
基本機器學習面試問題 --- 理論/演算法2
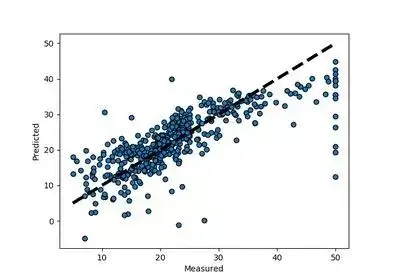
線性迴歸
- 如何學習引數:最小化損失函式
- 如何最小化損失函式:梯度下降
- 正則化:
- L1(Lasso 迴歸):可以將某個係數縮小到零,從而執行特徵選擇;
- L2(Ridge 迴歸):以同樣的比例收縮所有係數 ; 幾乎總是勝過 L1;
- 合併(彈性網)。
- 假定特徵和標籤之間存線上性關係
- 可以新增多項式和互動特徵以增加非線性
邏輯迴歸
- 用於二分類問題的廣義線性模型(GLM)
- 將 sigmoid 函式應用於線性模型的輸出,將目標壓縮到範圍 [0,1]
- 通過閾值做出預測:如果輸出> 0.5,預測 1;否則預測 0
- softmax 函式:處理多分類問題
KNN
給定一個數據點,使用一定的距離度量(例如歐幾里德距離)計算 K 個最近的資料點(近鄰)。對於分類,可以取大多數近鄰的標籤;對於迴歸,我們採用標籤值的均值。
對於 KNN 來說,我們不需要訓練模型,我們只是在推理時間內進行計算。這可能在計算上很昂貴,因為每個測試樣本都需要與每個訓練樣本進行比較以瞭解它們有多接近。
有近似的方法可以有更快的推斷時間,通過將訓練資料集劃分成區域。
注意,當 K 等於 1 或其他小數字時,模型容易出現過擬合(高方差),而當 K 等於資料點數或更大的數字時,模型容易出現欠擬合(高偏差)。

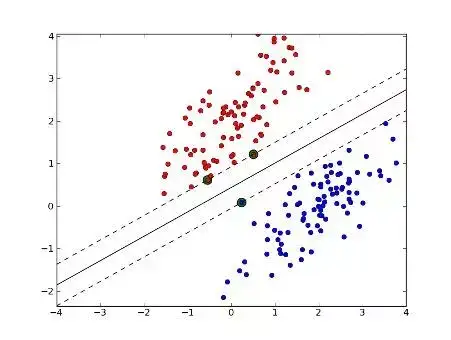
SVM
- 可以執行線性,非線性或異常值檢測(無監督)
- 大間距分類器:不僅有一個決策邊界,而且希望邊界距離最近的訓練點儘可能遠
- 最接近的訓練樣例被稱為支援向量,因為它們是繪製決策邊界所基於的點
- SVM 對特徵縮放比較敏感
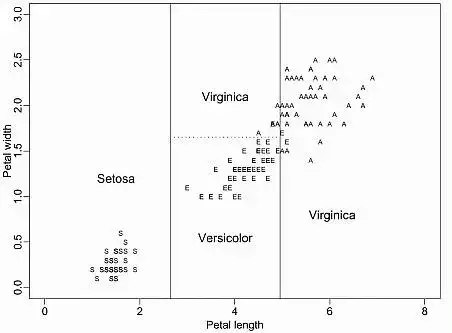
決策樹
- 非引數,有監督的學習演算法
- 給定訓練資料,決策樹演算法將特徵空間劃分為區域。為了推斷,我們首先觀測測試資料點落入哪個區域,並取平均標籤值(迴歸)或多數標籤值(分類)。
- 構造:自上而下,選擇一個變數來分割資料,使得每個區域內的目標變數儘可能均勻。兩個常見的指標:基尼不純或資訊增益,在實驗中兩者結果差異不大。
- 優點:簡單地理解和解釋,模仿人類決策過程
- 壞處:
- 如果我們不限制樹的深度,可以容易地過度擬合可能不夠魯棒:訓練資料的小改動
- 可能導致完全不同的樹
- 不穩定性:由於其正交決策邊界,對訓練集旋轉敏感
Bagging
為了解決過擬合問題,我們可以使用稱為 bagging(bootstrap aggregating)的整合方法,它減少了元學習演算法的方差。bagging 可以應用於決策樹或其他演算法。
這是一個很好的例子:
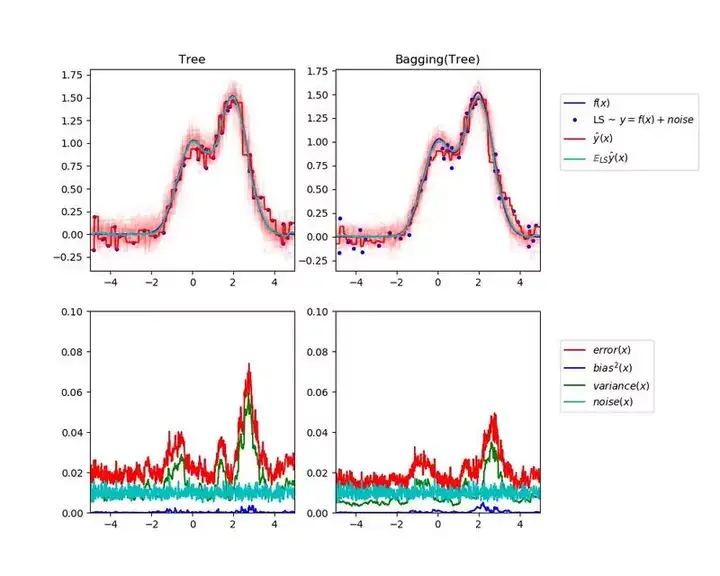
- bagging 是有放回取樣。在子取樣無放回時,則稱為 pasting。
- bagging 因其對效能的提高而廣受歡迎,也因為單獨的機器學習模型可以並行訓練,並且可以很好地擴充套件。
- 當機器學習模型儘可能彼此獨立時,整合方法效果最好
- 投票: 軟投票(對所有演算法的預測概率取平均值)通常比硬投票更有效。
- 袋外(out-of-bag)例項(37%)可以作為 bagging 的驗證集。
隨機森林
隨機森林通過增加一些隨機性來進一步改善 bagging。在隨機森林中,只隨機選擇一部分特徵來構建樹(而不是子取樣例項)。好處是隨機森林減少了樹之間的相關性。
假設我們有一個數據集。有一個資訊增益很高的特徵,以及一些預測性較弱的特徵。在 bagging 樹中,大多數樹將在頂部拆分時使用這個預測性很強的特徵,因此使得大部分樹看起來相似,並且高度相關。與互不相關的結果相比,對高度相關的結果取平均不會大量降低方差。在隨機森林中,每一次劃分節點我們只考慮特徵的一個子集,並因此通過引入更多不相關的樹來進一步減少方差。
在實踐中,調整隨機森林需要擁有大量的樹(越多越好,但需要考慮計算約束)。此外,用 min_samples_leaf(葉節點的樣本的最小數量)來控制樹大小和過擬合。
特徵的重要性:
在決策樹中,更重要的特徵可能更接近樹的頂部。通過計算它在森林中所有樹上出現的平均深度,我們可以得到一個特徵對於隨機森林的重要性。
Boosting 樹
原理
Boosting 樹以迭代方式建立在弱學習器身上。在每次迭代中,都會新增一個新的學習器,而所有現有的學習器都保持不變。所有的學習器根據他們的表現(例如,準確性)進行加權,並且在加入弱學習器之後,對資料進行重新加權:錯誤分類的樣例獲得更多的權重,而正確分類的樣例減少權重。因此,未來的弱學習器會更多地關注之前的弱學習器錯誤分類的樣例。
與隨機森林(RF)的區別
- RF 是並行訓練,而 Boosting 是按順序訓練
- RF 降低了方差,而 Boosting 通過減少偏差來減少誤差
XGBoost(極端梯度提升):
XGBoost 使用更正則化的模型來控制過擬合,從而使其具有更好的效能。
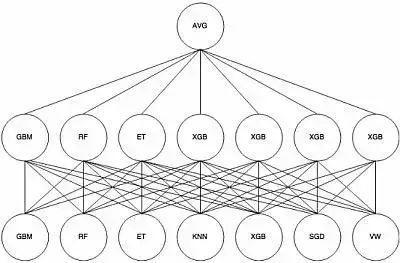
Stacking
- 不是使用簡單的函式 (例如硬投票) 來整合單個學習器的預測,而是訓練一個模型來執行這個整合過程。
- 首先將訓練集分為兩個子集:第一個子集用於訓練第一層的學習器
- 接下來,第一層學習器被用於對第二子集進行預測(元特徵),並且這些預測被用於在第二層訓練另一個模型(以獲得不同學習器的權重)
- 可以在第二層中訓練多個模型,但這需要將原始資料集分為三部分
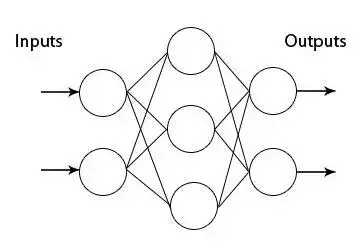
MLP
MLP,多層前饋神經網路。每一層可以有多個神經元,下一層中每個神經元的輸入是上一層中所有神經元輸出的線性或非線性組合。為了訓練網路,逐層反向傳播誤差。理論上 MLP 可以近似任何函式。
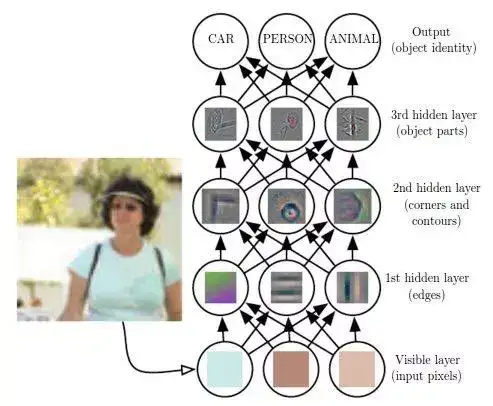
CNN
Conv 層是卷積神經網路的基礎結構。Conv 層由一組可學習的濾波器(例如 5 × 5 × 3,寬×高×深)組成。在前向傳遞期間,我們將濾波器在輸入上滑動(或更準確地說,卷積)並計算點積。當網路反向傳播誤差時,再次進行學習。
初始層可以捕捉低階特徵(如角度和邊緣),而後面的層可以學習前一層低階特徵的組合,因此可以表示高階特徵,如形狀和目標部分。
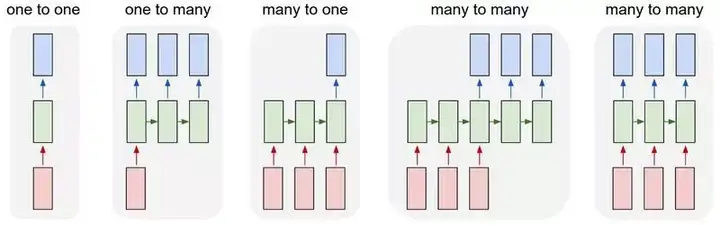
RNN 和 LSTM
RNN 是神經網路的另一個正規化,有不同層的神經元,每個神經元不只把前一層神經元的輸出作為輸入,而且把同一層的前一個神經元的輸出作為輸入。
這看起來很棒,但實際上由於相同矩陣的一系列乘法運算,會造成梯度消失或梯度爆炸,使 RNN 幾乎不能運作。為了解決這個問題,我們可以使用 RNN 的一個變種,長短時記憶(LSTM),它能夠學習長期的依賴關係。
LSTM 背後的數學演算法可能相當複雜,但直觀上 LSTM 引入了輸入門 - 輸出門 - 遺忘門 - 記憶單元(內部狀態)
LSTM 模仿人類的記憶過程:忘記舊的東西(舊的內部狀態×遺忘門)並重新輸入(輸入節點×輸入門)

word2vec
- 淺層,雙層神經網路,經過訓練可以構建詞語的語言上下文
- 以一個大的語料庫為輸入,產生一個向量空間,一般為幾百維,並且語料庫中的每個單詞指向空間中的一個向量
- 關鍵的思想是上下文:經常出現在同一語境中的單詞應該具有相同或相反的意義。
- 兩種風格
- 連續詞袋(CBOW):給定周圍上下文單詞的視窗,模型預測出當前單
- skip gram:使用當前單詞預測周圍的上下文單詞
生成與判別
- 判別演算法模型 p(y | x; w),即給定資料集和學習引數,得出 y 屬於特定類的概率是多少。判別演算法不關心資料是如何生成的,它只是對給定的樣例進行分類
- 生成演算法嘗試對 p(x | y)進行建模,即給定特徵的類別,得出它的分佈。生成演算法模擬如何生成資料。
給定一個訓練集,像邏輯迴歸或感知器這樣的演算法會試圖找到一條直線,即決策邊界,將大象和狗分開。然後,將新的動物分類為大象或狗,演算法會檢查樣本在決策邊界的哪一邊,並據此做出預測。
下面是一種不同的方法。首先,看大象,我們可以建立一個大象看起來像什麼的模型。然後,看著狗,我們可以建立一個狗的樣子的單獨模型。最後,為了對新動物進行分類,我們可以將新動物與大象模型進行匹配,並將其與狗模型進行匹配,看看新動物看起來更像大象還是更像我們在訓練集中看到的狗。
引數與非引數
- 用一組固定數量的引數(與訓練樣本的數量無關)對資料總結的學習模型稱為引數模型。
- 訓練前未確定引數數量的模型。非引數並不意味著他們沒有引數。相反,隨著資料量的增加,非引數模型(可能)會變得越來越複雜。
參考文章
https://github.com/ShuaiW/data-science-question-answer#data-science-question-answer
https://github.com/ShuaiW/data-science-question-answer#recommender-system
https://www.reddit.com/r/MachineLearning/comments/7w8e0j/d_how_to_prep_for_a_deep_learningmachine_learning/?st=jdi63nwq&sh=61447041