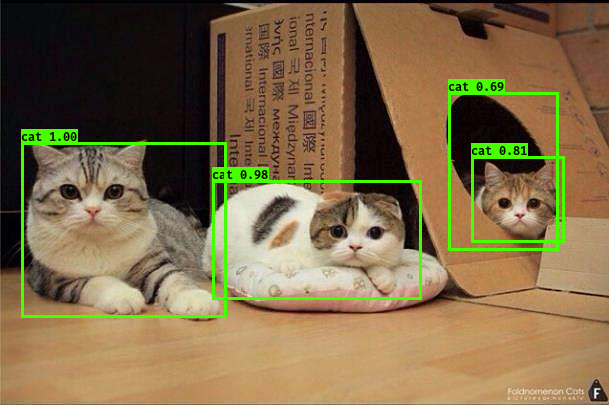


YOLO_Online 將深度學習最火的目標檢測做成線上服務
第一次接觸 YOLO 這個目標檢測專案的時候,我就在想,怎麼樣能夠封裝一下讓普通人也能夠體驗深度學習最火的目標檢測專案,不需要關注技術細節,不需要裝很多軟體。只需要網頁就能體驗呢。
在踩了很多坑之後,終於實現了。
效果:

1.上傳檔案
2.選擇了一張很多狗的圖片

3.YOLO 一下

技術實現
- web 用了 Django 來做介面,就是上傳檔案,儲存檔案這個功能。
- YOLO 的實現用的是 keras-yolo3,直接匯入yolo 官方的權重即可。
- YOLO 和 web 的互動最後使用的是 socket。
坑1:
Django 中 Keras 初始化會有 bug,原計劃是直接在 Django 裡面用 keras,後來發現坑實在是太深了。
最後 Django 是負責拿檔案,然後用 socket 把檔名傳給 yolo。
坑2:
說好的線上服務,為什麼沒有上線呢?買了騰訊雲 1 CPU 2 G 記憶體,部署的時候發現 keras 根本起不來,直接被 Killed 。

解決,並沒有解決,因為買不起更好地伺服器了,只好本地執行然後截圖了。
坑3:
YOLO 的識別是需要一定的時間的,做成 web 的服務,上傳完檔案之後,並不能馬上識別出來,有一定的延遲。
相關教程:
TensorFlow + Keras 實戰 YOLO v3 目標檢測圖文並茂教程
YOLO QQ 群
群號:167122861
計算機視覺專案合作微信:voicer008
awesome-object-detection
Awesome Object Detection based on handong1587 github(https://handong1587.github.io/deep_learning/2015/10/09/object-detection.html)
Papers&Codes
R-CNN
Rich feature hierarchies for accurate object detection and semantic segmentation
Fast R-CNN
Fast R-CNN
A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
Faster R-CNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
R-CNN minus R
Faster R-CNN in MXNet with distributed implementation and data parallelization
Contextual Priming and Feedback for Faster R-CNN
An Implementation of Faster RCNN with Study for Region Sampling
Interpretable R-CNN
- intro: North Carolina State University & Alibaba
- keywords: AND-OR Graph (AOG)
Light-Head R-CNN
Light-Head R-CNN: In Defense of Two-Stage Object Detector
Cascade R-CNN
Cascade R-CNN: Delving into High Quality Object Detection
SPP-Net
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection
Object Detectors Emerge in Deep Scene CNNs
segDeepM: Exploiting Segmentation and Context in Deep Neural Networks for Object Detection
Object Detection Networks on Convolutional Feature Maps
Improving Object Detection with Deep Convolutional Networks via Bayesian Optimization and Structured Prediction
DeepBox: Learning Objectness with Convolutional Networks
YOLO
You Only Look Once: Unified, Real-Time Object Detection
darkflow – translate darknet to tensorflow. Load trained weights, retrain/fine-tune them using tensorflow, export constant graph def to C++
Start Training YOLO with Our Own Data
YOLO: Core ML versus MPSNNGraph
TensorFlow YOLO object detection on Android
- intro: Real-time object detection on Android using the YOLO network with TensorFlow
Computer Vision in iOS – Object Detection
YOLOv2
YOLO9000: Better, Faster, Stronger
darknet_scripts
- intro: Auxilary scripts to work with (YOLO) darknet deep learning famework. AKA -> How to generate YOLO anchors?
Yolo_mark: GUI for marking bounded boxes of objects in images for training Yolo v2
LightNet: Bringing pjreddie’s DarkNet out of the shadows
YOLO v2 Bounding Box Tool
- intro: Bounding box labeler tool to generate the training data in the format YOLO v2 requires.
Loss Rank Mining: A General Hard Example Mining Method for Real-time Detectors
- intro: LRM is the first hard example mining strategy which could fit YOLOv2 perfectly and make it better applied in series of real scenarios where both real-time rates and accurate detection are strongly demanded.
-
arxiv: https://arxiv.org/abs/1804.04606
YOLOv3
YOLOv3: An Incremental Improvement
- arxiv:https://arxiv.org/abs/1804.02767
- paper:https://pjreddie.com/media/files/papers/YOLOv3.pdf
- github(Official):https://github.com/pjreddie/darknet
- github:https://github.com/experiencor/keras-yolo3
- github:https://github.com/qqwweee/keras-yolo3
- github:https://github.com/marvis/pytorch-yolo3
- github:https://github.com/ayooshkathuria/pytorch-yolo-v3
- github:https://github.com/ayooshkathuria/YOLO_v3_tutorial_from_scratch
SSD
SSD: Single Shot MultiBox Detector
What’s the diffience in performance between this new code you pushed and the previous code? #327
DSSD
DSSD : Deconvolutional Single Shot Detector
Enhancement of SSD by concatenating feature maps for object detection
Context-aware Single-Shot Detector
- keywords: CSSD, DiCSSD, DeCSSD, effective receptive fields (ERFs), theoretical receptive fields (TRFs)
Feature-Fused SSD: Fast Detection for Small Objects
FSSD
FSSD: Feature Fusion Single Shot Multibox Detector
Weaving Multi-scale Context for Single Shot Detector
- intro: WeaveNet
- keywords: fuse multi-scale information
ESSD
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection
Pelee
Pelee: A Real-Time Object Detection System on Mobile Devices
https://github.com/Robert-JunWang/Pelee
- intro: (ICLR 2018 workshop track)
-
arxiv: https://arxiv.org/abs/1804.06882
- github: https://github.com/Robert-JunWang/Pelee
R-FCN
R-FCN: Object Detection via Region-based Fully Convolutional Networks
R-FCN-3000 at 30fps: Decoupling Detection and Classification
Recycle deep features for better object detection
FPN
Feature Pyramid Networks for Object Detection
Action-Driven Object Detection with Top-Down Visual Attentions
Beyond Skip Connections: Top-Down Modulation for Object Detection
Wide-Residual-Inception Networks for Real-time Object Detection
Attentional Network for Visual Object Detection
- intro: University of Maryland & Mitsubishi Electric Research Laboratories
Learning Chained Deep Features and Classifiers for Cascade in Object Detection
- keykwords: CC-Net
- intro: chained cascade network (CC-Net). 81.1% mAP on PASCAL VOC 2007
DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling
Discriminative Bimodal Networks for Visual Localization and Detection with Natural Language Queries
Spatial Memory for Context Reasoning in Object Detection
Accurate Single Stage Detector Using Recurrent Rolling Convolution
Deep Occlusion Reasoning for Multi-Camera Multi-Target Detection
LCDet: Low-Complexity Fully-Convolutional Neural Networks for Object Detection in Embedded Systems
- intro: Embedded Vision Workshop in CVPR. UC San Diego & Qualcomm Inc
Point Linking Network for Object Detection
Perceptual Generative Adversarial Networks for Small Object Detection
Few-shot Object Detection
Yes-Net: An effective Detector Based on Global Information
SMC Faster R-CNN: Toward a scene-specialized multi-object detector
Towards lightweight convolutional neural networks for object detection
RON: Reverse Connection with Objectness Prior Networks for Object Detection
Mimicking Very Efficient Network for Object Detection
Residual Features and Unified Prediction Network for Single Stage Detection
Deformable Part-based Fully Convolutional Network for Object Detection
- intro: BMVC 2017 (oral). Sorbonne Universités & CEDRIC
Adaptive Feeding: Achieving Fast and Accurate Detections by Adaptively Combining Object Detectors
Recurrent Scale Approximation for Object Detection in CNN
DSOD
DSOD: Learning Deeply Supervised Object Detectors from Scratch

- intro: ICCV 2017. Fudan University & Tsinghua University & Intel Labs China
- github:https://github.com/Windaway/DSOD-Tensorflow
- github:https://github.com/chenyuntc/dsod.pytorch
Learning Object Detectors from Scratch with Gated Recurrent Feature Pyramids
- arxiv:https://arxiv.org/abs/1712.00886
- github:https://github.com/szq0214/GRP-DSOD
RetinaNet
Focal Loss for Dense Object Detection
- intro: ICCV 2017 Best student paper award. Facebook AI Research
- keywords: RetinaNet
CoupleNet: Coupling Global Structure with Local Parts for Object Detection
Incremental Learning of Object Detectors without Catastrophic Forgetting
Zoom Out-and-In Network with Map Attention Decision for Region Proposal and Object Detection
StairNet: Top-Down Semantic Aggregation for Accurate One Shot Detection
Dynamic Zoom-in Network for Fast Object Detection in Large Images
Zero-Annotation Object Detection with Web Knowledge Transfer
- intro: NTU, Singapore & Amazon
- keywords: multi-instance multi-label domain adaption learning framework
MegDet
MegDet: A Large Mini-Batch Object Detector
- intro: Peking University & Tsinghua University & Megvii Inc
Single-Shot Refinement Neural Network for Object Detection
Receptive Field Block Net for Accurate and Fast Object Detection
An Analysis of Scale Invariance in Object Detection – SNIP
Feature Selective Networks for Object Detection
Learning a Rotation Invariant Detector with Rotatable Bounding Box
Scalable Object Detection for Stylized Objects
Learning Object Detectors from Scratch with Gated Recurrent Feature Pyramids
Deep Regionlets for Object Detection
- keywords: region selection network, gating network
Training and Testing Object Detectors with Virtual Images
Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video
- keywords: object mining, object tracking, unsupervised object discovery by appearance-based clustering, self-supervised detector adaptation
Spot the Difference by Object Detection
Localization-Aware Active Learning for Object Detection
Object Detection with Mask-based Feature Encoding
LSTD: A Low-Shot Transfer Detector for Object Detection
Domain Adaptive Faster R-CNN for Object Detection in the Wild
Pseudo Mask Augmented Object Detection
Revisiting RCNN: On Awakening the Classification Power of Faster RCNN
Zero-Shot Detection
- intro: Australian National University
- keywords: YOLO
Learning Region Features for Object Detection
Single-Shot Bidirectional Pyramid Networks for High-Quality Object Detection
- intro: Singapore Management University & Zhejiang University
Object Detection for Comics using Manga109 Annotations
- intro: University of Tokyo & National Institute of Informatics, Japan
Task-Driven Super Resolution: Object Detection in Low-resolution Images
Transferring Common-Sense Knowledge for Object Detection
Multi-scale Location-aware Kernel Representation for Object Detection
Loss Rank Mining: A General Hard Example Mining Method for Real-time Detectors
- intro: National University of Defense Technology
Robust Physical Adversarial Attack on Faster R-CNN Object Detector
DetNet
DetNet: A Backbone network for Object Detection
- intro: Tsinghua University & Face++
-
arxiv: https://arxiv.org/abs/1804.06215
Other
Relation Network for Object Detection
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1711.11575
Quantization Mimic: Towards Very Tiny CNN for Object Detection
- Tsinghua University1 & The Chinese University of Hong Kong2 &SenseTime3
-
arxiv: https://arxiv.org/abs/1805.02152
專案地址:https://github.com/amusi/awesome-object-detection

4 月 30 日,谷歌在其官方部落格上發文稱將開放 Images V4 資料庫,並同時開啟 ECCV 2018 公開影象挑戰賽。雷鋒網編譯全文如下:
2016 年,我們釋出了一個包含大約 900 萬張圖片、標註了數千個物件類別標籤的資料集 Open Images。釋出之後,我們一直在努力更新和改進資料集,以便為計算機視覺社群提供有用的資源來開發新模型。
今天,我們很高興地宣佈開放 Open Images V4,它包含在 190 萬張圖片上針對 600 個類別的 1540 萬個邊框盒,這也是現有最大的具有物件位置註釋的資料集。這些邊框盒大部分都是由專業註釋人員手動繪製的,確保了它們的準確性和一致性。另外,這些影象是非常多樣化的,並且通常包含有多個物件的複雜場景(平均每個影象 8 個)。
與此同時,我們還將宣佈啟動 Open Images 挑戰賽,這將是在 2018 計算機視覺歐洲會議(ECCV 2018)上舉辦的一場新的物件檢測挑戰賽。Open Images 挑戰賽將遵循 PASCAL VOC、ImageNet 和 COCO 等賽事的傳統,但是其規模將是空前的。
Open Images 挑戰賽在一下這幾個方面將是獨一無二的:
有 170 萬張訓練圖片,其中有 500 個類別和 1220 萬個邊框註釋;
與以前的檢測挑戰相比,將有更廣泛的類別,包括諸如「fedora」、「snowman」等這樣的新物件;
除了主流的物體檢測外,本次挑戰賽中在檢測物體對時還將包括視覺關係檢測,例如「woman playing guitar」。
訓練資料集現在已經可以使用;一個包含有 10 萬張圖片的測試集將於 2018 年 7 月 1 日釋出在 Kaggle 上。挑戰賽提交結果的截止日期為 2018 年 9 月 1 日。
我們希望更大的訓練集能夠刺激對更復雜檢測模型的研究,這些模型將超過當前 state-of-the-art 的效能;而從另一方面,我們希望 500 個類別能夠更精確地評估不同探測器在哪些方面表現的更好。此外,擁有大量帶有多個物件標註的影象,可以幫組你探索視覺關係檢測,這還是一個熱門的新興話題,而且具有越來越多的子社群。
除了上述內容外,Open Images V4 還包含了 3010 萬張經過人工驗證的針對 19794 個類別影象級標籤的圖片。當然這些標籤不屬於挑戰賽的一部分,其中的 550 萬張影象級標籤是由來自世界各地成千上萬名使用者通過 crowdsource.google.com 生成的。
原文連結:https://www.leiphone.com/news/201805/AlOdBu0uXZY0ZVT9.html

執行步驟
1.從 YOLO 官網下載 YOLOv3 權重
wget https://pjreddie.com/media/files/yolov3.weights
下載過程如圖:

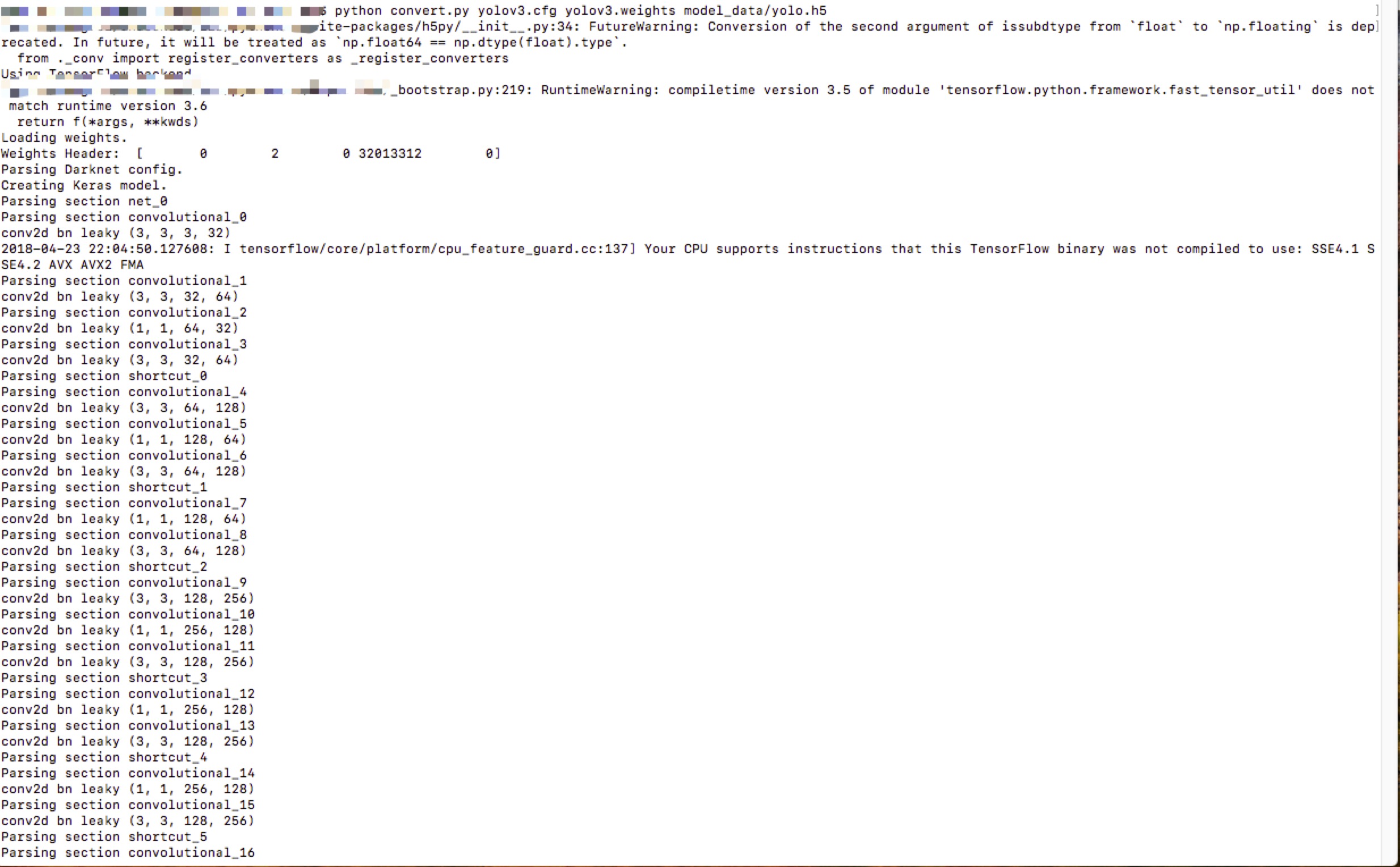
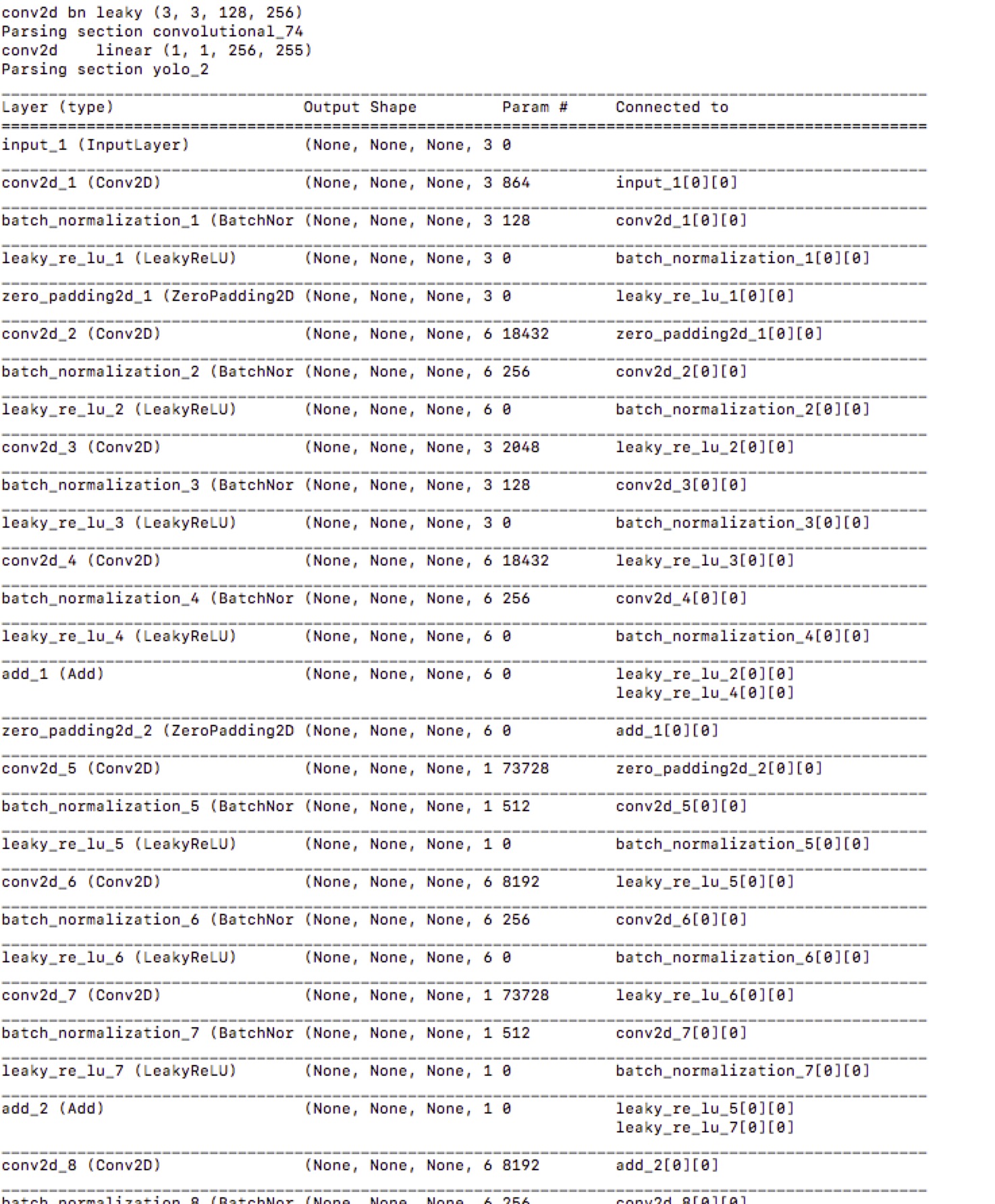
2.轉換 Darknet YOLO 模型為 Keras 模型
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
轉換過程如圖:
3.執行YOLO 目標檢測
python yolo.py
需要下載一個圖片,然後輸入圖片的名稱,如圖所示:

我並沒有使用經典的那張圖,隨便從網上找了一個,來源見圖片水印:

識別效果:
專案地址:https://github.com/qqwweee/keras-yolo3
教程來自:http://objectdetection.cn/

Mask R-CNN for Object Detection and Segmentation
這是一個基於 Python 3, Keras, TensorFlow 實現的 Mask R-CNN。這個模型為影象中的每個物件例項生成邊界框和分割掩碼。它基於 Feature Pyramid Network (FPN) and a ResNet101 backbone.
這個專案包括包括:
在FPN和ResNet101上構建的Mask R-CNN的原始碼。
MS COCO的訓練程式碼
MS COCO 預先訓練的權重
Jupyter notebooks 來視覺化在每一個步驟的檢測管道
用於多GPU訓練的ParallelModel類
MS COCO指標評估(AP)
訓練您自己的資料集的例子
程式碼被記錄和設計為易於擴充套件。 如果您在研究中使用它,請考慮引用此專案。 如果您從事3D視覺工作,您可能會發現我們最近釋出的Matterport3D資料集也很有用。 這個資料集是由我們的客戶拍攝的三維重建空間建立的,這些客戶同意將這些資料公開供學術使用。 你可以在這裡看到更多的例子。
This is an implementation of Mask R-CNN on Python 3, Keras, and TensorFlow. The model generates bounding boxes and segmentation masks for each instance of an object in the image. It’s based on Feature Pyramid Network (FPN) and a ResNet101 backbone.
The repository includes:
- Source code of Mask R-CNN built on FPN and ResNet101.
- Training code for MS COCO
- Pre-trained weights for MS COCO
- Jupyter notebooks to visualize the detection pipeline at every step
- ParallelModel class for multi-GPU training
- Evaluation on MS COCO metrics (AP)
- Example of training on your own dataset
The code is documented and designed to be easy to extend. If you use it in your research, please consider referencing this repository. If you work on 3D vision, you might find our recently released Matterport3D dataset useful as well. This dataset was created from 3D-reconstructed spaces captured by our customers who agreed to make them publicly available for academic use. You can see more examples here.
專案地址:matterport/Mask_RCNN
https://github.com/matterport/Mask_RCNN
封面圖是作者執行圖,我在 ubuntu 環境下只有文字預測結果。
Detection Using A Pre-Trained Model
使用訓練好的模型來檢測物體
執行一下命令來下載和編譯模型
git clone https://github.com/pjreddie/darknet
cd darknet
make
執行一下模型來下載預訓練權重
wget https://pjreddie.com/media/files/yolo.weights
執行以下命令來測試模型
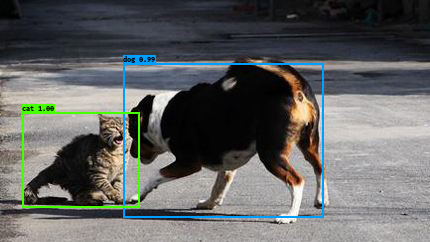
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg
最終結果截圖
英文原文
https://pjreddie.com/darknet/yolo/