
入門深度學習 — 2
入門深度學習 — 2
解析 CNN 演演算法
上一篇「入門深度學習-1」講如何設定環境,以及如何透過一個預先訓練的模型 VGG16 辨識 dogs vs cats,並將結果 submit 到 kaggle。
VGG16 用的是 CNN (Convolutional Neural Networks ) 演演算法,CNN 是常見用來作影像判別的方法。
在瞭解 CNN 演演算法前,有必要先了解類神經網路,以及多層感知器 (Full-Connected multilayer perceptron) 網路。
多層感知器 Fully-Connected multilayer perceptron
人工智慧並不等同於類神經網路,類神經網路只是 AI 的一種作法。類神經網路是透過模擬人類腦細胞的運作原理來做出「判斷」,人類腦細胞中存在著無數的神經元 (Neuron),這些神經元經由突觸互相連結,每個神經元會經由突觸接收外部訊號,轉化後的輸出再傳導到下個神經元,每個神經元有不同的轉化能力,人類經由這樣的訊號傳遞與轉化,形成思考與判斷的能力。類神經網路便是透過學習效法人腦運作方式來達到同樣的效果。
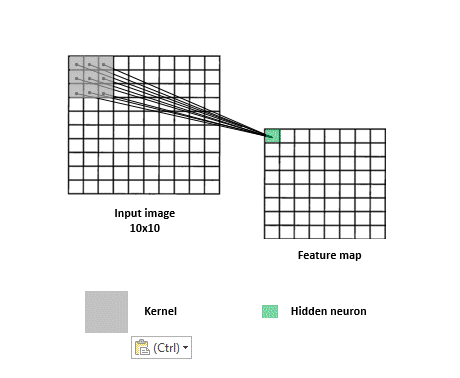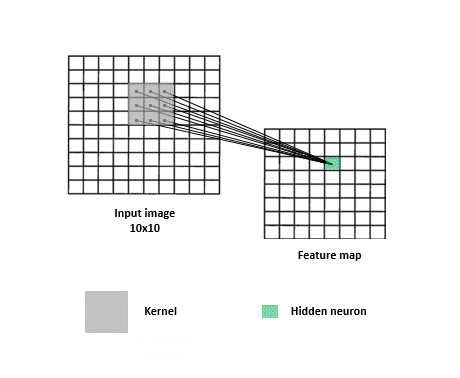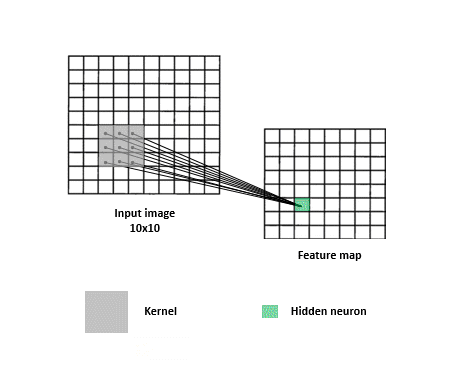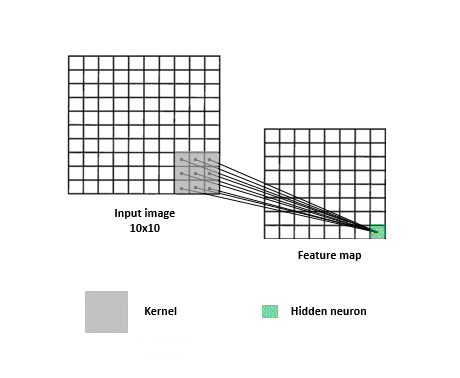
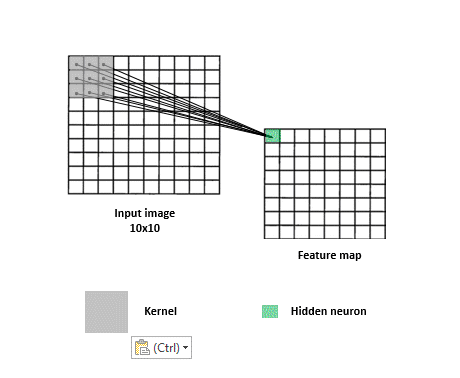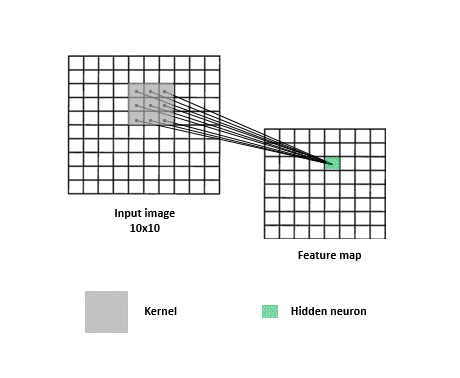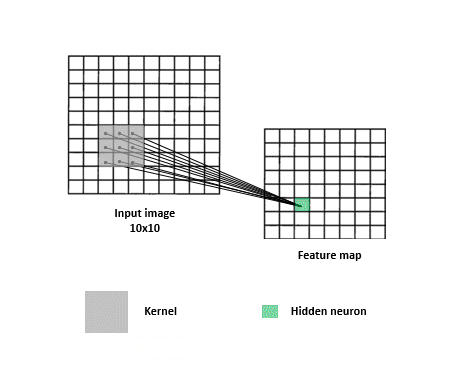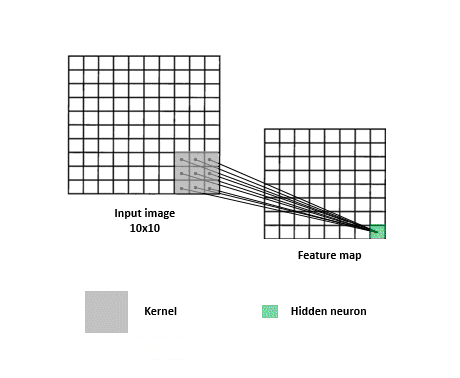
一張圖片我們可以把它視作一個矩陣,例如一個 320x320 大小的圖片,可以視為 320 * 320 * 3 的矩陣(RGB 3 個 Channel),在多層感知器 FC 網路 (Fully Connected multilayer perceptron)中,第一層輸入層就必須有 307,200 個神經元(Neuron)來接收,經過轉換後到 N 個輸出元 (判讀 N 個類別)。只是只有一層的轉換不會有太大的幫助,我們會加上其他層來增加穩定度,也就是所謂的隱藏層。所有輸入層跟隱藏層間的神經元是完全相連 (所以稱之為 Fully Connected)的,如下圖:


單一神經元的轉換公式可以視為:
y = x * w + b
x 是神經元的輸入值,y 是輸出,w 是權重(weight),b 是偏差(bias),一開始模型在建立時,w 跟 b 都是取 random 值,訓練的目的就是替每個神經元找到最事宜的 w 跟 b。此外,由於上面這個公式是個線性公式,為了避免讓訓練出來的結果也是線性(線性的線性還是線性),會在公式外加上非線性的啟用函式(activation function),常見的啟用函式有 sigmoid、tanh、relu:

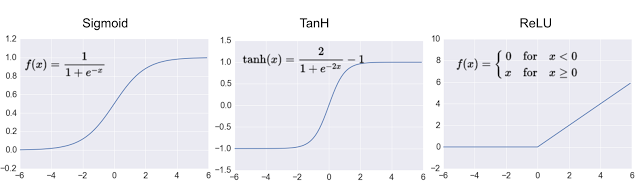
深度學習大多採用 relu 作為啟用函式,relu 又可寫作:
f(x) = max(0, x)
簡單來說就是去除小於 0 的結果,神經元的轉換公式套上 relu 後就成了:
y = relu(x * w + b)
所謂的模型訓練就是透過後推法(backpropagation),一開始先以亂數指定 w 跟 b ,因為我們知道每筆訓練資料的類別,所以透過修改 w 跟 b 值,讓最後結果更接近真正的答案,跑越多次(epoch)準確率會越來越高,等到準確率提升有限時,這些 w 跟 b 值就可以儲存下來,直接拿來用。
多層感知器作法有幾個缺點:
- 需要大量記憶體
在處理 256x256 大小的彩色圖片時,會需要用到 256 * 256 * 3 =196,608 個 Input Neuron,如果中間的隱藏層有 1000 個 Neuron,每個神經元需要一個浮點數的權重值 (8bytes),那麼總共需要 196,608 * 1000 * 8 = 1.4648GBytes 的記憶體才夠。更何況這還只是個簡單的模型。 - 多層感知器只針對圖片中每個單一畫素去作判斷,完全捨棄重要的影像特徵。人類在判斷所看到的物體時,會從不同部位的特徵先作個別判斷,例如當你看到一架飛機,會先從機翼、機鼻、機艙形體等這些特徵,再跟記憶中的印象來判斷是否為一架飛機,甚至再進一步判斷為客機還是戰鬥機。但是多層感知器沒有利用這些特徵,所以在影像的判讀上準確率就沒有接下來要討論的 CNN 來得好。
所以後來有了 CNN: Convolutional Neural Networks
CNN (Convolutional Neural Networks)
CNN 一樣是由好幾層的 Neuron layer 所構成,但有別於 Full-Connected Network,CNN 並非只是單純的 Input、Hidden、Output layer,它的構成來自於: 卷積層 (Convolution)、池化層 (Pooling)、平坦層 (Flatten)、隱藏層 (Hidden)、輸出層 (Output),結構如下:

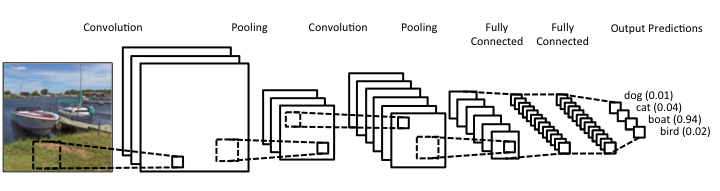
卷積層 (Convolution Layer)
最大的差異來自於卷積層,卷積層的用意是來提取圖片中的特徵(feature)。前面提到 FC 直接使用影像檔的每個 pixel 值作為 input,喪失了圖片中的重要特徵,CNN 的作法是先透過濾鏡(filter)來提取圖片特徵(feature),這些 filter 就像 Integram 的濾鏡一樣,轉換影像,例如取影像中的邊緣、銳利化、模糊化等等,透過不同的 filter 來盡可能取得影像特徵,然後再將這些特徵作為後面 Neuron 的輸入,如此一來便可以大大提升影像辨識的能力。要解釋卷積層可以用程式來說明,先看一下怎麼用卷積套上濾鏡:
- 先讀取一張圖片,轉成灰階二維陣列


2. 之後會套上一個濾鏡 (filter),其實是另外一個 3x3 的矩陣,矩陣如下:


3. 透過卷積與原本的影像作處理




卷積,是我們學習高等數學之後,新接觸的一種運算,因為涉及到積分、級數,所以看起來覺得很複雜。
那什麼是卷積 (Convolve)? 可以參考在知乎找到的這篇解釋:
所以 CNN 就是透過卷積以及不同的濾鏡矩陣去對原始的圖片提取特徵,所以便稱之為「卷積層」。這些特徵會作為下一層的輸入。
如果還有興趣,這篇 wiki 上還有一些其他濾鏡矩陣可以參考:
多層感知器會針對每個影象 pixel 各自去運算,缺點就是喪失了整體影像的線索,但若又只針對整張影象去運算,又很容易 underfitting。所以卷積層的作法是類似 sliding window,去擷取圖片中每個小區塊的特徵,這麼做的有一個好處是即便你想要辨識的物體不在畫面正中央也沒關係,一樣可以提取到特徵。
再來我們透過用 Keras 的實作,逐步拆解看看卷積層的運作方式:




這裡用 Keras 來建立模型,使用 Keras 的好處是他的 API 非常直覺容易使用,Sequential 是一個多層模型,可以透過 add() 函式將一層一層 layer 加上去,在這個範例中,我們加上一層 Convolution2D ,kernel size 為 3x3,並且使用 relu 作為啟用函式。
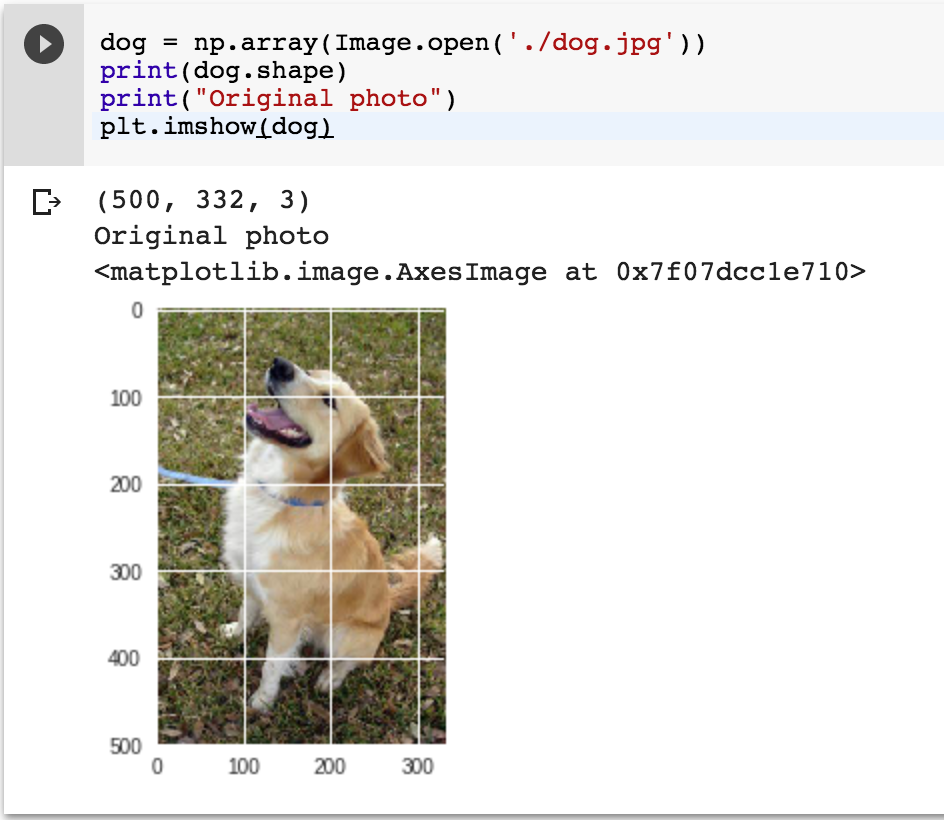
然後把剛剛的狗狗圖片丟進去這個模型看看:


因為 keras 在讀取檔案實是以 batch 的方式一次讀取多張,但我們這裡只需要判讀一張,所以透過 expand_dims() 函式來多擴張一個維度,並且傳給 model.predict() 函式,得到回傳便是 feature map,如果把它顯示出來,看起來就像電視壞掉滿是雜訊的樣子,但還是可以勉強看出輪廓。
會得到這樣的影像是因為我們一開始給的權重都是亂數值,而亂數取出來的 filter 並不具太大意義,假如是經過訓練後的權重值,顯示出來的特徵應該會比較有意義一些。
我們試著去掉色彩,用黑白來看看能不能得到較好的品質:



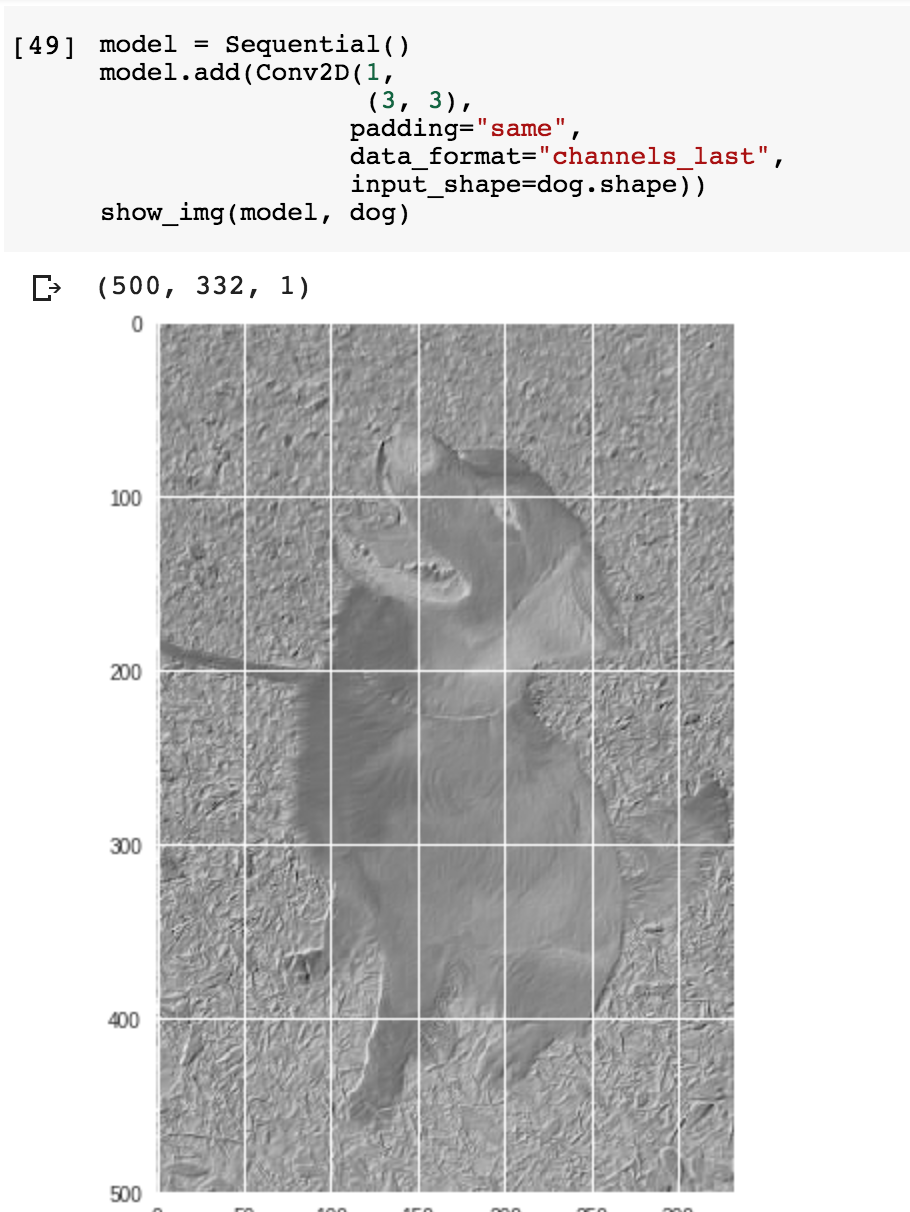


上面這兩張圖跟前面抓邊緣的效果有點類似,卷積層就是用這樣的原理在取圖片特徵,再將這些特徵轉成下一層的輸入。
說明到這,大概也不難猜出 Prisma App 的原理了,只需要建構數層卷積層,最後的輸出是十幾種名畫風格,經過訓練後,便能獲得中間的權重。使用者透過 app 拍張照片,再經由相同的卷積層轉換便能轉換成不同的畫風了。
池化層 (Pooling Layer)
池化層的意義類似 down-sampling,常見的池化動作是 Max pooling,如底下每一個 2x2 的矩陣中取數字最大者,所以一個 4x4 的 feature map,經過 Max-pooling 之後就會形成 2x2 的矩陣。
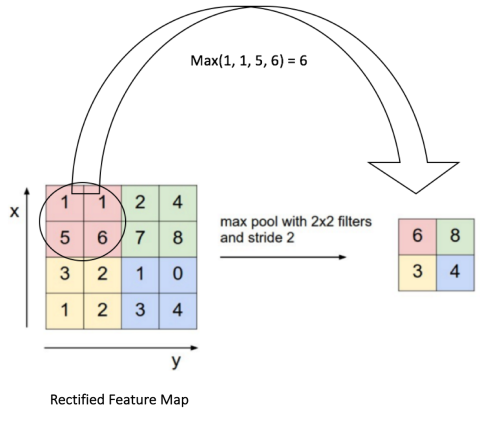
池化層有幾個好處:
- 縮小 feature map 的尺寸,減少需要訓練的引數,避免 overfitting 的可能
- feature map 雖然縮小了,依舊可保持影像中的主要特徵
前面卷積層範例如果我們加上 Max-pooling (4x4 filter)看看會變成什麼樣子:


結果就是看起來比較「模糊」,但是整體的樣貌還是可辨識的 (特徵依舊有維持住)。
平坦層 (Flattern Layer)
在 CNN 前面幾層都是卷積層跟池化層互動轉換,後半段會使用多層感知器來穩定判斷結果。所以再接入多層感知器前,先必須將矩陣打平成一維的陣列作為輸入,然後再串到後面的隱藏層跟輸出層。
如果我們把 VGG16 各個 Layer 攤出來看,就長這樣: