pandas中apply和transform方法的效能比較
1. apply與transform
首先講一下apply() 與transform()的相同點與不同點
相同點:
都能針對dataframe完成特徵的計算,並且常常與groupby()方法一起使用。
不同點:
apply()裡面可以跟自定義的函式,包括簡單的求和函式以及複雜的特徵間的差值函式等(注:apply不能直接使用agg()方法 / transform()中的python內建函式,例如sum、max、min、’count‘等方法)
transform() 裡面不能跟自定義的特徵互動函式,因為transform是真針對每一元素(即每一列特徵操作)進行計算,也就是說在使用 transform() 方法時,需要記得三點:
1、它只能對每一列進行計算,所以在groupby()之後,.transform()之前是要指定要操作的列,這點也與apply有很大的不同。
2、由於是隻能對每一列計算,所以方法的通用性相比apply()就侷限了很多,例如只能求列的最大/最小/均值/方差/分箱等操作
3、transform還有什麼用呢?最簡單的情況是試圖將函式的結果分配回原始的dataframe。也就是說返回的shape是(len(df),1)。注:如果與groupby()方法聯合使用,需要對值進行去重
2. 各方法耗時
分別計算在同樣簡單需求下各組合方法的計算時長
2.1 transform() 方法+自定義函式

2.2 transform() 方法+python內建方法

2.3 apply() 方法+自定義函式

2.4 agg() 方法+自定義函式

2.5 agg() 方法+python內建方法
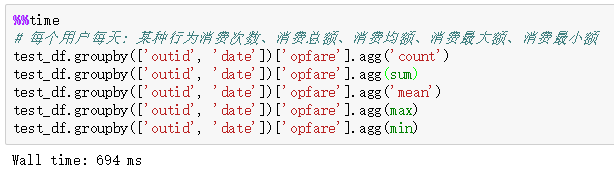
2.6 結論
- agg()+python內建方法的計算速度最快,其次是transform()+python內建方法。而 transform() 方法+自定義函式 的組合方法最慢,需要避免使用!
- 而下面兩圖中紅框內容可觀察發現:python自帶的stats統計模組在pandas結構中的計算也非常慢,也需要避免使用!


3. 例項分析
需求:計算每個使用者每天
某種行為消費次數、消費總額、消費均額、消費最大額、消費最小額
在幾個終端支付、最常支付終端號、最常支付終端號的支付次數、最少支付終端號、最少支付終端號的支付次數
某種行為最常消費發生時間段、最常消費發生時間段的消費次數、最少消費發生時間段、最少消費發生時間段的消費次數
某種行為最早消費時間、最晚消費時間
原始資料資訊:306626 x 9

具體選擇哪種方法處理,根據實際情況確定,在面對複雜計算時,transform() 與apply()結合使用往往會有意想不到的效果!
需要注意的是,在與apply()一起使用時,transform需要進行去重操作,一般是通過指定一或多個列完成。
此外,匿名函式永遠不是一個很好的辦法,在進行簡單計算時,無論是使用transfrom、agg還是apply,都要儘可能使用自帶方法!!!
4. 小技巧
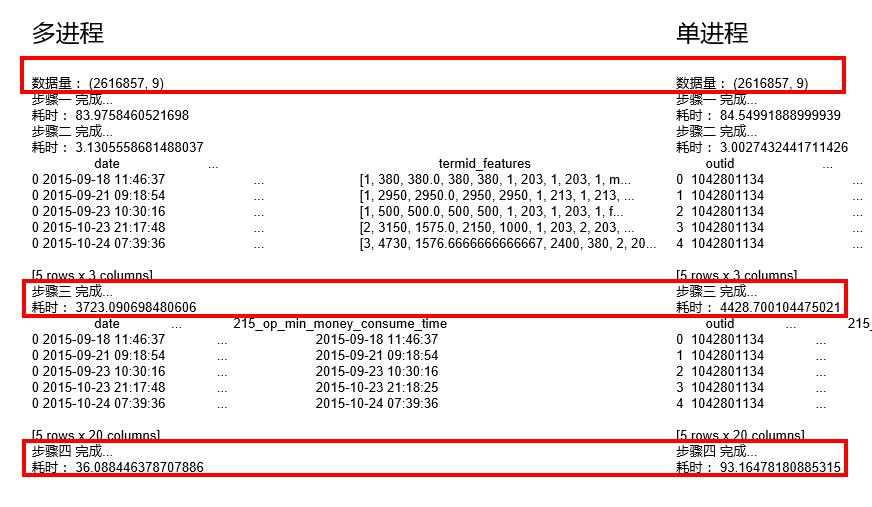
在使用apply()方法處理大資料級時,可以考慮使用joblib中的多執行緒/多程序模組構造相應函式執行計算,以下分別是採用多程序和單程序的耗時時長。
可以看到,在260W的資料集上,多程序比單程序的計算速度可以提升約17%~61% 。