
手把手教你資料不足時如何做深度學習NLP

作為資料科學家,你最重要的技能之一應該是為你的問題選擇正確的建模技術和演算法。幾個月前,我試圖解決文字分類問題,即分類哪些新聞文章與我的客戶相關。
我只有幾千個標記的例子,所以我開始使用簡單的經典機器學習建模方法,如TF-IDF上的Logistic迴歸,但這個模型通常適用於長文件的文字分類。
在發現了我的模型錯誤之後,我發現僅僅是理解詞對於這個任務是不夠的,我需要一個模型,它將使用對文件的更深層次的語義理解。
深度學習模型在複雜任務上有非常好的表現,這些任務通常需要深入理解翻譯、問答、摘要、自然語言推理等文字。所以這似乎是一種很好的方法,但深度學習通常需要數十萬甚至數百萬的訓練標記的資料點,幾千的資料量顯然是不夠的。
通常,大資料集進行深度學習以避免過度擬合。深度神經網路具有許多引數,因此通常如果它們沒有足夠的資料,它們往往會記住訓練集並且在測試集上表現不佳。為了避免沒有大資料出現這種現象,我們需要使用特殊技術。
在這篇文章中,我將展示我在文章、部落格、論壇、Kaggle上發現的一些方法,以便在沒有大資料的情況下更好地完成目標。其中許多方法都基於計算機視覺中廣泛使用的最佳實踐。
正則化
正則化方法是在機器學習模型內部以不同方式使用的方法,以避免過度擬合,這個方法具有強大的理論背景並且可以以通用的方式解決大多數問題。
L1和L2正則化
這個方法可能是最古老的,它在許多機器學習模型中使用多年。在這個方法中,我們將權重大小新增到我們試圖最小化的模型的損失函式中。這樣,模型將嘗試使權重變小,並且對模型沒有幫助的權重將顯著減小到零,並且不會影響模型。這樣,我們可以使用更少數量的權重來模擬訓練集。有關更多說明,你可以閱讀
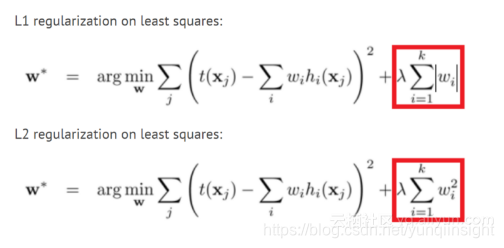
Dropout
Dropout是另一種較新的正則化方法,訓練期間神經網路中的每個節點(神經元)都將被丟棄(權重將被設定為零),這種方式下,網路不能依賴於特定的神經元或神經元的相互作用,必須學習網路不同部分的每個模式。這使得模型專注於推廣到新資料的重要模式。
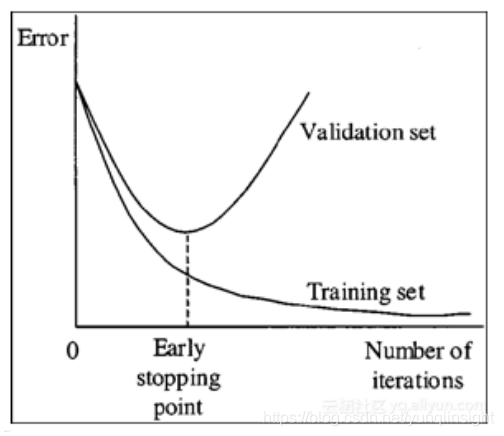
提早停止
提早停止是一種簡單的正則化方法,只需監控驗證集效能,如果你發現驗證效能不斷提高,請停止訓練。這種方法在沒有大資料的情況下非常重要,因為模型往往在5-10個時期之後甚至更早的時候開始過度擬合。
引數數量少
如果你沒有大型資料集,則應該非常小心設定每層中的引數和神經元數量。此外,像卷積層這樣的特殊圖層比完全連線的圖層具有更少的引數,因此在它們適合你的問題時使用它們非常有用。
資料增強
資料增強是一種通過以標籤不變的方式更改訓練資料來建立更多訓練資料的方法。在計算機視覺中,許多影象變換用於增強資料集,如翻轉、裁剪、縮放、旋轉等。

這些轉換對於影象資料很有用,但不適用於文字,例如翻轉像“狗愛我”這樣的句子不是一個有效的句子,使用它會使模型學習垃圾。以下是一些文字資料增強方法:
同義詞替換
在這種方法中,我們用他們的同義詞替換我們文字中的隨機單詞,例如,我們將句子“我非常喜歡這部電影”更改為“我非常愛這部電影”,它仍具有相同的含義,可能相同標籤。這種方法對我來說不起作用,因為同義詞具有非常相似的單詞向量,因此模型將兩個句子看作幾乎相同的句子而不是擴充。
方向翻譯
在這種方法中,我們採用我們的文字,將其翻譯成具有機器翻譯的中間語言,然後將其翻譯成其他語言。該方法在Kaggle毒性評論挑戰中成功使用。例如,如果我們將“我非常喜歡這部電影”翻譯成俄語,我們會得到“Мнеоченьнравитсяэтотфильм”,當我們翻譯成英文時,我們得到“I really like this movie”。反向翻譯方法為我們提供了同義詞替換,就像第一種方法一樣,但它也可以新增或刪除單詞並解釋句子,同時保留相同的含義。
檔案裁剪
新聞文章很長,在檢視資料時,有時不需要所有文章來分類文件。這讓我想到將文章裁剪為幾個子文件作為資料擴充,這樣我將獲得更多的資料。首先,我嘗試從文件中抽取幾個句子並建立10個新文件。這就建立了沒有句子之間邏輯關係的文件,但我得到了一個糟糕的分類器。我的第二次嘗試是將每篇文章分成5個連續句子。這種方法執行得非常好,給了我很好的效能提升。
生成對抗性網路
GAN是資料科學中最令人興奮的最新進展之一,它們通常用作影象建立的生成模型。這篇部落格文章解釋瞭如何使用GAN進行影象資料的資料增強,但它也可能用於文字。
遷移學習
遷移學習是指使用來自網路的權重,這些網路是針對你的問題通過另一個問題(通常是大資料集)進行訓練的。遷移學習有時被用作某些層的權重初始化,有時也被用作我們不再訓練的特徵提取器。在計算機視覺中,從預先訓練的Imagenet模型開始是解決問題的一種非常常見的做法,但是NLP沒有像Imagenet那樣可以用於遷移學習的非常大的資料集。
預先訓練的詞向量
NLP深度學習架構通常以嵌入層開始,該嵌入層將一個熱編碼字轉換為數字矢量表示。我們可以從頭開始訓練嵌入層,但我們也可以使用預訓練的單詞向量,如Word2Vec,FastText或Glove,這些詞向量使用無監督學習方法訓練大量資料或訓練我們域中的資料。預訓練的詞向量非常有效,因為它們為基於大量資料的單詞提供模型上下文,並減少模型的引數數量,從而顯著降低過度擬合的可能性。你可以在此處閱讀有關詞嵌入的更多資訊。
預先訓練的句子向量
我們可以將模型的輸入從單詞更改為句子,這樣我們可以使用較少的模型,其中引數數量較少,仍然具有足夠的表達能力。為了做到這一點,我們可以使用預先訓練好的句子編碼器,如Facebook的InferSent或谷歌的通用句子編碼器。我們還可以使用跳過思維向量或語言模型等方法訓練未標記資料的句子編碼器。你可以從我之前的博文中瞭解有關無監督句子向量的更多資訊。
預先訓練的語言模型
最近的論文如ULMFIT、Open-AI變換器和BERT通過在非常大的語料庫中預訓練語言模型,為許多NLP任務獲得了驚人的結果。語言模型是使用前面的單詞預測句子中的下一個單詞的任務。對我來說,這種預訓練並沒有真正幫助獲得更好的結果,但文章已經展示了一些方法來幫助我更好地微調,我還沒有嘗試過。這是一個關於預訓練語言模型的好部落格。
無人監督或自我監督學習的預訓練
如果我們有一個來自未標記資料的大型資料集,我們可以使用無監督的方法,如自動編碼器或掩碼語言模型,僅使用文字本身預訓我們的模型。對我來說更好的另一個選擇是使用自我監督。自我監督模型是在沒有人類註釋的情況下自動提取標籤的模型。一個很好的例子是Deepmoji專案,在Deepmoji中,作者訓練了一個模型,用於從推文中預測表情符號,在表情符號預測中獲得良好結果之後,他們使用他們的網路預先訓練了一個獲得最新結果的高音揚聲器情緒分析模型。表情符號預測和情緒分析顯然非常相關,因此它作為預訓練任務表現得非常好。新聞資料的自我監督任務可以預測標題、報紙、評論數量、轉推的數量等等。自我監督可以是一種非常好的預訓方法,但通常很難分辨出哪個代理標籤將與你的真實標籤相關聯。
特徵工程
我知道深度學習“殺死”了特徵工程,這樣做有點過時了。但是,當你沒有大資料集時,讓網路通過特徵工程學習複雜模式可以大大提高效能。例如,在我對新聞文章的分類中,作者、報紙、評論、標籤和更多功能的數量可以幫助預測我們的標籤。
多模式架構
我們可以使用多模式架構將文件級特徵組合到我們的模型中。在multimodal中,我們構建了兩個不同的網路,一個用於文字、一個用於特徵,合併它們的輸出層並新增更多層。這些模型很難訓練,因為這些特徵通常比文字具有更強的訊號,因此網路主要學習特徵效果。這是關於多模式網路的偉大的Keras教程。這種方法使我的效能表現提高了不到1%。
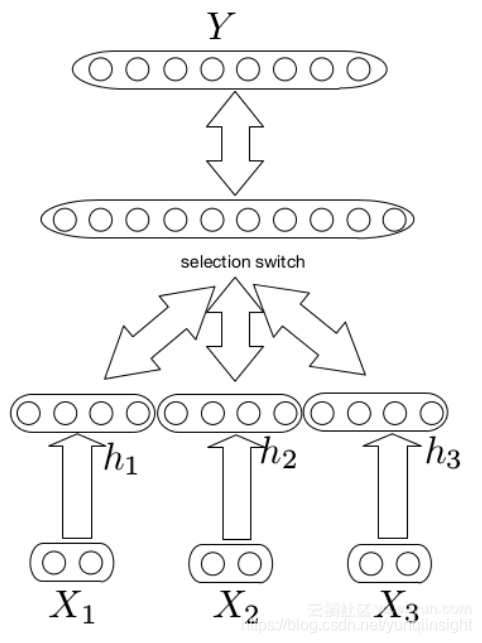
字級(word level)特徵
另一種型別的特徵工程是詞級特徵,如詞性標註、語義角色標記、實體提取等。我們可以將一個熱編碼表示或詞級特徵的嵌入與詞的嵌入相結合,並將其用作模型的輸入。我們也可以在這個方法中使用其他單詞特徵,例如在情感分析任務中我們可以採用情感字典併為嵌入新增另一個維度,其中1表示我們在字典中的單詞,0表示其他單詞,這樣模型可以很容易地學習它需要關注的一些詞。在我的任務中,我添加了某些重要實體的維度,這給了我一個很好的效能提升。
預處理作為特徵工程
最後一種特徵工程方法是以一種模型更容易學習的方式預處理輸入文字。一個例子是特殊的“阻止”,如果體育對我們的標籤不重要,我們可以改變足球,棒球和網球這個詞運動,這將有助於網路瞭解體育之間的差異並不重要,可以減少數量網路中的引數。另一個例子是使用自動摘要,正如我之前所說的,神經網路在長文字上表現不佳,因此我們可以在文字上執行自動彙總演算法,如“文字排名”,並僅向網路提供重要句子。
我的模型
我使用預先訓練過的詞向量來完成我公司為同一資料為該客戶所做的另一項任務。作為特徵工程,我在詞嵌入中添加了實體字級特徵。基本模型的這些變化使我的精確度提高了近10%,這使得我的模型從隨機性稍微好一點到具有重要業務影響的模型。
阿里雲雙十一1折拼團活動:滿6人,就是最低折扣了! 【滿6人】1核2G雲伺服器99.5元一年298.5元三年 2核4G雲伺服器545元一年 1227元三年 【滿6人】1核1G MySQL資料庫 119.5元一年 【滿6人】3000條國內簡訊包 60元每6月 參團地址:http://click.aliyun.com/m/1000020293/
原文連結 本文為雲棲社群原創內容,未經允許不得轉載。