
人臉識別中的活體檢測演算法
人臉識別中的活體檢測演算法綜述
1. 什麼是活體檢測?
判斷捕捉到的人臉是真實人臉,還是偽造的人臉攻擊(如:彩色紙張列印人臉圖,電子裝置螢幕中的人臉數字影象 以及 面具 等)
2. 為什麼需要活體檢測?
在金融支付,門禁等應用場景,活體檢測一般是巢狀在人臉檢測與人臉識別or驗證中的模組,用來驗證是否使用者真實本人
3. 活體檢測對應的計算機視覺問題:
就是分類問題,可看成二分類(真 or 假);也可看成多分類(真人,紙張攻擊,螢幕攻擊,面具攻擊)
Anti-spoofing 1.0 時代
從早期 handcrafted 特徵的傳統方法說起,目標很明確,就是找到活體與非活體攻擊的difference,然後根據這些差異來設計特徵,最後送給分類器去決策。
那麼問題來了,活體與非活體有哪些差異?
所以這段時期的文章都是很有針對性地設計特徵,列舉幾篇比較重要的:
Image Distortion Analysis[1], 2015
如下圖,單幀輸入的方法,設計了 鏡面反射+影象質量失真+顏色 等統計量特徵,合併後直接送SVM進行二分類。
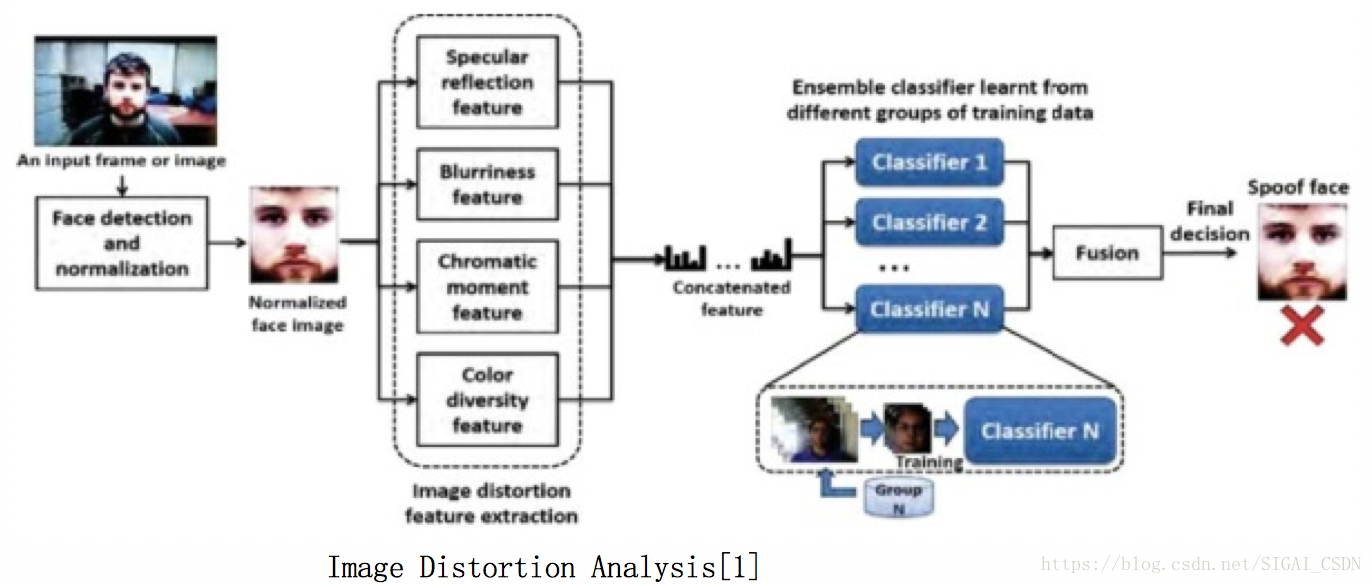
Cons: 對於高清彩色列印的紙張 or 高清錄製視訊,質量失真不嚴重時,難區分開
Colour Texture[2], 2016
Oulu CMVS組的產物,算是傳統方法中的戰鬥機,特別簡潔實用,Matlab程式碼(課題組官網有),很適合搞成C++部署到門禁系統。
原理:活體與非活體,在RGB空間裡比較難區分,但在其他顏色空間裡的紋理有明顯差異
演算法:HSV空間人臉多級LBP特徵 + YCbCr空間人臉LPQ特徵 (後在17年的paper拓展成用Color SURF特徵[12],效能提升了一點)
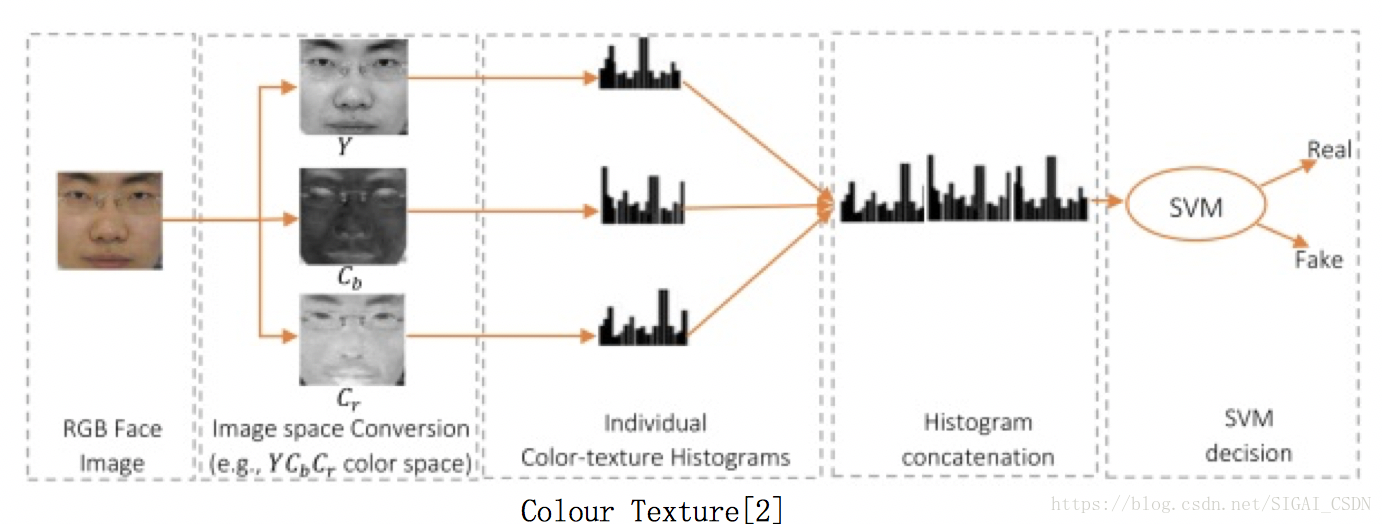
Pros: 演算法簡潔高效易部署;也證明了活體與非活體在 HSV等其他空間也是 discriminative,故後續深度學習方法有將HSV等channel也作為輸入來提升效能。
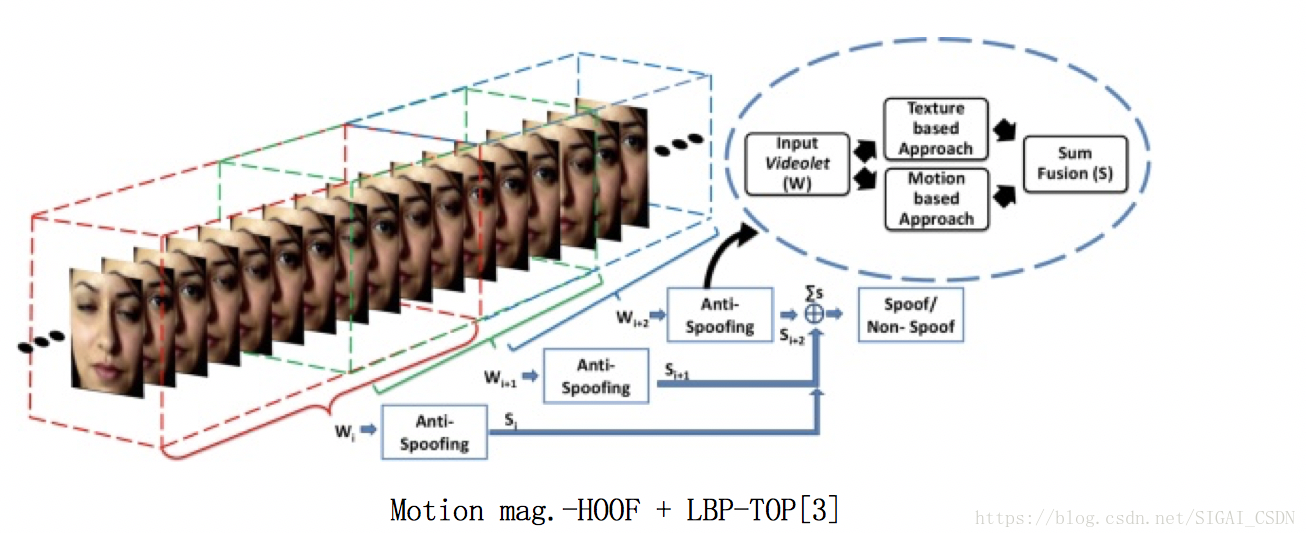
Motion mag.-HOOF + LBP-TOP[3], 2014
DMD + LBP[4], 2015
前面說的都是單幀方法,這兩篇文章輸入的是連續多幀人臉圖;
主要通過捕獲活體與非活體微動作之間的差異來設計特徵。
一個是先通過運動放大來增強臉部微動作, 然後提取方向光流直方圖HOOF + 動態紋理LBP-TOP 特徵;一個是通過動態模式分解DMD,得到最大運動能量的子空間圖,再分析紋理。
PS:這個 motion magnification 的預處理很差勁,加入了很多其他頻段噪聲(18年新出了一篇用 Deep learning 來搞 Motion mag[13]. 看起來效果挺好,可以嘗試用那個來做運動增強,再來光流or DMD)
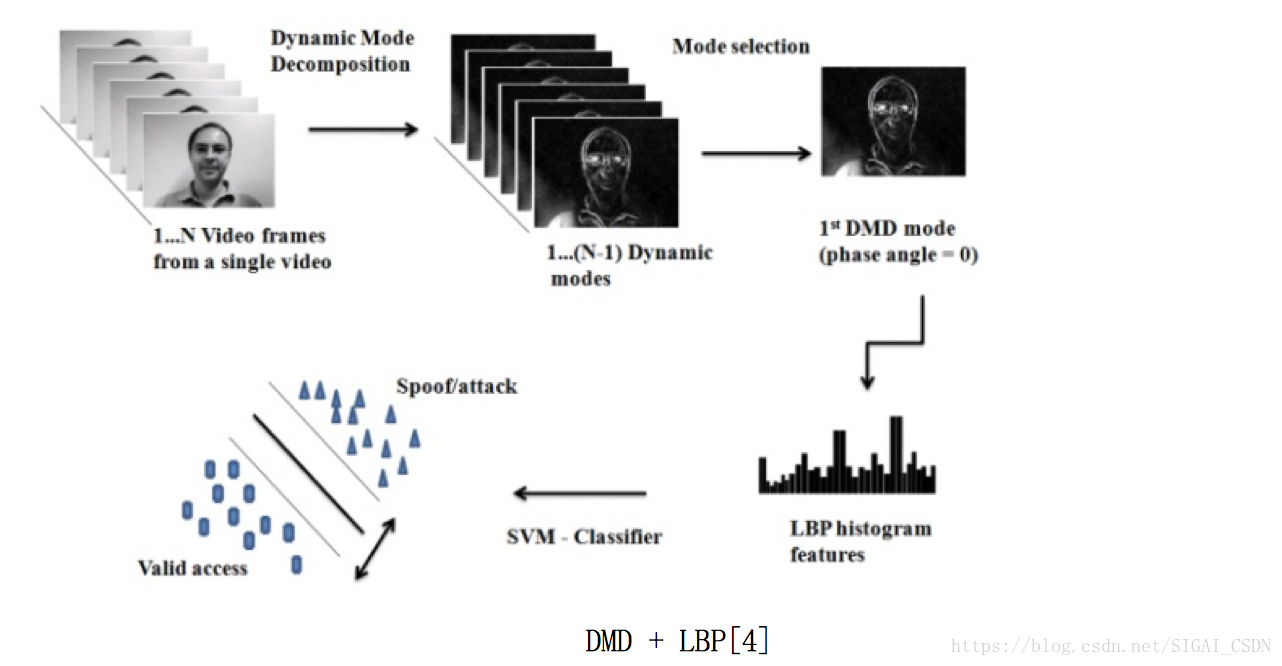
DMD + LBP[4]
Cons: 基於Motion的方法,對於 仿人臉wrapped紙張抖動 和 視訊攻擊,效果不好;因為它假定了活體與非活體之間的非剛性運動有明顯的區別,但其實這種微動作挺難描述與學習~
Pulse + texture[5], 2016
第一個將 remote pluse 應用到活體檢測中,多幀輸入
(交代下背景:在CVPR2014,Xiaobai Li[14] 已經提出了從人臉視訊裡測量心率的方法)
演算法流程:
1. 通過 pluse 在頻域上分佈不同先區分 活體 or 照片攻擊 (因為照片中的人臉提取的心率分佈不同)
2. 若判別1結果是活體,再 cascade 一個 紋理LBP 分類器,來區分 活體 or 螢幕攻擊(因為螢幕視訊中人臉心率分佈與活體相近)
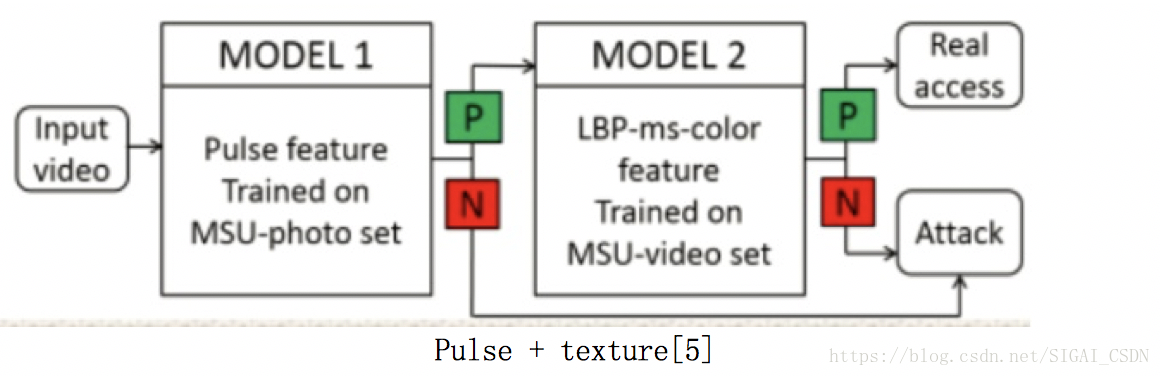
Pros: 從學術界來說,引入了心理訊號這個新模態,很是進步;從工業界來看,如果不能一步到位,針對每種型別攻擊,也可進行 Cascade 對應的特徵及分類器的部署方式
Cons: 由於 remote heart rate 的演算法本來魯棒性也一般,故出來的 pulse-feature 的判別效能力很不能保證;再者螢幕video裡的人臉視訊出來的 pulse-feature 是否也有微小區別,還待驗證~
Anti-spoofing 2.0 時代
其實用 Deep learning 來做活體檢測,從15年陸陸續續就有人在研究,但由於公開資料集樣本太少,一直效能也超越不了傳統方法:
CNN-LSTM[6], 2015
多幀方法,想通過 CNN-LSTM 來模擬傳統方法 LBP-TOP,效能堪憂~
PatchNet pretrain[7],CNN finetune, 2017
單幀方法,通過人臉分塊,pre-train 網路;然後再在 global 整個人臉圖 fine-tune,作用不大
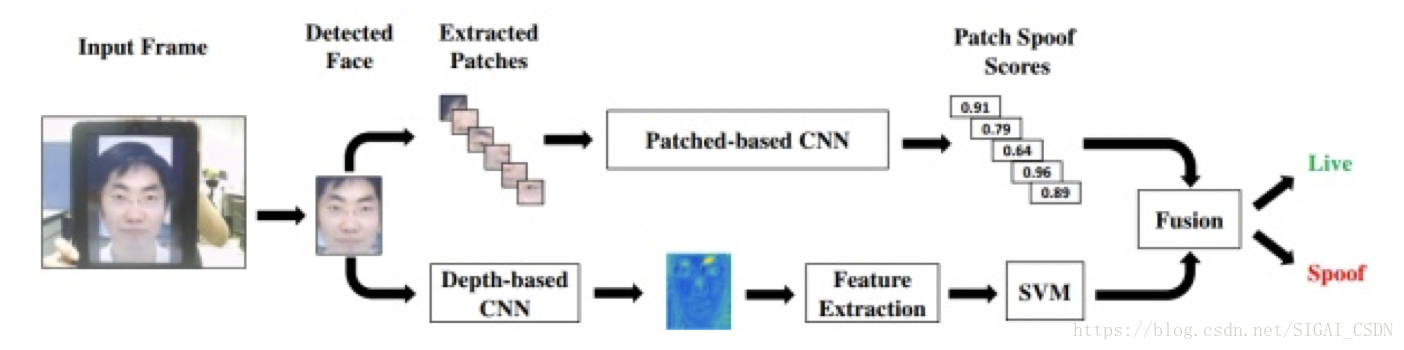
Patch and Depth-Based CNNs[8], 2017
第一個考慮把 人臉深度圖 作為活體與非活體的差異特徵,因為像螢幕中的人臉一般是平的,而紙張中的人臉就算扭曲,和真人人臉的立體分佈也有差異;
就算用了很多 tricks 去 fusion,效能還是超越不了傳統方法。。。
Deep Pulse and Depth[9], 2018
發表在 CVPR2018 的文章,終於超越了傳統方法效能。
文章[8]的同一組人,設計了深度框架 準端到端 地去預測 Pulse統計量 及 Depth map (這裡說的“準”,就是最後沒接分類器,直接通過樣本 feature 的相似距離,閾值決策)
在文章中明確指明:
- 過去方法把活體檢測看成二分類問題,直接讓DNN去學習,這樣學出來的cues不夠general 和 discriminative
- 將二分類問題換成帶目標性地特徵監督問題,即 迴歸出 pulse 統計量 + 迴歸出 Depth map,保證網路學習的就是這兩種特徵(哈哈,不排除假設學到了 color texture 在裡面,黑箱網路這麼聰明
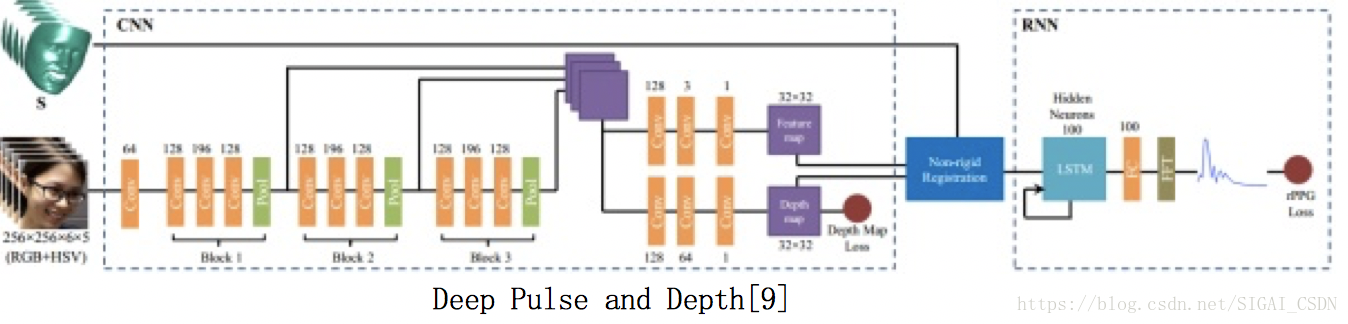
迴歸 Depth map,跟文章[8]中一致,就是通過 Landmark 然後 3DMMfitting 得到 人臉3D shape,然後再閾值化去背景,得到 depth map 的 groundtruth,最後和網路預測的 estimated depth map 有 L2 loss。
而文章亮點在於設計了 Non-rigid Registration Layer 來對齊各幀人臉的非剛性運動(如姿態,表情等),然後通過RNN更好地學到 temporal pulse 資訊。
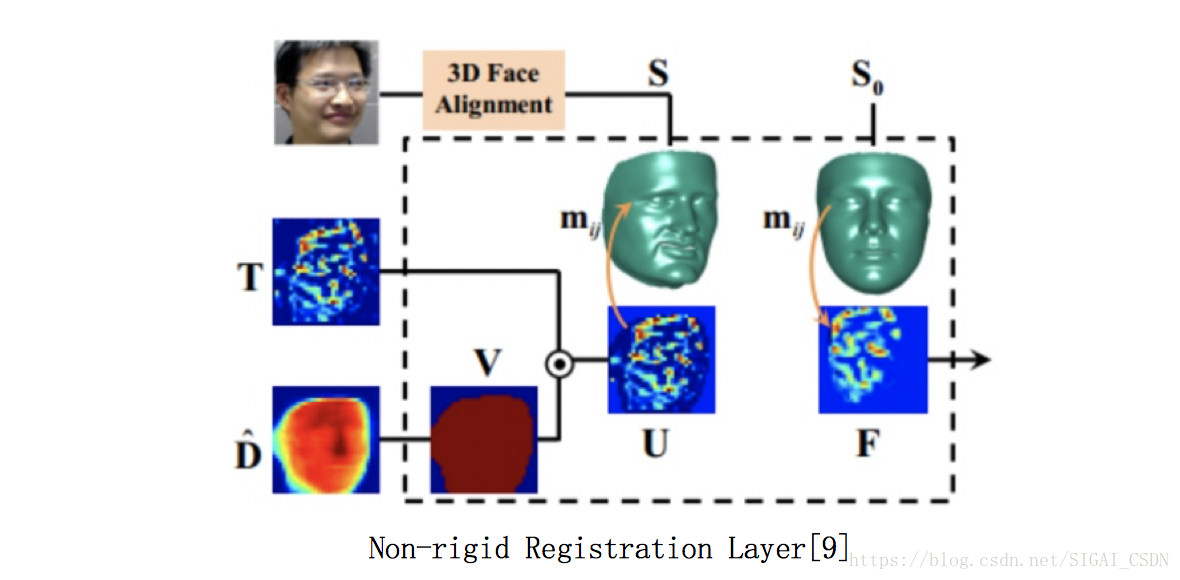
為什麼需要這個對齊網路呢?我們來想想,在做運動識別任務時,只需簡單把 sampling或者連續幀 合併起來喂進網路就行了,是假定相機是不動的,物件在運動;而文中需要對連續人臉幀進行pulse特徵提取,主要物件是人臉上對應ROI在 temporal 上的 Intensity 變化,所以就需要把人臉當成是相機固定不動。
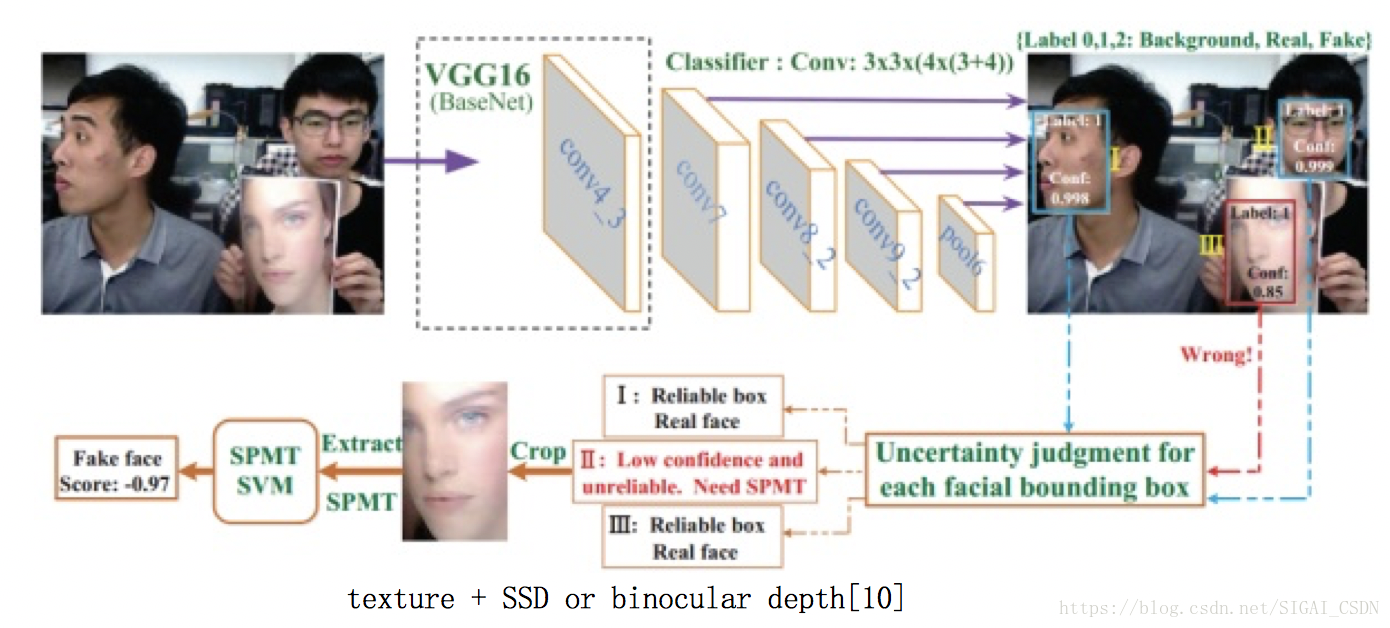
Micro-texture + SSD or binocular depth[10] , 2018
ArXiv 剛掛出不久的文章,最大的貢獻是把 活體檢測 直接放到 人臉檢測(SSD,MTCNN等) 模組裡作為一個類,即人臉檢測出來的 bbox 裡有 背景,真人人臉,假人臉 三類的置信度,這樣可以在早期就過濾掉一部分非活體。
所以整個系統速度非常地快,很適合工業界部署~
至於後續手工設計的 SPMT feature 和 TFBD feature 比較複雜繁瑣,分別是表徵 micro-texture 和 stereo structure of face,有興趣的同學可以去細看。
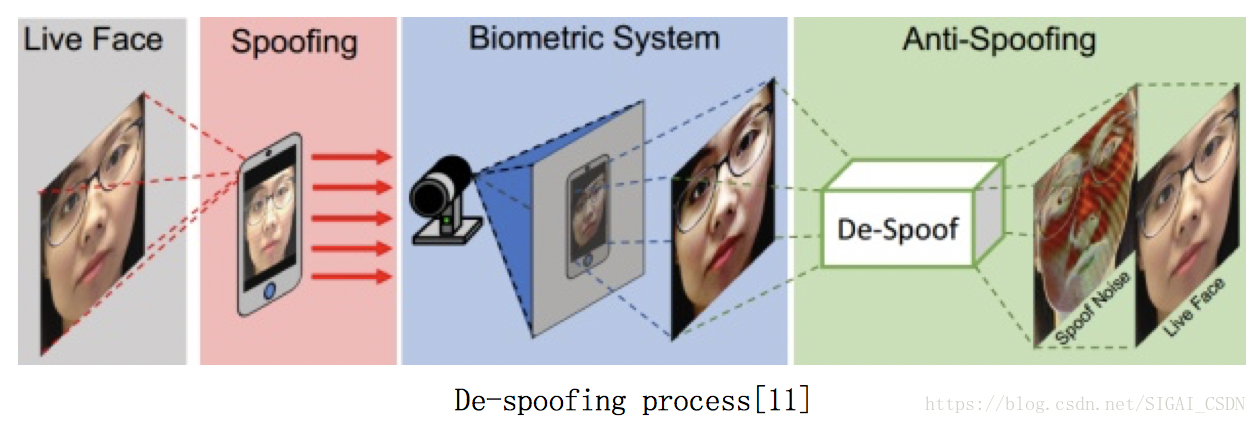
De-Spoofing[11], ECCV2018
單幀方法,與Paper[8]和[9]一樣,是MSU一個課題組做的。
文章的idea很有趣,啟發於影象去噪denoise 和 影象去抖動 deblur。無論是噪聲圖還是模糊圖,都可看成是在原圖上加噪聲運算或者模糊運算(即下面的公式),而去噪和去抖動,就是估計噪聲分佈和模糊核,從而重構回原圖。
文中把活體人臉圖看成是原圖 ,而非活體人臉圖看成是加了噪聲後失真的 x ,故 task 就變成估計 Spoof noise
,然後用這個 Noise pattern feature 去分類決策。
那問題來了,資料集沒有畫素級別一一對應的 groundtruth,也沒有Spoof Noise模型的先驗知識(如果有知道Noise模型,可以用Live Face來生成Spoofing Face),那拿什麼來當groundtruth,怎麼設計網路去估計 Spoofing noise 呢?
如一般Low-level image 任務一樣,文中利用Encoder-decoder來得到 Spoof noise N,然後通過殘差重構出 ,這就是下圖的DS Net。為了保證網路對於不同輸入,學出來的Noise是有效的,根據先驗知識設計了三個Loss來constrain:
Magnitude loss(當輸入是Live face時,N儘量逼近0);
Repetitive loss(Spooing face的Noise圖在高頻段有較大的峰值);
0\1Map Loss(讓Real Face 的 deep feature map分佈儘量逼近全0,而Spoofing face的 deep feature map 儘量逼近全1)
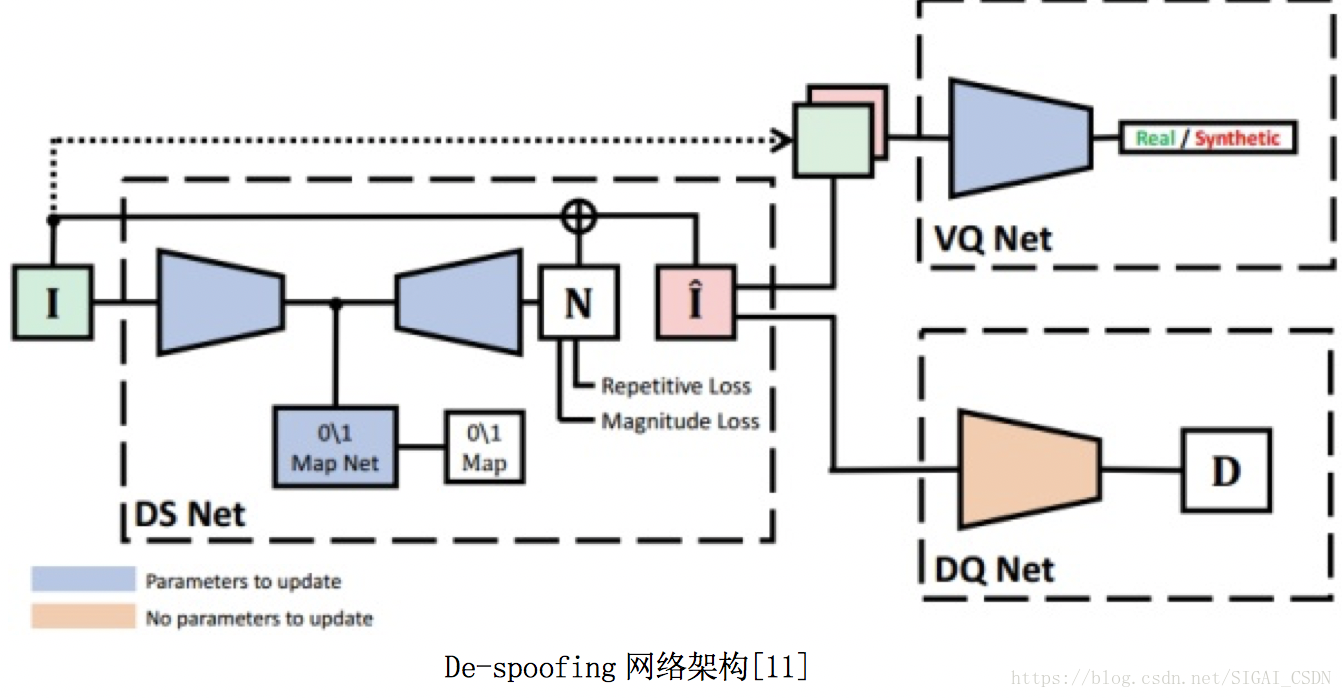
那網路右邊的 VQ-Net 和 DQ-Net 又有什麼作用呢?因為沒有 Live face 的 Groundtruth,要保證重構出來的分佈接近 Live face,作者用了對抗生成網路GAN (即 VQ-Net )去約束重構生成的 與Live face分佈儘量一致;而用了文章[8]中的 pre-trained Depth model 來保證
的深度圖與Live face的深度圖儘量一致。
Pros: 通過視覺化最終讓大眾知道了 Spoofing Noise 是長什麼樣子的~
Cons: 在實際場景中難部署(該模型假定Spoofing Noise是 strongly 存在的,當實際場景中活體的人臉圖質量並不是很高,而非活體攻擊的質量相對高時,Spoofing noise走不通)
後記:不同模態的相機輸入對於活體檢測的作用
- 近紅外NIR
由於NIR的光譜波段與可見光VIS不同,故真實人臉及非活體載體對於近紅外波段的吸收和反射強度也不同,即也可通過近紅外相機出來的影象來活體檢測。從出來的影象來說,近紅外影象對螢幕攻擊的區分度較大,對高清彩色紙張列印的區分度較小。
從特徵工程角度來說,方法無非也是提取NIR圖中的光照紋理特徵[15]或者遠端人臉心率特徵[16]來進行。下圖可見,上面兩行是真實人臉圖中人臉區域與背景區域的直方圖分佈,明顯與下面兩行的非活體圖的分佈不一致;而通過與文章[5]中一樣的rPPG提取方法,在文章[]中說明其在NIR影象中出來的特徵更加魯棒~
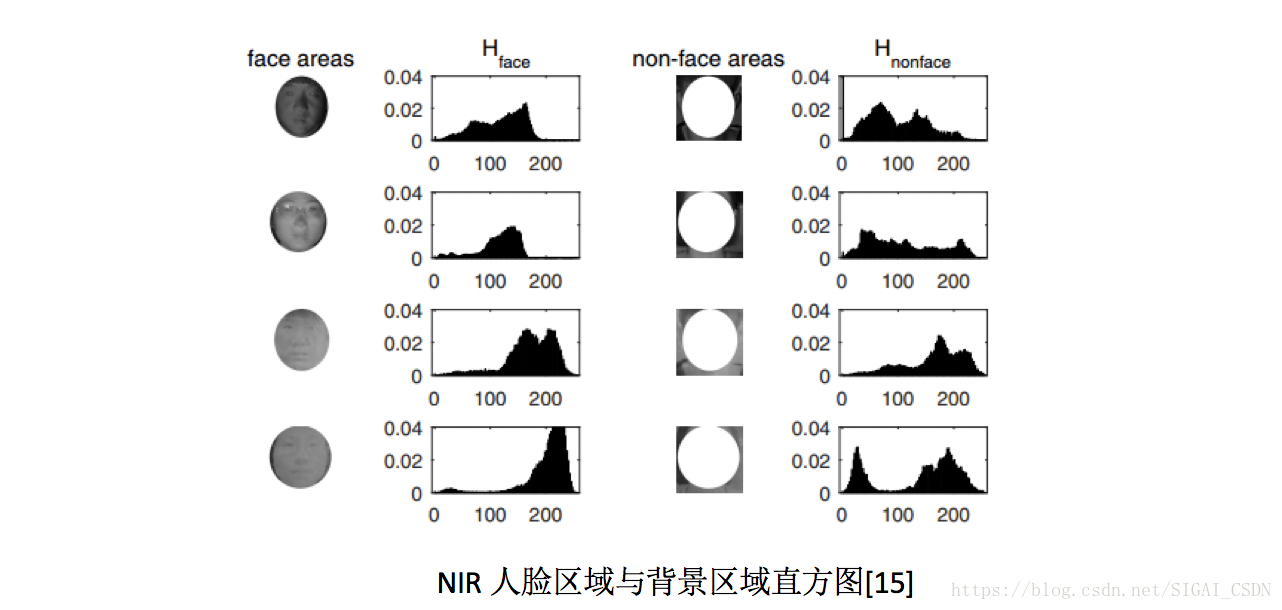
NIR人臉區域與背景區域直方圖[15]
- 結構光/ToF
由於結構光及ToF能在近距離裡相對準確地進行3D人臉重構,即可得到人臉及背景的點雲圖及深度圖,可作為精準活體檢測(而不像單目RGB或雙目RGB中仍需估計深度)。不過就是成本較高,看具體應用場景決定。
- 光場 Light field
光場相機具有光學顯微鏡頭陣列,且由於光場能描述空間中任意一點向任意方向的光線強度,出來的raw光場照片及不同重聚焦的照片,都能用於活體檢測:
3.1 raw光場照片及對應的子孔徑照片[17]
如下圖所示,對於真實人臉的臉頰邊緣的微鏡影象,其畫素應該是帶邊緣梯度分佈;而對應紙張列印或螢幕攻擊,其邊緣畫素是隨機均勻分佈:
3.2 使用一次拍照的重聚焦影象[18]
原理是可以從兩張重聚焦影象的差異中,估計出深度資訊;從特徵提取來說,真實人臉與非活體人臉的3D人臉模型不同,可提取差異影象中的 亮度分佈特徵+聚焦區域銳利程度特徵+頻譜直方圖特徵。

至此,Face anti-spoofing 的簡單Survey已完畢~
毫無疑問,對於學術界,後續方向應該是用DL學習更精細的 人臉3D特徵 和 人臉微變化微動作(Motion Spoofing Noise?) 表徵;而也可探索活體檢測與人臉檢測及人臉識別之間更緊密的關係。
對於工業界,可直接在人臉檢測時候預判是否活體;更可藉助近紅外,結構光/ToF等硬體做到更精準。
Reference:
[1] Di Wen, Hu Han, Anil K. Jain. Face Spoof Detection with Image Distortion Analysis. IEEE Transactions on Information Forensics and Security, 2015
[2] Zinelabidine Boulkenafet, Jukka Komulainen, Abdenour Hadid. Face Spoofing Detection Using Colour Texture Analysis. IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, 2016
[3] Samarth Bharadwaj. Face Anti-spoofing via Motion Magnification and
Multifeature Videolet Aggregation, 2014
[4] Santosh Tirunagari, Norman Poh. Detection of Face Spoofing Using Visual Dynamics. IEEE TRANS. ON INFORMATION FORENSICS AND SECURIT, 2015
[5] Xiaobai Li, , Guoying Zhao. Generalized face anti-spoofing by detecting pulse
from face videos, 2016 23rd ICPR
[6] Zhenqi Xu. Learning Temporal Features Using LSTM-CNN Architecture for Face Anti-spoofing, 2015 3rd IAPR
[7] Gustavo Botelho de Souza, On the Learning of Deep Local Features for
Robust Face Spoofing Detection, 2017
[8] Yousef Atoum, Xiaoming Liu. Face Anti-Spoofing Using Patch and Depth-Based CNNs, 2017
[9] Yaojie Liu, Amin Jourabloo, Xiaoming Liu, Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision ,CVPR2018
[10] Discriminative Representation Combinations for Accurate Face Spoofing Detection,2018 PR
[11] Amin Jourabloo, Face De-Spoofing: Anti-Spoofing via Noise Modeling, ECCV2018
[12]Zinelabidine Boulkenafet, Face Antispoofing Using Speeded-Up Robust Features and Fisher Vector Encoding, IEEE SIGNAL PROCESSING LETTERS, VOL. 24, NO. 2, FEBRUARY 2017
[13]Tae-Hyun Oh, Learning-based Video Motion Magnification, ECCV2018
[14]Xiaobai Li, Remote Heart Rate Measurement From Face Videos Under Realistic Situations
[15]Xudong Sun, Context Based Face Spoofing Detection Using Active Near-Infrared Images, ICPR 2016
[16]Javier Hernandez-Ortega, Time Analysis of Pulse-based Face Anti-Spoofing in Visible and NIR, CVPR2018 workshop
[17]Sooyeon Kim, Face Liveness Detection Using a Light Field Camera, 2014
[18]Xiaohua Xie, One-snapshot Face Anti-spoofing Using a Light Field Camera, 2017
推薦閱讀
[1]機器學習-波瀾壯闊40年【獲取碼】SIGAI0413.
[2]學好機器學習需要哪些數學知識?【獲取碼】SIGAI0417.
[3] 人臉識別演算法演化史【獲取碼】SIGAI0420.
[4]基於深度學習的目標檢測演算法綜述 【獲取碼】SIGAI0424.
[5]卷積神經網路為什麼能夠稱霸計算機視覺領域?【獲取碼】SIGAI0426.
[6] 用一張圖理解SVM的脈絡【獲取碼】SIGAI0428.
[7] 人臉檢測演算法綜述【獲取碼】SIGAI0503.
[8] 理解神經網路的啟用函式 【獲取碼】SIGAI2018.5.5.
[9] 深度卷積神經網路演化歷史及結構改進脈絡-40頁長文全面解讀【獲取碼】SIGAI0508.
[10] 理解梯度下降法【獲取碼】SIGAI0511.
[11] 迴圈神經網路綜述—語音識別與自然語言處理的利器【獲取碼】SIGAI0515
[12] 理解凸優化 【獲取碼】 SIGAI0518
[13] 【實驗】理解SVM的核函式和引數 【獲取碼】SIGAI0522
[14]【SIGAI綜述】行人檢測演算法 【獲取碼】SIGAI0525
[15] 機器學習在自動駕駛中的應用—以百度阿波羅平臺為例(上)【獲取碼】SIGAI0529
[16]理解牛頓法【獲取碼】SIGAI0531
[17] 【群話題精華】5月集錦—機器學習和深度學習中一些值得思考的問題【獲取碼】SIGAI 0601
[18] 大話Adaboost演算法 【獲取碼】SIGAI0602
[19] FlowNet到FlowNet2.0:基於卷積神經網路的光流預測演算法【獲取碼】SIGAI0604
[20] 理解主成分分析(PCA)【獲取碼】SIGAI0606
[21] 人體骨骼關鍵點檢測綜述 【獲取碼】SIGAI0608
[22]理解決策樹 【獲取碼】SIGAI0611
[23] 用一句話總結常用的機器學習演算法【獲取碼】SIGAI0611
[24] 目標檢測演算法之YOLO 【獲取碼】SIGAI0615
[25] 理解過擬合 【獲取碼】SIGAI0618
[26]理解計算:從√2到AlphaGo ——第1季 從√2談起 【獲取碼】SIGAI0620
[27] 場景文字檢測——CTPN演算法介紹 【獲取碼】SIGAI0622
[28] 卷積神經網路的壓縮和加速 【獲取碼】SIGAI0625
[29] k近鄰演算法 【獲取碼】SIGAI0627
[30]自然場景文字檢測識別技術綜述 【獲取碼】SIGAI0627
[31] 理解計算:從√2到AlphaGo ——第2季 神經計算的歷史背景 【獲取碼】SIGAI0704
[32] 機器學習演算法地圖【獲取碼】SIGAI0706
[33] 反向傳播演算法推導-全連線神經網路【獲取碼】SIGAI0709
[34] 生成式對抗網路模型綜述【獲取碼】SIGAI0709.
[35]怎樣成為一名優秀的演算法工程師【獲取碼】SIGAI0711.
[36] 理解計算:從根號2到AlphaGo——第三季 神經網路的數學模型【獲取碼】SIGAI0716
[37]【技術短文】人臉檢測演算法之S3FD 【獲取碼】SIGAI0716
[38] 基於深度負相關學習的人群計數方法【獲取碼】SIGAI0718
[39] 流形學習概述【獲取碼】SIGAI0723
[40] 關於感受野的總結 【獲取碼】SIGAI0723
[41] 隨機森林概述 【獲取碼】SIGAI0725
[42] 基於內容的影象檢索技術綜述——傳統經典方法【獲取碼】SIGAI0727
[43] 神經網路的啟用函式總結【獲取碼】SIGAI0730
[44] 機器學習和深度學習中值得弄清楚的一些問題【獲取碼】SIGAI0802
[45] 基於深度神經網路的自動問答系統概述【獲取碼】SIGAI0803
[46] 反向傳播演算法推導——卷積神經網路 【獲取碼】SIGAI0806
[47] 機器學習與深度學習核心知識點總結 寫在校園招聘即將開始時 【獲取 碼】SIGAI0808
[48] 理解Spatial Transformer Networks【獲取碼】SIGAI0810
[49]AI時代大點兵-國內外知名AI公司2018年最新盤點【獲取碼】SIGAI0813
[50] 理解計算:從√2到AlphaGo ——第2季 神經計算的歷史背景 【獲取碼】SIGAI0815
[51] 基於內容的影象檢索技術綜述--CNN方法 【獲取碼】SIGAI0817
[52]文字表示簡介 【獲取碼】SIGAI0820
[53]機器學習中的最優化演算法總結【獲取碼】SIGAI0822
[54]【AI就業面面觀】如何選擇適合自己的舞臺?【獲取碼】SIGAI0823
[55]濃縮就是精華-SIGAI機器學習藍寶書【獲取碼】SIGAI0824
[56]DenseNet詳解【獲取碼】SIGAI0827
[57]AI時代大點兵國內外知名AI公司2018年最新盤點【完整版】【獲取碼】SIGAI0829
[58]理解Adaboost演算法【獲取碼】SIGAI0831
[59]深入淺出聚類演算法 【獲取碼】SIGAI0903
[60]機器學習發展歷史回顧【獲取碼】SIGAI0905
[61] 網路表徵學習綜述【獲取碼】SIGAI0907
[62] 視覺多目標跟蹤演算法綜述(上) 【獲取碼】SIGAI0910
[63] 計算機視覺技術self-attention最新進展 【獲取碼】SIGAI0912
[64] 理解Logistic迴歸 【獲取碼】SIGAI0914
[65] 機器學習中的目標函式總結 【獲取碼】SIGAI0917
原創宣告:本文為 SIGAI 原創文章,僅供個人學習使用,未經允許,不能用於商業目的