
【翻譯】Visual Place Recognition_ A Survey視覺場景識別綜述【三】
5 記錄地點:建圖模組
在場景識別或導航中,當前觀測資訊需要與系統參考地圖(機器人對世界感知的表示)不斷地進行比較。地圖根據可用資料和場景識別的型別,選擇不同的框架。表I列出了建圖方法的分類,分類方法取決於地圖抽象程度以及地點描述子是否包括度量資訊。列表中內容最詳實的地圖框架是拓撲度量(拓撲)圖。全域性度量圖僅在小的地理區域範圍內可行,但是可以將拓撲圖融合到全域性度量圖中來改善這一點[140]。所以,對於場景識別,任何全域性度量圖可以被認為是單節點拓撲圖。
A.純影象檢索
場景識別中最抽象的地圖框架是僅儲存環境中每個地點的外觀資訊,而沒有位置資訊。純影象檢索的匹配僅基於外觀相似性,應用了計算機視覺中一般的影象檢索技術[3] ,而不是專門針對場景識別的技術。雖然相對位置資訊缺失,但索引更高效。
場景識別的一個關鍵問題是系統可擴充套件性——當機器人訪問的地方越來越多時,儲存需求將增加,搜尋效率將會降低。因此,設計地圖時要保證資料規模較大時的效率。如果用詞袋模型(BOW)來量化描述子空間,反向索引則可以加速影象檢索; 針對影象中的詞來儲存影象ID號,而不是針對影象ID來儲存詞。反向索引不需要對資料庫中的所有影象進行線性搜尋,就可以快速排除不可能的影象。
Schindler 等人 [3]使用分層詞彙樹[95]來實現城市資料集場景識別(20公里的遍歷具有大約1億特徵)。文章表明,如果只使用來自每個影象中最獨特的特徵,則場景識別效能提高,其中資訊增益通過條件熵計算。Li和Kosecká[141]研究了在較少特徵集時,如何改進場景識別效能。
FAB-MAP 2.0 [87],[142]使用詞袋模型的反向索引,演示了1000公里路徑的視覺場景識別。Schindler等人 [3]使用投票方案來匹配位置,其中應用了FAB-MAP概率模型,該概率模型包括negative observations(沒有出現在影象中的詞)以及反向索引之前需要簡化的positive observations。
場景識別系統在處理地點和詞彙資訊時使用分層搜尋,效率更高。Mohan等人 [143]使用cooccurent特徵矩陣來預選匹配的環境。然後搜尋空間被限制在預選的環境子集中,增加了場景識別的效率。
B.拓撲地圖
純拓撲圖包含關於地點的相對位置關係資訊,但不包括這些地方如何相關的度量資訊[5],[6],[118],[119]。拓撲資訊可以增加地點匹配的正確率,減少誤匹配[14],[84]。類似FAB-MAP的概率系統,給定先驗的位置均值,可以作為純影象檢索執行,不過通過貝葉斯濾波或類似技術,將影象處理資訊加入時,效能得到改善。
影象檢索技術通過使用反向索引來提高效率,而拓撲圖可以使用位置資訊來加速匹配過程,即,場景識別系統僅需要對接近機器人當前位置的地點進行搜尋。基於取樣的方法,如粒子濾波器,可以用來對可能的位置取樣[12,13],[111],[144]。當機器人定位良好時,找出最大概率的位置,並且這個位置距離當前機器人位置較近,則對該粒子進行重新取樣,如果機器人丟失位置資訊,顆粒會散佈在整個環境中。計算時間與粒子的數量成比例,與環境大小無關[145]。
另外,由於環境中閉環具有稀疏性,Latif等人 [19]使用拓撲資訊將場景識別描述為稀疏凸L1-最小化問題,並用同倫法[146]進行閉環檢測。
將拓撲資訊加到場景識別中後,識別過程就可以使用低解析度資料,對儲存器的需求也會降低。使用稀疏凸L1的最小化公式,在少至48個畫素的影象中也可以[19] 識別地點。當影象模糊或在不同條件下(比如一天中不同的時間點)觀測時,視覺場景識別系統應用拓撲資訊,可以在少至32個畫素(4通道)的圖片中實現。
C. 拓撲-度量混合地圖
拓撲資訊的新增可以使影象檢索效能增強,而加入度量資訊(距離、方向)則可以改善拓撲地圖。例如,FAB-MAP [6]和SeqSLAM [118]都是拓撲系統,但是他們分別在CAT-SLAM [13]和SMART [148]演算法中加入度量資訊,系統的場景識別效能得到改善。
拓撲-度量地圖是基於外觀的,度量資訊是指位置節點之間的相對位姿[149]–[152]。但是,每個地點內的地標或物體資訊儲存在每個節點中[1],[2],[26],[140],[153] - [156]。拓撲位置節點內的度量資訊可以儲存為稀疏地標圖[2],[7],[76],或稠密佔用柵格地圖[134](如果從影象資料可以提取出深度資訊)。Moravec和Elfes [39]在1980年代中期,提出用截斷符號距離函式表示密集空間模型的概念,但這種技術在近幾年GPU技術出現後才變得可行。
6 場景識別:置信度生成模組
從根本上講,場景識別系統是用來判斷觀測到地方是否到過。因此,任何場景識別系統的目標是通過視覺輸入與地圖資料的匹配,產生置信分佈。該分佈表徵當前視覺輸入與機器人地圖中地點資訊匹配的相似度或置信度。一般情況下,如果兩個地方描述相似,則它們在相同物理位置的可能性就大,而相似到何種程度時才能做出判斷,這取決於具體環境。例如,由於感知偏差,不同的地方難以區分,會被誤判為相同的環境。相反,變化的條件可能導致相同的地方,在不同的時間差異較大。
A. 場景識別和SLAM
場景識別可以提供閉環檢測,它在Pose-GraphSLAM演算法中具有重要作用[157]。姿態圖,也是基於檢視的表示方法[158],[159],廣泛應用於現代SLAM系統中,因為對於固定大小的地圖,它們的計算效率比較高,儘管它們在長時間執行時增加了計算要求。對於連續建圖,閉環檢測是非常重要的,因為它可以校正里程計帶來的漂移[160],[161]。閉環一般是從線上區域性地圖更新步驟中檢測出來的,許多系統可以一邊執行類似SLAM的區域性度量校正,一邊進行拓撲式閉環校正[1],[2],[80],[161];系統可以使用鐳射掃描資料[80],[161]或視覺里程計[1],[2]進行區域性度量校正,同時有一個獨立的全域性匹配過程來進行閉環檢測。
如果地點描述是基於外觀的,並且地點內部不包含任何度量資訊,但是地圖中包含地點之間的度量距離,則系統仍然可以使用閉環在地點層級上進行度量校正[149] - [152]。但是,如果地點描述中包含與影象特徵的度量資訊,如FrameSLAM [2]的情況,則可以執行更精確的校正。對於純拓撲的地圖沒有度量校正,這是拓撲層級的定位, 也就是說,系統只簡單地識別最可能的位置。
如果地圖中包含描述地點和地點之間的度量資訊,那它可以用來解決全度量SLAM問題。目前可用的SLAM技術比較廣泛,見[162] - [164]。Thrun和Leonard [164]驗證了三個關鍵的SLAM問題:擴充套件卡爾曼濾波器(EKF)[37],[38],[165] - [167]、Rao-Blackwellized粒子濾波器[168]以及上面討論的姿態圖 [160],[161],[169] - [171]。基於視覺的系統可以利用這些方法:EKF用於MonoSLAM [7],Rao-Blackwellized粒子濾波器用於[12],[172]和[173],而姿態圖優化技術用於[2] 174]。
B. 拓撲場景識別
如果多個數據通道可用,我們可以使用投票方案[3],[5],[79],[96],[175]。Ulrich和Nourbakhsh [5]使用多個色標,每個色標投票給它認為最可能的位置。根據投票結果,該系統可分為三類:可信的,不確定的或混淆的。如果置信色標投票一致並且總置信度高於某一閾值,則系統對的定位可信; 如果沒有一個色標足夠可信或總的置信度值太低,那麼系統的定位是不確定的; 如果不同的置信色標投票也不一致,則系統是混淆的。
如果系統使用基於文字分析的詞袋模型,它可以利用詞頻-逆文件頻率(TF-IDF)得分[56],[114],[176 ]。影象中的每個視覺詞具有TF-IDF得分,有兩個部分組成:TF詞頻,指詞條在影象中出現的頻率;以及IDF逆文件頻率,測量詞條在所有影象中的頻率。TF-IDF得分是這兩個值的乘積。
地點匹配度是根據貝葉斯定理計算出來的。早期基於外觀定位的概率表示方法有如下幾種:高斯函式[177]、高斯混合結合期望做大化[178]或者加入Parzen平滑的高斯核心[179][104]。如果使用詞袋模型的話[83],[180]也可以利用TF-IDF來計算觀測似然度。Siagian和Itti [111],[181]在兩個觀測更新步驟中通過觀測似然進行蒙特卡羅定位,觀測似然包括區域性特徵似然和物體似然。Garcia-Fidalgo和Rodriguez [182]使用了觀測似然,該似然將兩個影象之間的特徵匹配的數量與影象中特徵的總數相關聯,然後進行歸一化。
觀測似然性也可以通過資料驅動方法計算。FAB-MAP[6],[87]就使用了資料驅動方法計算觀測似然,它是一種基於外觀的概率定位系統。FAB-MAP使用的詞袋模型是通過SIFT或SURF特徵進行影象描述的,並在訓練階段計算每個詞的獨特性。由於詞袋模型中可能包含許多單詞(FAB-MAP中有100000詞彙[87]),觀測詞的完全聯合概率分佈[見圖6(a)]可以通過樸素貝葉斯假設或Chow–Liu樹近似[183] [見圖6(b)]。
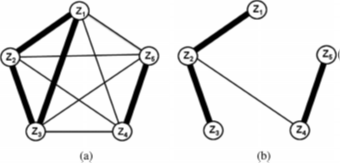
[圖 6 FAB-MAP學習單詞外觀和場景識別之間關係的概率模型。(a)完全聯合分佈考慮單詞之間的關係(詞之間的粗線表示具有最大互動資訊)。(b)Chow-Liu樹將整個聯合分佈近似為連線樹,其中每個單詞僅取僅與另一個單詞有關(來自184|)。
FAB-MAP處理感知混疊問題的時候,不僅考慮兩個位置是否相似(它們具有許多共同的視覺詞),而且還考慮共同的詞是否足夠特殊(使該地點相對於其他位置具有可區分性)。如果兩個位置看起來類似,但是共有的特徵出現頻繁,那麼將根據所有地點的資訊集合(包括看到過的和未看到過的)計算出一個歸一化常數,FAB-MAP將該常數作分母,從而降低匹配概率。
最初,我們通過從Chow-Liu樹中隨機取樣來對未訪問過的位置建模,當匹配概率大於某個閾值時,我們判斷機器人處於某個位置時,其中閾值是使用者定義的。然而,Paul和Newman [60],[62],[185]提出了一種迭代學習機制,生成一組代表世界外觀真實分佈的集合。Latent Dirichlet Allocation [186]將影象分成幾個主題,總結了目前為止機器人所感知到的世界。利用這些主題可以生成與世界物體數量對應的取樣集;例如,葉子在許多環境中出現,因此它不具有獨特性。系統不斷學習,獲取更多的環境資訊,不斷優化取樣集。此外,他們還提出線上-離線學習過程,在機器人的“停機時間”,可以通過網際網路下載和處理相關影象資料。
Olson [187]觀察到“正確的假設所得到的結果通常彼此一致,而不正確的假設得到的結果彼此不同”,並用這種方法來消除假陽性匹配,通過計算假設之間的成對一致性矩陣,從它的主特徵向量中來找到一致性最強的假設組合。該論文還得出,產生置信匹配所需的資訊量應該與機器人的位置不確定性相關。該系統要求區域性假設匹配的物理空間大於機器人的位置不確定性,以確保機器人不會在其不確定性區域誤定位[187]。
FAB-MAP要求匹配要求特徵具有高區分度,上面提到的方法與之相反,它需要多個匹配,但是這些匹配不需要特別的可區分性,因為匹配之間的幾何關係確保了假設的唯一性。
生物學啟發式位置識別方法模擬了大鼠海馬中已知的位置細胞結構[116],[188]。在RatSLAM [116]中,使用了一種稱為連續吸引子網路(CAN)的神經網路來模擬位置細胞(見圖7)。CAN結合自身運動和視覺感知資訊,使用區域性激勵和全域性抑制機制來定位。類似的,Giovannangeli等人[188]使用位置細胞模型,在沒有度量地圖的情況下,實現了室內和室外環境中的視覺導航。
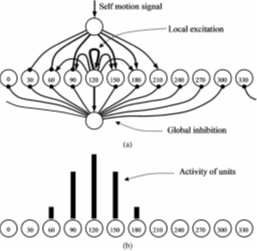
[圖7 CAN是一種神經網路,用於模擬位置細胞,頭向細胞和網格細胞的行為。(a)CAN用於模擬頭向細胞。 每個細胞激發自身及臨近細胞(見區域性激發箭頭)並抑制其他細胞。(b)運動輸入會帶來區域性激發和全域性抑制,這兩項組合產生以120°為中心的穩定活動資訊,它與里程計和視覺輸入結合,激勵附近的姿態細胞,抑制遠處的細胞,從而進行場景識別116|)。
C. 場景識別系統的評估
通常根據精確度和召回率,以及他們之間的precision-recall關係曲線來評估拓撲場景識別系統性能。系統根據置信度測量來選擇匹配,正確的匹配稱為真陽性,不正確的匹配是假陽性,並且系統誤丟棄的真匹配是假陰性匹配。精確度是指真陽性匹配在所選出的匹配中的比例,召回率是真陽性匹配與所有真匹配的總數的比例,即

完美的系統將達到100%的精確度和100%的召回率。精確度和召回率通常通過precision–recall曲線彼此相關,precision–recall曲線在置信度值範圍描述了精確度和召回率的關係。
近期,場景識別優先避免假陽性匹配[6],因為將錯誤引入地圖可能會導致災難性的失敗。因此,召回率100%是場景識別成功的關鍵指標。有一些方法使用拓撲資訊來校正假陽性匹配[ 189 ]–[ 191 ],關注點也從消除假陽性轉換到發現許多潛在的地點匹配,然後在拓撲後處理步驟中校正誤匹配。當在動態環境中執行場景識別時,嚴格匹配方法可能會失敗,增加潛在匹配的數目是特別重要的。
此外,隨著場景識別系統從“演示”(通常具有預先記錄的資料集)轉變為“排程”(在自主車輛上實時操作),效能評估方法可能會進一步改變,以將環境中地點匹配的空間分佈考慮在內。例如,McManus 等人 [192]使用“在行駛給定距離內沒有匹配成功的概率”來判斷場景識別系統是否成功。該方法可以得到地點匹配在環境中的分佈情況,也能保證“包含場景識別模組的導航系統”的完整性。