Java程式猿之資料庫理論
一、事務的四大特性 ACID
-
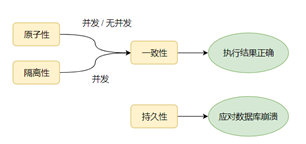
只有滿足一致性,事務的執行結果才是正確的。
-
在無併發的情況下,事務序列執行,隔離性一定能夠滿足。此時要只要能滿足原子性,就一定能滿足一致性。
-
在併發的情況下,多個事務併發執行,事務不僅要滿足原子性,還需要滿足隔離性,才能滿足一致性。
-
事務滿足持久化是為了能應對資料庫奔潰的情況。
1.1 原子性 Atomicity
原子性是指事務是一個不可分割的工作單位,事務中的操作要麼全部成功,要麼全部失敗。比如在同一個事務中的SQL語句,要麼全部執行成功,要麼全部執行失敗。
回滾可以用日誌來實現,日誌記錄著事務所執行的修改操作,在回滾時反向執行這些修改操作即可。
1.2 一致性 Consistency
事務必須使資料庫從一個一致性狀態變換到另外一個一致性狀態。 以轉賬為例子,A向B轉賬,假設轉賬之前這兩個使用者的錢加起來總共是2000,那麼A向B轉賬之後,不管這兩個賬戶怎麼轉,A使用者的錢和B使用者的錢加起來的總額還是2000,這個就是事務的一致性。
1.3 隔離性 Isolation
隔離性是當多個使用者併發訪問資料庫時,比如操作同一張表時,資料庫為每一個使用者開啟的事務,不能被其他事務的操作所幹擾,多個併發事務之間要相互隔離。
即要達到這麼一種效果:對於任意兩個併發的事務 T1 和 T2,在事務 T1 看來,T2 要麼在 T1 開始之前就已經結束,要麼在 T1 結束之後才開始,這樣每個事務都感覺不到有其他事務在併發地執行。
1.4 永續性 Durability
一旦事務提交,則其所做的修改將會永遠儲存到資料庫中。即使系統發生崩潰,事務執行的結果也不能丟失。
可以通過資料庫備份和恢復來實現,在系統發生奔潰時,使用備份的資料庫進行資料恢復。
二、併發一致性問題
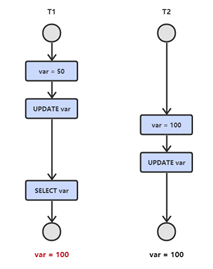
2.1 丟失修改
T1 和 T2 兩個事務都對一個數據進行修改,T1 先修改,T2 隨後修改,T2 的修改覆蓋了 T1 的修改。
2.2 髒讀
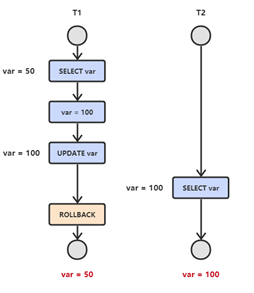
如果一個事務中對資料進行了更新,但事務還沒有提交,另一個事務可以 “看到” 該事務沒有提交的更新結果,這樣造成的問題就是,如果第一個事務回滾,那麼,第二個事務在此之前所 “看到” 的資料就是一筆髒資料。(髒讀又稱無效資料讀出, 一個事務讀取另外一個事務還沒有提交的資料叫髒讀
例子:
- Mary 的原工資為 1000, 財務人員將 Mary 的工資改為了 8000 (但未提交事務)
- Mary 讀取自己的工資,發現自己的工資變為了 8000,歡天喜地!
- 而財務發現操作有誤,回滾了事務,Mary 的工資又變為了1000
- 像這樣,Mary記取的工資數8000是一個髒資料。
解決辦法:
把資料庫的事務隔離級別調整到 READ_COMMITTED
圖解:
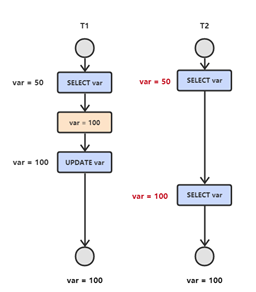
T1 修改一個數據,T2 隨後讀取這個資料。如果 T1 撤銷了這次修改,那麼 T2 讀取的資料是髒資料。
2.3 不可重複讀
是指在一個事務內,多次讀同一資料。在這個事務還沒有結束時,另外一個事務也訪問該同一資料。那麼,在第一個事務中的兩次讀資料之間,由於第二個事務的修改,那麼第一個事務兩次讀到的的資料可能是不一樣的。這樣在一個事務內兩次讀到的資料是不一樣的,因此稱為是不可重複讀。(同時操作,事務1分別讀取事務2操作時和提交後的資料,讀取的記錄內容不一致。不可重複讀是指在同一個事務內,兩個相同的查詢返回了不同的結果。 )
例子:
- 在事務1中,Mary 讀取了自己的工資為1000,操作並沒有完成
- 在事務2中,這時財務人員修改了 Mary 的工資為 2000,並提交了事務
- 在事務1中,Mary 再次讀取自己的工資時,工資變為了2000
解決辦法:
如果只有在修改事務完全提交之後才可以讀取資料,則可以避免該問題。把資料庫的事務隔離級別調整到REPEATABLE_READ
圖解:
T2 讀取一個數據,T1 對該資料做了修改。如果 T2 再次讀取這個資料,此時讀取的結果和第一次讀取的結果不同。
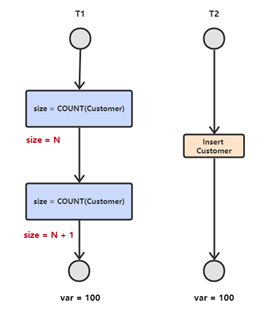
2.4 幻讀
事務 T1 讀取一條指定的 Where 子句所返回的結果集,然後 T2 事務新插入一行記錄,這行記錄恰好可以滿足T1 所使用的查詢條件。然後 T1 再次對錶進行檢索,但又看到了 T2 插入的資料。 (和可重複讀類似,但是事務 T2 的資料操作僅僅是插入和刪除,不是修改資料,讀取的記錄數量前後不一致)。幻讀的重點在於新增或者刪除 (資料條數變化),同樣的條件,第1次和第2次讀出來的記錄數不一樣。
例子:
- 事務1,讀取所有工資為 1000 的員工(共讀取 10 條記錄 )
- 這時另一個事務向 employee 表插入了一條員工記錄,工資也為 1000
- 事務1再次讀取所有工資為 1000的 員工(共讀取到了 11 條記錄,這就產生了幻讀)
解決辦法:
如果在操作事務完成資料處理之前,任何其他事務都不可以新增新資料,則可避免該問題。把資料庫的事務隔離級別調整到 SERIALIZABLE_READ
圖解:
T1 讀取某個範圍的資料,T2 在這個範圍內插入新的資料,T1 再次讀取這個範圍的資料,此時讀取的結果和和第一次讀取的結果不同。
三、事務隔離級別
| 讀資料一致性及允許的併發副作用隔離級別 | 讀資料一致性 | 髒讀 | 不可重複讀 | 幻讀 |
|---|---|---|---|---|
| 未提交讀 | 最低級別,只能保證不讀取物理上損壞的資料 | Y | Y | Y |
| 已提交讀 | 語句級 | N | Y | Y |
| 可重複讀 | 事務級 | N | N | Y |
| 可序列化 | 最高級別,事務級 | N | N | N |
3.1 未提交讀 Read Uncommitted
最低的隔離等級,允許其他事務看到沒有提交的資料,會導致髒讀。
3.2 已提交讀 Read Committed
被讀取的資料可以被其他事務修改,這樣可能導致不可重複讀。也就是說,事務讀取的時候獲取讀鎖,但是在讀完之後立即釋放(不需要等事務結束),而寫鎖則是事務提交之後才釋放,釋放讀鎖之後,就可能被其他事務修改資料。該等級也是 SQL Server 預設的隔離等級。
3.3 可重複讀 Repeated Read
所有被選中獲取的資料都不能被修改,這樣就可以避免一個事務前後讀取資料不一致的情況。但是卻沒有辦法控制幻讀,因為這個時候其他事務不能更改所選的資料,但是可以增加資料,即前一個事務有讀鎖但是沒有範圍鎖,為什麼叫做可重複讀等級呢?那是因為該等級解決了下面的不可重複讀問題。
引申:現在主流資料庫都使用 MVCC 併發控制,使用之後RR(可重複讀)隔離級別下是不會出現幻讀的現象。
3.4 序列化 Serializable
所有事務一個接著一個的執行,這樣可以避免幻讀 (phantom read),對於基於鎖來實現併發控制的資料庫來說,序列化要求在執行範圍查詢的時候,需要獲取範圍鎖,如果不是基於鎖實現併發控制的資料庫,則檢查到有違反序列操作的事務時,需回滾該事務。
四、MyISAM VS InnoDB
| 對比項 | MyISAM | InnoDB |
|---|---|---|
| 主外來鍵 | N | Y |
| 事務 | N | Y |
| 行表鎖 | 表鎖,即使操作一條記錄也會鎖住整個表,不適合高併發操作 | 行鎖,操作時只鎖某一行,不對其他行有影響,適合高併發操作 |
| 快取 | 只快取索引,不快取真實資料 | 不僅快取索引還快取真實資料,對記憶體要求較高,而且記憶體大小對效能有決定性的影響 |
| 表空間 | 小 | 大 |
| 關注點 | 效能 | 事務 |
| 預設安裝 | Y | Y |
五、鎖機制
5.1 樂觀鎖、悲觀鎖
1.樂觀鎖
顧名思義,就是很樂觀,每次去拿資料的時候都認為別人不會修改,所以不會上鎖,但是在更新的時候會判斷一下在此期間別人有沒有去更新這個資料,可以使用版本號等機制。
樂觀鎖適用於多讀的應用型別,這樣可以提高吞吐量,像資料庫如果提供類似於write_condition機制的其實都是提供的樂觀鎖。
2.悲觀鎖
顧名思義,就是很悲觀,每次去拿資料的時候都認為別人會修改,所以每次在拿資料的時候都會上鎖,這樣別人想拿這個資料就會block直到它拿到鎖。
傳統的關係型資料庫裡邊就用到了很多這種鎖機制,比如行鎖,表鎖等,讀鎖,寫鎖等,都是在做操作之前先上鎖。
5.2 表鎖
1.表共享讀鎖(Table Read Lock)
對MyISAM表進行讀操作時,它不會阻塞其他使用者對同一表的讀請求,但會阻塞對同一表的寫操作。
2.表獨佔寫鎖(Table Write Lock)
對MyISAM表的寫操作,則會阻塞其他使用者對同一表的讀和寫操作。
5.3 行鎖
1.共享鎖(S)
共享鎖又稱為讀鎖。若事務T對資料物件A加上S鎖,則事務T可以讀A但不能修改A,其他事務只能再對A加S鎖,而不能加X鎖,直到T釋放A上的S鎖。這就保證了其他事務可以讀A,但在T釋放A上的S鎖之前不能對A做任何修改。
2.排他鎖(X)
排它鎖又稱為寫鎖。若事務T對資料物件A加上X鎖,則允許T讀取和修改A,其他任何事務都不能再對A加任何型別的鎖,直到T釋放A上的鎖。這就保證了其他事務在T釋放A上的鎖之前不能再讀取和修改A
六、索引
索引(Index)是幫助MySQL高效獲取資料的資料結構,可以被理解為排好序的快速查詢資料結構。
一般來說索引本身也很大,不可能全部儲存在記憶體中,因此索引往往以索引檔案的形式儲存在磁碟上。
我們通常所說的索引,如果沒有特別指明,都是指B樹(多路搜尋樹,並不一定是二叉的)結構組織的索引。其中聚集索引、次要索引、覆蓋索引、混合索引、字首索引、唯一索引預設都是使用B+樹索引,統稱索引。
6.1 索引的特點
- 可以加快資料庫的檢索速度
- 降低資料庫插入、修改、刪除等維護的速度
- 只能建立在表上,不能建立到檢視上
- 既可以直接建立又可以間接建立
- 可以在優化隱藏中使用索引
- 使用查詢處理器執行SQL語句,在一個表上,一次只能使用一個索引
6.2 索引的優點
- 建立唯一性索引,保證資料庫表中每一行資料的唯一性
- 大大加快資料的檢索速度,這是建立索引的最主要的原因
- 加速資料庫表之間的連線,特別是在實現資料的參考完整性方面特別有意義
- 在使用分組和排序子句進行資料檢索時,同樣可以顯著減少查詢中分組和排序的時間
- 通過使用索引,可以在查詢中使用優化隱藏器,提高系統的效能
6.3 索引的缺點
- 建立索引和維護索引要耗費時間,這種時間隨著資料量的增加而增加
- 索引需要佔用物理空間,除了資料表佔用資料空間之外,每一個索引還要佔一定的物理空間,如果建立聚簇索引,那麼需要的空間就會更大
- 當對錶中的資料進行增加、刪除和修改的時候,索引也需要維護,降低資料維護的速度
6.4 不會使用索引的時機
- 如果MySQL估計使用全表掃秒比使用索引快,則不適用索引。
select * from table_name where key>1 and key<90;
//如果列key均勻分佈在1和100之間,這個查詢使用索引就不是很好
- 如果條件中有or,即使其中有條件帶索引也不會使用。
select * from table_name where key1='a' or key2='b';
//在key1上有索引而在key2上沒有索引,則該查詢也不會走索引
- 複合索引,如果索引列不是複合索引的第一部分,則不使用索引(即不符合最左字首)。
select * from table_name where key2='b';
//符合索引為(key1,key2),則查詢將不會使用索引
- 如果like是以 % 開始的,則該列上的索引不會被使用。
select * from table_name where key1 like '%a';
//該查詢即使key1上存在索引,也不會被使用如果列型別是字串,那一定要在條件中使用引號引起來,否則不會使用索引
- 如果列為字串,則where條件中必須將字元常量值加引號,否則即使該列上存在索引,也不會被使用。
select * from table_name where key1=1;
//如果key1列儲存的是字串,即使key1上有索引,也不會被使用。
6.5 適合建立索引的時機
- 為經常出現在關鍵字order by、group by、distinct後面的欄位,建立索引。
- 在union等集合操作的結果集欄位上,建立索引。
- 經常用作查詢選擇 where 後的欄位,建立索引。
- 在經常用作表連線 join 的屬性上,建立索引。
- 考慮使用索引覆蓋。對資料很少被更新的表,如果使用者經常只查詢其中的幾個欄位,可以考慮在這幾個欄位上建立索引,從而將表的掃描改變為索引的掃描。
6.6 索引分類
6.6.1 單值索引
即一個索引只包含單個列,一個表可以有多個單值索引。
6.6.2 唯一索引
索引列的值必須唯一,但允許有空值。
6.6.3 聯合索引
兩個或更多個列上的索引被稱作聯合索引,聯合索引又叫複合索引。對於複合索引:Mysql 從左到右的使用索引中的欄位,一個查詢可以只使用索引中的一部份,但只能是最左側部分。
例如索引是key index (a,b,c),可以支援[a]、[a,b]、[a,b,c] 3種組合進行查詢,但不支 [b,c] 進行查詢。當最左側欄位是常量引用時,索引就十分有效。
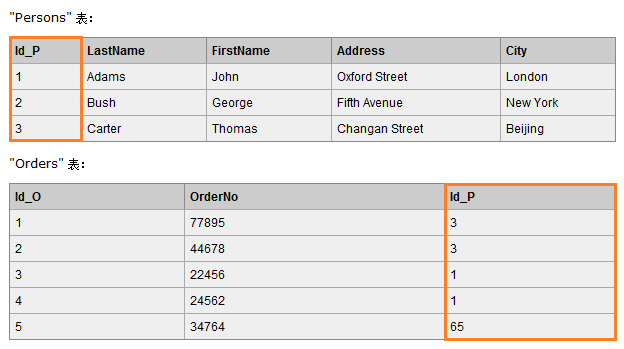
七、JOIN
例如我們有兩張表,Orders 表通過外來鍵 Id_P 和 Persons 表進行關聯。
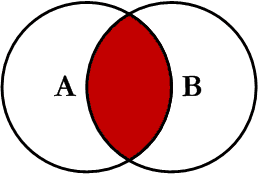
7.1 inner join
在兩張表進行連線查詢時,只保留兩張表中完全匹配的結果集。
我們使用 inner join 對兩張表進行連線查詢,sql如下:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
INNER JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName
查詢結果集如下,此種連線方式 Orders 表中 Id_P 欄位在 Persons 表中找不到匹配的,則不會列出來。

7.2 left join
在兩張表進行連線查詢時,會返回左表所有的行,即使在右表中沒有匹配的記錄。
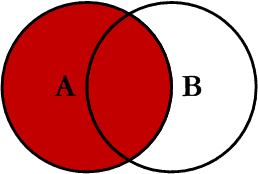
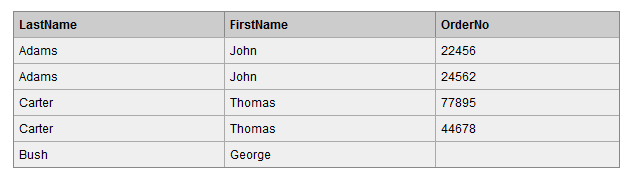
我們使用 left join 對兩張表進行連線查詢,sql如下:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
LEFT JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName
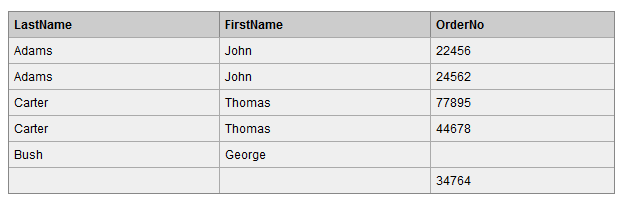
查詢結果如下,可以看到,左表(Persons表)中 LastName 為 Bush 的行的 Id_P 欄位在右表(Orders表)中沒有匹配,但查詢結果仍然保留該行。
7.3 right join
在兩張表進行連線查詢時,會返回右表所有的行,即使在左表中沒有匹配的記錄。
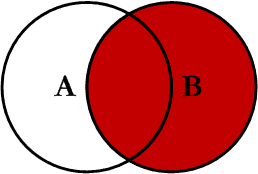
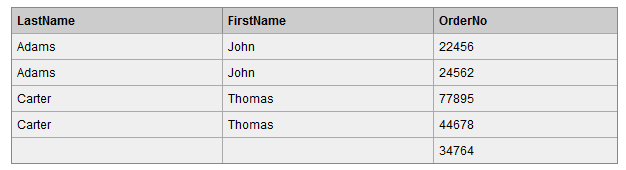
我們使用right join對兩張表進行連線查詢,sql如下:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
RIGHT JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName
查詢結果如下,Orders 表中最後一條記錄 Id_P 欄位值為 65,在左表中沒有記錄與之匹配,但依然保留。
7.4 full join
在兩張表進行連線查詢時,返回左表和右表中所有沒有匹配的行。
我們使用 full join 對兩張表進行連線查詢,sql如下:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
FULL JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName
查詢結果如下,查詢結果是 left join 和 right join 的並集。