
【Python】程式設計筆記3
一、dict 和 set
1、字典——dict
思想:空間換時間
dict 中的 key 必須是不可變物件
(1)定義、初始化
在其他語言中也稱為 map,使用鍵 - 值(key - value)儲存,根據key通過hash演算法計算value值,可進行快速查詢。
## key-value
d = {'Michael':95, 'Bob':75, 'Tracy':85}
print(d['Michael'])
## 其他初始化方式
d['Adam'] = 67
print(d['Adam'])
輸出結果:
95
67
key-value 儲存方式:必須根據 key算出 value 的存放位置。
(2)查詢中,如果 key 不存在, dict 就會報錯
==》檢測 key 是否在 dict 中:
- 方法一:in
- 方法二:get()方法
## 方法1:
print('Tom' in d)
## 方法2:如果 key 不存在,可以返回 None,或指定的值
print(d.get('Tom'))
print(d.get('Tom', -1))
輸出結果
False
None
-1
注意:
- 返回 None 的時候 Python 的互動式命令列不顯示結果。
- dict 內部存放的順序和 key 放入的順序是沒有關係的。
pop(key) ==》key 和所對應的 value 均被刪除。
(4)dict vs. list
和 list 比較, dict 有以下幾個特點:
- 查詢和插入的速度極快,不會隨著 key 的增加而增加;
- 需要佔用大量的記憶體,記憶體浪費多。
而 list 相反:
- 查詢和插入的時間隨著元素的增加而增加;
- 佔用空間小,浪費記憶體很少。
2、集合——set
(1)定義
set 是一組 key 的集合,不儲存 value。且 set 中的元素,沒有重複。
==》可看作數學意義上的無序和無重複元素的集合
s = 輸出結果
{1, 2, 3, 8, 9}
(2)新增元素——add(key)
s.add(4)
print(s)
輸出結果
{1, 2, 3, 4, 8, 9}
(3)刪除元素——remove(key)
s.remove(4)
print(s)
輸出結果
{1, 2, 3, 8, 9}
(4)其他運算
s1 = set([1, 2, 3])
s2 = set([2, 3, 4])
print(s1 & s2) ## 交集
print(s1 | s2) ## 並集
輸出結果
{2, 3}
{1, 2, 3, 4}
二、不可變物件
問題:
a = 'abc'
print(a.replace('a','A'))
print(a)
輸出結果
Abc
abc
雖然字串有個 replace()方法,也確實變出了’Abc’,但變數 a 最後仍是’abc’,應該怎麼理解呢?
分析
重點:a 是變數,而’abc’才是字串物件
==》a 指向的物件的內容是 ’abc‘
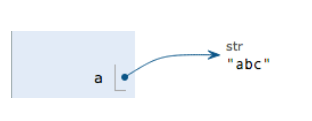
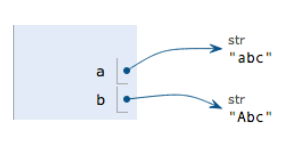
呼叫 a.replace(‘a’, ‘A’) 時,作用在字串物件 ‘abc’ 上,replace 方法建立了一個新字串’Abc’並返回,如果我們用變數 b 指向該新字串,就容易理解了,變數 a 仍指向原有的字串’abc’,但變數 b 卻指向新字串’Abc’了
==》對於不變物件來說,呼叫物件自身的任意方法,也不會改變該物件自身的內容。相反,這些方法會建立新的物件並返回,這樣,就保證了不可變物件本身永遠是不可變的。
三、函式
一種程式碼抽象的方式。
1、呼叫函式
呼叫函式的時候,如果傳入的引數數量不對或者引數型別錯誤,會報 TypeError 的錯誤。
2、資料型別轉換函式
print(int('123'))
print(int(12.34))
print(float('12.34'))
print(str(1.23))
print(str(100))
print(bool(1))
print(bool(''))
輸出結果
123
12
12.34
1.23
100
True
False
3、函式名
函式名,本質是指向一個函式物件的引用。
==》可以把函式名賦給一個變數,相當於給這個函式起了一個“別名”。
a = abs
print(a(-1))
輸出結果
1
4、定義函式
格式:def 函式名(引數):,然後,在縮排塊中編寫函式體,函式的返回值用 return 語句返回。
如果沒有 return 語句,函式執行完畢後也會返回結果,只是結果為 None。return None 可以簡寫為 return。
(1)空函式——pass語句
pass用於佔位符,可以先讓程式碼執行起來,之後再進行補充。
def nop():
pass
還可以放在其他語句中,eg:if 語句
5、引數檢查——TypeError錯誤
- 引數個數不對
- 引數型別不對(內建函式可以檢查出來,而自己寫的會不完善==》引數型別檢查)
def my_abs(x):
## 引數型別檢驗
if not isinstance(x, (int, float)):
raise TypeError('bad operand type')
if x > 0:
return x
else:
return -x
6、返回多個值
本質:函式可以同時返回多個值,但其實就是一個 tuple。
7、函式的引數
引數包括:必選引數、預設引數、可變引數和關鍵字引數。
==》處理複雜的引數,還可以簡化呼叫者的程式碼
(1)位置引數(必選引數)
按照位置順序依次賦給不同的引數。
(2)預設引數
注意:
- 必選引數在前,預設引數在後。
- 多引數時,將變化大的引數放在前面,變化小的引數放在後面,變化小的引數可以作為預設引數。
- 當不按順序提供部分預設引數時,需要把引數名寫上。
==》降低呼叫函式的難度。
def add_end(L = []):
L.append('END')
return L
print(add_end([1,2,3]))
print(add_end(['x','y','z']))
print(add_end())
print(add_end())
print(add_end())
輸出結果
[1, 2, 3, 'END']
['x', 'y', 'z', 'END']
['END']
['END', 'END']
['END', 'END', 'END']
原因
- 預設引數 L 是一個變數,它指向物件[],每次呼叫該函式,如果改變了 L 的內容,則下次呼叫時,預設引數的內容就變了,不再是函式定義時的[]了
==》預設引數必須指向不變物件
修改版本
def add_end(L = None):
if L is None:
L = []
L.append('END')
return L
print(add_end([1,2,3]))
print(add_end(['x','y','z']))
print(add_end())
print(add_end())
print(add_end())
輸出結果
[1, 2, 3, 'END']
['x', 'y', 'z', 'END']
['END']
['END']
['END']
(3)可變引數
傳入的引數個數是可變的。0 個 或 任意個
==》可變引數在函式呼叫時自動組裝為一個 tuple
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
## 直接呼叫
print(calc(1,2))
print(calc()) ## 可以 0 個引數
## 呼叫已有的list或tuple元素
## *nums 表示把 nums 這個 list 的所有元素作為可變引數傳進去。
nums = [1,2,3]
print(calc(*nums))
(4)關鍵字引數
傳入 0 個或任意個含引數名的引數
==》這些關鍵字引數在函式內部自動組裝為一個 dict。
==》用於擴充套件函式的功能,eg:選填引數
def person(name, age, **kw):
print('name:',name, 'age:',age, 'others:',kw)
## 直接呼叫
person('Michael', 30)
person('Bob', 35, city='Beijing')
person('Adam', 45, gender='M', job='Engineer')
## 呼叫已有的dict元素
extra = {'city': 'Beijing', 'job': 'Engineer'}
person('Jack', 24, **extra)
extra 表示把 extra 這個 dict 的所有 key-value 用關鍵字引數傳入到函式的kw 引數, kw 將獲得一個 dict,注意 kw 獲得的 dict 是 extra 的一份拷貝,對 kw 的改動不會影響到函式外的 extra。
(5)命名關鍵字引數
關鍵字引數檢查
呼叫時,仍可傳入不受限制的關鍵字引數
def person(name, age, **kw):
if 'city' in kw:
pass
if 'job' in kw:
pass
print('name:',name, 'age:',age, 'others:',kw)
person('Jack', 24, city='Beijing', addr='Chaoyang', zipcode=123456)
輸出結果
name: Jack age: 24 others: {'city': 'Beijing', 'addr': 'Chaoyang', 'zipcode': 123456}
命名關鍵字引數——只接受特定的關鍵字引數
命名關鍵字引數需要一個特殊分隔符 *,* 後面的引數被視為命名關鍵字引數。
def person(name, age, *,city, job):
print(name, age, city, job)
person('Jack', 24, city='Beijing', job='Enigneer')
## 命名關鍵字引數可以有預設值
def person(name, age, *,city = 'Beijing', job):
print(name, age, city, job)
注意:
- 命名關鍵字引數必須傳入引數名,這和位置引數不同。
- 命名關鍵字引數可以有預設值;
(6)引數組合
引數定義順序
必選引數、預設引數、可變引數/命名關鍵字引數和關鍵字引數。其中可變引數無法與命名關鍵字引數混合。
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
f1(1, 2)
f1(1, 2, c=3)
f1(1, 2, 3, 'a', 'b')
f1(1, 2, 3, 'a', 'b', x=99)
f2(1, 2, d=99, ext=None)
## 通過 tuple 和 dict 呼叫
args1 = (1,2,3,4)
kw1 = {'d':99,'x':'#'}
f1(*args1, **kw1)
args2 = (1,2,3)
kw2 = {'d':99,'x':'#'}
f2(*args2, **kw2)
輸出結果
a = 1 b = 2 c = 0 args = () kw = {}
a = 1 b = 2 c = 3 args = () kw = {}
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}
a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
a = 1 b = 2 c = 3 d = 99 kw = {'x': '#'}
對於任意函式,都可以通過類似 func(*args, **kw)的形式呼叫它,無論它的引數是如何定義的。
四、遞迴函式
如果一個函式在內部呼叫自身本身,這個函式就是遞迴函式。
優點:簡單、邏輯清晰
1、遞迴過程
注意:防止棧溢位
在計算機中,函式呼叫是通過棧( stack)這種資料結構實現的,每當進入一個函式呼叫,棧就會加一層棧幀,每當函式返回,棧就會減一層棧幀。由於棧的大小不是無限的,所以,遞迴呼叫的次數過多,會導致棧溢位。
==》解決方法:尾遞迴
==》尾遞迴:在函式返回的時候,呼叫自身本身,並且, return 語句不能包含表示式。這樣,編譯器或者直譯器就可以把尾遞迴做優化,使遞迴本身無論呼叫多少次,都只佔用一個棧幀,不會出現棧溢位的情況。
def fact(n):
return fact_iter(n, 1)
def fact_iter(num, product):
if num == 1:
return product
return fact_iter(num - 1, num * product)
遺憾的是,大多數程式語言沒有針對尾遞迴做優化, Python 直譯器也沒有做優化,所以,即使把上面的 fact(n)函式改成尾遞迴方式,也會導致棧溢位。