
記錄第一次參加kaggle
阿新 • • 發佈:2018-12-17
第一次接觸此類比賽, 在資料的處理方面只是通過合併資料與刪除完成,對於最後的預測採用了神經網路,但是用法不熟悉仍有一些問題。僅用於記錄。
# data analysis and wrangling
import pandas as pd
import numpy as np
import random as rnd
# visualization
import seaborn as sns
import matplotlib.pyplot as plt
# machine learning
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import SGDRegressor
from sklearn.neural_network import MLPRegressor # 多層線性迴歸
from sklearn.preprocessing import StandardScaler
from ultimate.mlp import MLP
import gc
train_df=pd.read_csv('./all/train_V2.csv')
test_df=pd.read_csv('./all/test_V2.csv')
train_df.head()
| Id | groupId | matchId | assists | boosts | damageDealt | DBNOs | headshotKills | heals | killPlace | ... | revives | rideDistance | roadKills | swimDistance | teamKills | vehicleDestroys | walkDistance | weaponsAcquired | winPoints | winPlacePerc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7f96b2f878858a | 4d4b580de459be | a10357fd1a4a91 | 0 | 0 | 0.00 | 0 | 0 | 0 | 60 | ... | 0 | 0.0000 | 0 | 0.00 | 0 | 0 | 244.80 | 1 | 1466 | 0.4444 |
| 1 | eef90569b9d03c | 684d5656442f9e | aeb375fc57110c | 0 | 0 | 91.47 | 0 | 0 | 0 | 57 | ... | 0 | 0.0045 | 0 | 11.04 | 0 | 0 | 1434.00 | 5 | 0 | 0.6400 |
| 2 | 1eaf90ac73de72 | 6a4a42c3245a74 | 110163d8bb94ae | 1 | 0 | 68.00 | 0 | 0 | 0 | 47 | ... | 0 | 0.0000 | 0 | 0.00 | 0 | 0 | 161.80 | 2 | 0 | 0.7755 |
| 3 | 4616d365dd2853 | a930a9c79cd721 | f1f1f4ef412d7e | 0 | 0 | 32.90 | 0 | 0 | 0 | 75 | ... | 0 | 0.0000 | 0 | 0.00 | 0 | 0 | 202.70 | 3 | 0 | 0.1667 |
| 4 | 315c96c26c9aac | de04010b3458dd | 6dc8ff871e21e6 | 0 | 0 | 100.00 | 0 | 0 | 0 | 45 | ... | 0 | 0.0000 | 0 | 0.00 | 0 | 0 | 49.75 | 2 | 0 | 0.1875 |
5 rows × 29 columns
print(train_df.columns.values)
print('_'*40)
print(test_df.columns.values)
['Id' 'groupId' 'matchId' 'assists' 'boosts' 'damageDealt' 'DBNOs' 'headshotKills' 'heals' 'killPlace' 'killPoints' 'kills' 'killStreaks' 'longestKill' 'matchDuration' 'matchType' 'maxPlace' 'numGroups' 'rankPoints' 'revives' 'rideDistance' 'roadKills' 'swimDistance' 'teamKills' 'vehicleDestroys' 'walkDistance' 'weaponsAcquired' 'winPoints' 'winPlacePerc'] ________________________________________ ['Id' 'groupId' 'matchId' 'assists' 'boosts' 'damageDealt' 'DBNOs' 'headshotKills' 'heals' 'killPlace' 'killPoints' 'kills' 'killStreaks' 'longestKill' 'matchDuration' 'matchType' 'maxPlace' 'numGroups' 'rankPoints' 'revives' 'rideDistance' 'roadKills' 'swimDistance' 'teamKills' 'vehicleDestroys' 'walkDistance' 'weaponsAcquired' 'winPoints']
pd.set_option('display.max_columns',None)
train_df.describe()
| assists | boosts | damageDealt | DBNOs | headshotKills | heals | killPlace | killPoints | kills | killStreaks | longestKill | matchDuration | maxPlace | numGroups | rankPoints | revives | rideDistance | roadKills | swimDistance | teamKills | vehicleDestroys | walkDistance | weaponsAcquired | winPoints | winPlacePerc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446966e+06 | 4.446965e+06 |
| mean | 2.338149e-01 | 1.106908e+00 | 1.307171e+02 | 6.578755e-01 | 2.268196e-01 | 1.370147e+00 | 4.759935e+01 | 5.050060e+02 | 9.247833e-01 | 5.439551e-01 | 2.299759e+01 | 1.579506e+03 | 4.450467e+01 | 4.300759e+01 | 8.920105e+02 | 1.646590e-01 | 6.061157e+02 | 3.496091e-03 | 4.509322e+00 | 2.386841e-02 | 7.918208e-03 | 1.154218e+03 | 3.660488e+00 | 6.064601e+02 | 4.728216e-01 |
| std | 5.885731e-01 | 1.715794e+00 | 1.707806e+02 | 1.145743e+00 | 6.021553e-01 | 2.679982e+00 | 2.746294e+01 | 6.275049e+02 | 1.558445e+00 | 7.109721e-01 | 5.097262e+01 | 2.587399e+02 | 2.382811e+01 | 2.328949e+01 | 7.366478e+02 | 4.721671e-01 | 1.498344e+03 | 7.337297e-02 | 3.050220e+01 | 1.673935e-01 | 9.261157e-02 | 1.183497e+03 | 2.456544e+00 | 7.397004e+02 | 3.074050e-01 |
| min | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 9.000000e+00 | 1.000000e+00 | 1.000000e+00 | -1.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 |
| 25% | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 2.400000e+01 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.367000e+03 | 2.800000e+01 | 2.700000e+01 | -1.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.551000e+02 | 2.000000e+00 | 0.000000e+00 | 2.000000e-01 |
| 50% | 0.000000e+00 | 0.000000e+00 | 8.424000e+01 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 4.700000e+01 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.438000e+03 | 3.000000e+01 | 3.000000e+01 | 1.443000e+03 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 6.856000e+02 | 3.000000e+00 | 0.000000e+00 | 4.583000e-01 |
| 75% | 0.000000e+00 | 2.000000e+00 | 1.860000e+02 | 1.000000e+00 | 0.000000e+00 | 2.000000e+00 | 7.100000e+01 | 1.172000e+03 | 1.000000e+00 | 1.000000e+00 | 2.132000e+01 | 1.851000e+03 | 4.900000e+01 | 4.700000e+01 | 1.500000e+03 | 0.000000e+00 | 1.909750e-01 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.976000e+03 | 5.000000e+00 | 1.495000e+03 | 7.407000e-01 |
| max | 2.200000e+01 | 3.300000e+01 | 6.616000e+03 | 5.300000e+01 | 6.400000e+01 | 8.000000e+01 | 1.010000e+02 | 2.170000e+03 | 7.200000e+01 | 2.000000e+01 | 1.094000e+03 | 2.237000e+03 | 1.000000e+02 | 1.000000e+02 | 5.910000e+03 | 3.900000e+01 | 4.071000e+04 | 1.800000e+01 | 3.823000e+03 | 1.200000e+01 | 5.000000e+00 | 2.578000e+04 | 2.360000e+02 | 2.013000e+03 | 1.000000e+00 |
train_df.describe(include=['O'])
| Id | groupId | matchId | matchType | |
|---|---|---|---|---|
| count | 4446966 | 4446966 | 4446966 | 4446966 |
| unique | 4446966 | 2026745 | 47965 | 16 |
| top | 1bc607a27f6d3e | 14d6b54cdec6bc | 08fe69fe30cdce | squad-fpp |
| freq | 1 | 74 | 100 | 1756186 |
train_df[['longestKill', 'winPlacePerc']].groupby(['longestKill'], as_index=False).mean().sort_values(by='winPlacePerc', ascending=False)
| longestKill | winPlacePerc | |
|---|---|---|
| 27477 | 572.8000 | 1.0 |
| 27700 | 629.0000 | 1.0 |
| 26911 | 490.0000 | 1.0 |
| 27716 | 633.9000 | 1.0 |
| 27387 | 556.8000 | 1.0 |
| 26606 | 456.5000 | 1.0 |
| 26913 | 490.2000 | 1.0 |
| 27714 | 633.6000 | 1.0 |
| 26601 | 455.8000 | 1.0 |
| 26936 | 492.9000 | 1.0 |
| 28032 | 790.1000 | 1.0 |
| 27701 | 629.4000 | 1.0 |
| 28033 | 790.2000 | 1.0 |
| 28022 | 779.6000 | 1.0 |
| 28034 | 790.6000 | 1.0 |
| 27386 | 556.7000 | 1.0 |
| 27439 | 564.6000 | 1.0 |
| 27694 | 627.3000 | 1.0 |
| 28038 | 796.4000 | 1.0 |
| 27291 | 539.8000 | 1.0 |
| 27693 | 627.0000 | 1.0 |
| 26947 | 494.3000 | 1.0 |
| 27691 | 625.1000 | 1.0 |
| 28044 | 800.9000 | 1.0 |
| 27720 | 634.8000 | 1.0 |
| 26614 | 457.3000 | 1.0 |
| 26536 | 449.0000 | 1.0 |
| 27732 | 637.8000 | 1.0 |
| 28003 | 768.5000 | 1.0 |
| 28004 | 768.6000 | 1.0 |
| ... | ... | ... |
| 329 | 0.3867 | 0.0 |
| 182 | 0.3195 | 0.0 |
| 2797 | 0.7669 | 0.0 |
| 1529 | 0.6102 | 0.0 |
| 387 | 0.4046 | 0.0 |
| 1922 | 0.6631 | 0.0 |
| 78 | 0.2496 | 0.0 |
| 1897 | 0.6601 | 0.0 |
| 93 | 0.2605 | 0.0 |
| 2994 | 0.7881 | 0.0 |
| 4145 | 0.9053 | 0.0 |
| 378 | 0.4008 | 0.0 |
| 371 | 0.3993 | 0.0 |
| 1752 | 0.6405 | 0.0 |
| 2519 | 0.7355 | 0.0 |
| 671 | 0.4747 | 0.0 |
| 119 | 0.2836 | 0.0 |
| 1721 | 0.6366 | 0.0 |
| 701 | 0.4802 | 0.0 |
| 706 | 0.4812 | 0.0 |
| 1025 | 0.5333 | 0.0 |
| 1623 | 0.6229 | 0.0 |
| 1621 | 0.6227 | 0.0 |
| 744 | 0.4882 | 0.0 |
| 1616 | 0.6222 | 0.0 |
| 2980 | 0.7867 | 0.0 |
| 1592 | 0.6192 | 0.0 |
| 787 | 0.4956 | 0.0 |
| 840 | 0.5042 | 0.0 |
| 717 | 0.4832 | 0.0 |
28284 rows × 2 columns
train_df['longestKillBand'] = pd.cut(train_df['longestKill'],10)
train_df[['longestKillBand', 'winPlacePerc']].groupby(['longestKillBand'], as_index=False).mean().sort_values(by='longestKillBand', ascending=True)
| longestKillBand | winPlacePerc | |
|---|---|---|
| 0 | (-1.094, 109.4] | 0.449404 |
| 1 | (109.4, 218.8] | 0.816407 |
| 2 | (218.8, 328.2] | 0.851486 |
| 3 | (328.2, 437.6] | 0.859065 |
| 4 | (437.6, 547.0] | 0.856173 |
| 5 | (547.0, 656.4] | 0.857673 |
| 6 | (656.4, 765.8] | 0.859846 |
| 7 | (765.8, 875.2] | 0.812180 |
| 8 | (875.2, 984.6] | 0.809798 |
| 9 | (984.6, 1094.0] | 0.673227 |
combine=[train_df,test_df]
for dataset in combine:
dataset.loc[ dataset['longestKill'] <= 109.4, 'longestKill'] = 0
dataset.loc[dataset['longestKill'] > 109.4 , 'longestKill'] = 1
train_df.head()
| Id | groupId | matchId | assists | boosts | damageDealt | DBNOs | headshotKills | heals | killPlace | killPoints | kills | killStreaks | longestKill | matchDuration | matchType | maxPlace | numGroups | rankPoints | revives | rideDistance | roadKills | swimDistance | teamKills | vehicleDestroys | walkDistance | weaponsAcquired | winPoints | winPlacePerc | longestKillBand | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7f96b2f878858a | 4d4b580de459be | a10357fd1a4a91 | 0 | 0 | 0.00 | 0 | 0 | 0 | 60 | 1241 | 0 | 0 | 0.0 | 1306 | squad-fpp | 28 | 26 | -1 | 0 | 0.0000 | 0 | 0.00 | 0 | 0 | 244.80 | 1 | 1466 | 0.4444 | (-1.094, 109.4] |
| 1 | eef90569b9d03c | 684d5656442f9e | aeb375fc57110c | 0 | 0 | 91.47 | 0 | 0 | 0 | 57 | 0 | 0 | 0 | 0.0 | 1777 | squad-fpp | 26 | 25 | 1484 | 0 | 0.0045 | 0 | 11.04 | 0 | 0 | 1434.00 | 5 | 0 | 0.6400 | (-1.094, 109.4] |
| 2 | 1eaf90ac73de72 | 6a4a42c3245a74 | 110163d8bb94ae | 1 | 0 | 68.00 | 0 | 0 | 0 | 47 | 0 | 0 | 0 | 0.0 | 1318 | duo | 50 | 47 | 1491 | 0 | 0.0000 | 0 | 0.00 | 0 | 0 | 161.80 | 2 | 0 | 0.7755 | (-1.094, 109.4] |
| 3 | 4616d365dd2853 | a930a9c79cd721 | f1f1f4ef412d7e | 0 | 0 | 32.90 | 0 | 0 | 0 | 75 | 0 | 0 | 0 | 0.0 | 1436 | squad-fpp | 31 | 30 | 1408 | 0 | 0.0000 | 0 | 0.00 | 0 | 0 | 202.70 | 3 | 0 | 0.1667 | (-1.094, 109.4] |
| 4 | 315c96c26c9aac | de04010b3458dd | 6dc8ff871e21e6 | 0 | 0 | 100.00 | 0 | 0 | 0 | 45 | 0 | 1 | 1 | 0.0 | 1424 | solo-fpp | 97 | 95 | 1560 | 0 | 0.0000 | 0 | 0.00 | 0 | 0 | 49.75 | 2 | 0 | 0.1875 | (-1.094, 109.4] |
train_df['matchDurationBand'] = pd.cut(train_df['matchDuration'],5)
train_df[['matchDurationBand', 'winPlacePerc']].groupby(['matchDurationBand'], as_index=False).mean().sort_values(by='matchDurationBand', ascending=True)
| matchDurationBand | winPlacePerc | |
|---|---|---|
| 0 | (6.772, 454.6] | 0.530637 |
| 1 | (454.6, 900.2] | 0.517062 |
| 2 | (900.2, 1345.8] | 0.471524 |
| 3 | (1345.8, 1791.4] | 0.474426 |
| 4 | (1791.4, 2237.0] | 0.470903 |
train_df=train_df.drop(['matchDuration','matchDurationBand','longestKillBand'],axis=1)
test_df=test_df.drop(['matchDuration'],axis=1)
combine=[train_df,test_df]
train_df.shape,test_df.shape
((4446966, 28), (1934174, 27))
train_df['TotalDIstance']=train_df['rideDistance']+train_df['swimDistance']+train_df['walkDistance']
sns.jointplot(x="winPlacePerc", y="TotalDIstance", data=train_df, color="r")
plt.show()
/home/striver13/.conda/envs/tensorflow/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result. return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
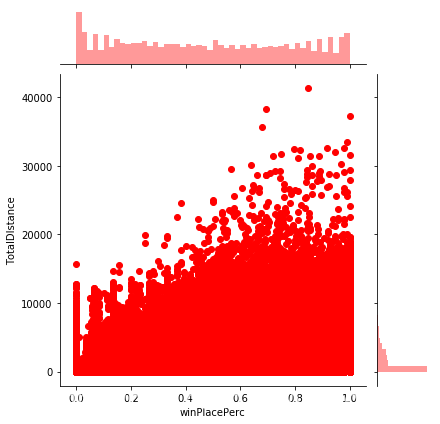
test_df['TotalDIstance']=test_df['rideDistance']+test_df['swimDistance']+test_df['walkDistance']
train_df=train_df.drop(['rideDistance','swimDistance','walkDistance'],axis=1)
test_df=test_df.drop(['rideDistance','swimDistance','walkDistance'],axis=1)
train_df['TotalDIstanceBand'] = pd.qcut(train_df['TotalDIstance'],5)
train_df[['TotalDIstanceBand', 'winPlacePerc']].groupby(['TotalDIstanceBand'], as_index=False).mean().sort_values(by='TotalDIstanceBand', ascending=True)
| TotalDIstanceBand | winPlacePerc | |
|---|---|---|
| 0 | (-0.001, 111.8] | 0.125982 |
| 1 | (111.8, 394.7] | 0.265504 |
| 2 | (394.7, 1536.5] | 0.464991 |
| 3 | (1536.5, 3162.0] | 0.722559 |
| 4 | (3162.0, 41270.1] | 0.785090 |
combine=[train_df,test_df]
train_df.head()
| Id | groupId | matchId | assists | boosts | damageDealt | DBNOs | headshotKills | heals | killPlace | killPoints | kills | killStreaks | longestKill | matchType | maxPlace | numGroups | rankPoints | revives | roadKills | teamKills | vehicleDestroys | weaponsAcquired | winPoints | winPlacePerc | TotalDIstance | TotalDIstanceBand | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7f96b2f878858a | 4d4b580de459be | a10357fd1a4a91 | 0 | 0 | 0.00 | 0 | 0 | 0 | 60 | 1241 | 0 | 0 | 0.0 | squad-fpp | 28 | 26 | -1 | 0 | 0 | 0 | 0 | 1 | 1466 | 0.4444 | 244.8000 | (111.8, 394.7] |
| 1 | eef90569b9d03c | 684d5656442f9e | aeb375fc57110c | 0 | 0 | 91.47 | 0 | 0 | 0 | 57 | 0 | 0 | 0 | 0.0 | squad-fpp | 26 | 25 | 1484 | 0 | 0 | 0 | 0 | 5 | 0 | 0.6400 | 1445.0445 | (394.7, 1536.5] |
| 2 | 1eaf90ac73de72 | 6a4a42c3245a74 | 110163d8bb94ae | 1 | 0 | 68.00 | 0 | 0 | 0 | 47 | 0 | 0 | 0 | 0.0 | duo | 50 | 47 | 1491 | 0 | 0 | 0 | 0 | 2 | 0 | 0.7755 | 161.8000 | (111.8, 394.7] |
| 3 | 4616d365dd2853 | a930a9c79cd721 | f1f1f4ef412d7e | 0 | 0 | 32.90 | 0 | 0 | 0 | 75 | 0 | 0 | 0 | 0.0 | squad-fpp | 31 | 30 | 1408 | 0 | 0 | 0 | 0 | 3 | 0 | 0.1667 | 202.7000 | (111.8, 394.7] |
| 4 | 315c96c26c9aac | de04010b3458dd | 6dc8ff871e21e6 | 0 | 0 | 100.00 | 0 | 0 | 0 | 45 | 0 | 1 | 1 | 0.0 | solo-fpp | 97 | 95 | 1560 | 0 | 0 | 0 | 0 | 2 | 0 | 0.1875 | 49.7500 | (-0.001, 111.8] |
for dataset in combine:
dataset.loc[ dataset['TotalDIstance'] <= 111.8, 'TotalDIstance'] = 0
dataset.loc[(dataset['TotalDIstance'] > 111.8) & (dataset['TotalDIstance'] <= 394.7), 'TotalDIstance'] = 1
dataset.loc[(dataset['TotalDIstance'] > 394.7) & (dataset['TotalDIstance'] <= 1536.5), 'TotalDIstance'] = 2
dataset.loc[(dataset['TotalDIstance'] > 1536.5) & (dataset['TotalDIstance'] <= 3162.0), 'TotalDIstance'] = 3
dataset.loc[ dataset['TotalDIstance'] > 3162.0, 'TotalDIstance']=4
train_df.head()
| Id | groupId | matchId | assists | boosts | damageDealt | DBNOs | headshotKills | heals | killPlace | killPoints | kills | killStreaks | longestKill | matchType | maxPlace | numGroups | rankPoints | revives | roadKills | teamKills | vehicleDestroys | weaponsAcquired | winPoints | winPlacePerc | TotalDIstance | TotalDIstanceBand | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7f96b2f878858a | 4d4b580de459be | a10357fd1a4a91 | 0 | 0 | 0.00 | 0 | 0 | 0 | 60 | 1241 | 0 | 0 | 0.0 | squad-fpp | 28 | 26 | -1 | 0 | 0 | 0 | 0 | 1 | 1466 | 0.4444 | 1.0 | (111.8, 394.7] |
| 1 | eef90569b9d03c | 684d5656442f9e | aeb375fc57110c | 0 | 0 | 91.47 | 0 | 0 | 0 | 57 | 0 | 0 | 0 | 0.0 | squad-fpp | 26 | 25 | 1484 | 0 | 0 | 0 | 0 | 5 | 0 | 0.6400 | 2.0 | (394.7, 1536.5] |
| 2 | 1eaf90ac73de72 | 6a4a42c3245a74 | 110163d8bb94ae | 1 | 0 | 68.00 | 0 | 0 | 0 | 47 | 0 | 0 | 0 | 0.0 | duo | 50 | 47 | 1491 | 0 | 0 | 0 | 0 | 2 | 0 | 0.7755 | 1.0 | (111.8, 394.7] |
| 3 | 4616d365dd2853 | a930a9c79cd721 | f1f1f4ef412d7e | 0 | 0 | 32.90 | 0 | 0 | 0 | 75 | 0 | 0 | 0 | 0.0 | squad-fpp | 31 | 30 | 1408 | 0 | 0 | 0 | 0 | 3 | 0 | 0.1667 | 1.0 | (111.8, 394.7] |
| 4 | 315c96c26c9aac | de04010b3458dd | 6dc8ff871e21e6 | 0 | 0 | 100.00 | 0 | 0 | 0 | 45 | 0 | 1 | 1 | 0.0 | solo-fpp | 97 | 95 | 1560 | 0 | 0 | 0 | 0 | 2 | 0 | 0.1875 | 0.0 | (-0.001, 111.8] |
train_df=train_df.drop(['TotalDIstanceBand'],axis=1)
train_df.shape,test_df.shape
((4446966, 26), (1934174, 25))
sns.jointplot(x="winPlacePerc", y="kills", data=train_df, color="r")
plt.show()
/home/striver13/.conda/envs/tensorflow/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result. return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval

sns.jointplot(x="winPlacePerc", y="DBNOs", data=train_df, color="r")
plt.show()
/home/striver13/.conda/envs/tensorflow/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result. return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
train_df['killsMulDamageDealt']=train_df['kills']*train_df['damageDealt']
sns.jointplot(x="winPlacePerc", y="killsMulDamageDealt", data=train_df, color="r")
plt.show()
train_df['killsMulDamageDealtBand'] = pd.cut(train_df['killsMulDamageDealt'],10)
train_df[['killsMulDamageDealtBand', 'winPlacePerc']].groupby(['killsMulDamageDealtBand'], as_index=False).mean().sort_values(by='killsMulDamageDealtBand', ascending=True)
test_df['killsMulDamageDealt']=test_df['kills']*test_df['damageDealt']
test_df.head()
combine=[train_df,test_df]
for dataset in combine:
dataset.loc[ dataset['killsMulDamageDealt'] <= 43128.0, 'killsMulDamageDealt'] = 0
dataset.loc[ dataset['killsMulDamageDealt'] > 43128.0, 'killsMulDamageDealt']=1
train_df.head()
train_df=train_df.drop(['killsMulDamageDealtBand'],axis=1)
train_df.shape,test_df.shape
sns.jointplot(x="winPlacePerc", y="killPlace", data=train_df, color="r")
plt.show()
sns.jointplot(x="winPlacePerc", y="killPoints", data=train_df, color="r")
plt.show()
train_df=train_df.drop(['killPoints','damageDealt','kills','matchType'],axis=1)
test_df=test_df.drop(['killPoints','damageDealt','kills','matchType'],axis=1)
train_df.shape,test_df.shape
data = train_df.copy()
data = data[data['heals'] < data['heals'].quantile(0.99)]
data = data[data['boosts'] < data['boosts'].quantile(0.99)]
f,ax1 = plt.subplots(figsize =(20,10))
sns.pointplot(x='heals',y='winPlacePerc',data=data,color='lime',alpha=0.8)
sns.pointplot(x='boosts',y='winPlacePerc',data=data,color='blue',alpha=0.8)
plt.text(4,0.6,'Heals',color='lime',fontsize = 17,style = 'italic')
plt.text(4,0.55,'Boosts',color='blue',fontsize = 17,style = 'italic')
plt.xlabel('Number of heal/boost items',fontsize = 15,color='blue')
plt.ylabel('Win Percentage',fontsize = 15,color='blue')
plt.title('Heals vs Boosts ',fontsize = 20,color='blue')
plt.grid()
plt.show()
data = train_df.copy()
data = data[data['assists'] < data['assists'].quantile(0.99)]
f,ax1 = plt.subplots(figsize =(20,10))
sns.pointplot(x='assists',y='winPlacePerc',data=data,color='red',alpha=0.8)
plt.text(4,0.55,'assists',color='red',fontsize = 17,style = 'italic')
plt.xlabel('Number of assist items',fontsize = 15,color='blue')
plt.ylabel('Win Percentage',fontsize = 15,color='blue')
plt.title('assist',fontsize = 20,color='blue')
plt.grid()
plt.show()
sns.jointplot(x="winPlacePerc", y="winPoints", data=train_df, color="r")
plt.show()
sns.jointplot(x="winPlacePerc", y="vehicleDestroys", data=train_df, color="r")
plt.show()
sns.jointplot(x="winPlacePerc", y="headshotKills", data=train_df, color="r")
plt.show()
sns.jointplot(x="winPlacePerc", y="revives", data=train_df, color="r")
plt.show()
train_df.head()
sns.jointplot(x="winPlacePerc", y="killStreaks", data=train_df, color="r")
plt.show()
sns.jointplot(x="winPlacePerc", y="weaponsAcquired", data=train_df, color="r")
plt.show()
train_df=train_df.drop(['Id','DBNOs','killStreaks','rankPoints','revives','roadKills','winPoints','weaponsAcquired'],axis=1)
test_df=test_df.drop(['Id','DBNOs','killStreaks','rankPoints','revives','roadKills','winPoints','weaponsAcquired'],axis=1)
train_df.shape,test_df.shape
train_df.head()
combine=[train_df,test_df]
for dataset in combine:
dataset.loc[ dataset['numGroups'] <= 27, 'matchType'] = 4
dataset.loc[(dataset['longestKill'] > 27) & (dataset['longestKill'] <=55), 'matchType'] = 2
dataset.loc[dataset['longestKill'] > 55, 'matchType'] = 1
train_df=train_df.drop(['numGroups'],axis=1)
test_df=test_df.drop(['numGroups'],axis=1)
train_df.head()
sns.jointplot(x="winPlacePerc", y="teamKills", data=train_df, color="r")
plt.show()
train_df=train_df.drop(['teamKills','maxPlace'],axis=1)
test_df=test_df.drop(['teamKills','maxPlace'],axis=1)
train_df.describe()
train_df.head(100)
'''
train_df=train_df.groupby(['groupId'], as_index=False).mean().sort_values(by='groupId', ascending=True)
test_df=test_df.groupby(['groupId'], as_index=False).mean().sort_values(by='groupId', ascending=True)
test_df.head()
'''
train_df=train_df.dropna(how="any")
#建立訓練樣本XY
X_train = train_df.drop(["winPlacePerc",'matchId','groupId'], axis=1)
Y_train = train_df["winPlacePerc"]
X_test = test_df.drop(['groupId','matchId'],axis=1).copy()#拷貝,其他地直接= 都是別名,更改X_train會改變train_df
X_train.shape, Y_train.shape, X_test.shape
X_train.info()
Y_train.describe()
np.where(np.isnan(Y_train))
np.where(np.isnan(X_train))
X_test=X_test.fillna(0)
np.where(np.isnan(X_test))
epoch_train = 15
mlp = MLP(layer_size=[x_train.shape[1], 28, 28, 28, 1], regularization=1, output_shrink=0.1, output_range=[-1,1], loss_type="hardmse")
mlp.train(X_train, Y_train, verbose=0, iteration_log=20000, rate_init=0.08, rate_decay=0.8, epoch_train=epoch_train, epoch_decay=1)
pred = mlp.predict(X_test)
pred = pred.reshape(-1)
pred = (pred + 1) / 2
print(pred)
X_test['winPlacePerc']=pred
test_df=pd.read_csv('./all/test_V2.csv')
sub=pd.DataFrame(columns=['Id','winPlacePerc'])
sub['Id']=test_df['Id']
sub['winPlacePerc']=X_test['winPlacePerc']
sub.to_csv('sample_submission.csv',index=False)