
Detail-Preserving Pooling in Deep Networks閱讀
理解
首先,主要講下對文章的主要理解。簡而言之,這篇文章目的是保留影象細節,拒絕最大或者平均池化的簡單粗暴操作,可以自適應的學習的加權型池化。
文章借鑑的思想是DDIP。
綜述
池化的作用:降低引數量,擴大感受野,增強不變性。
目前常用的池化:最大,平均,帶步長的卷積。等等。最大池化是選擇領域內最大的,平均是對領域統一的貢獻。而strided conv則是簡單選擇一個節點作為池化後的節點。
文章內容
DDIP
俗話說,一張圖可以解釋一切。就是下面這張圖就能說明DDIP的思想。

O是輸出影象,上面一路是經過box filter-降取樣-高斯濾波之後的降取樣圖。經過逆雙邊濾波的作用,產生不同的加權結果,這樣就是產生了擴大細節的作用。
總之就是加權的過程。
DDP
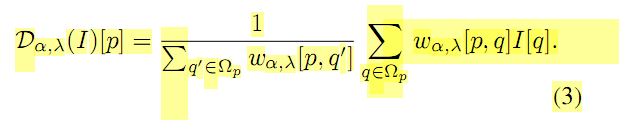
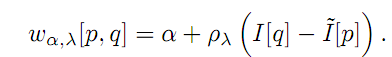
根據對reward function的不同,存在了對稱DDP和不對稱DDP兩種。公式見論文公式5,6。
那麼對於上面公式中的I(~)是線性降取樣的結果。公式為
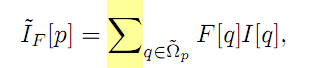
在論文中,根據對F的不同,可以產生Full-dPP和lite-DPP。
Full-dpp是指F為不標準的二維濾波,增加了相應大小的引數,可以學習。
對應的lite-dpp 則是為平均權重了。
討論
接下來的文章中,文章說明了引數的求導結果。並且說明了引數的增加相對於卷積等可以忽略,同時也證明了在特殊情況下ave-pooling 和 max-pooling可以是dpp的特例。
在實驗結果中,DPP展現了可以提升0.5-1個百分點的優勢。
相關推薦
Detail-Preserving Pooling in Deep Networks閱讀
理解 首先,主要講下對文章的主要理解。簡而言之,這篇文章目的是保留影象細節,拒絕最大或者平均池化的簡單粗暴操作,可以自適應的學習的加權型池化。 文章借鑑的思想是DDIP。 綜述 池化的作用:降低引數量,擴大感受野,增強不變性。 目前常用的池化:最大,平均,帶步長
論文閱讀筆記二十四:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
分享圖片 介紹 bin con strong map com 提高 https 論文源址:https://arxiv.org/abs/1406.4729 tensorflow相關代碼:https://github.com/peace195/sppnet 摘要
SPP-net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
Abstract SPP-net提出了空間金字塔池化層來解決CNN只是輸入固定尺寸的問題,因為單固定尺寸的輸入會影響識別效果,並且對於多尺度影象的情況下魯棒性不好。SPP-net很好的解決了以上問題,對於任意尺度影象都可以提取出固定維度的特徵,實驗證明SPP-net對分類
【筆記】SPP-Net : Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
基於空間金字塔池化的卷積神經網路物體檢測 論文:http://xueshu.baidu.com/s?wd=paperuri%3A%28c51f05992150d24c15f0dabf0913382e%29&filter=sc_long_sign&tn=SE
SPP(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
Introduction 在一般的CNN結構中,在卷積層後面通常連線著全連線。而全連線層的特徵數是固定的,所以在網路輸入的時候,會固定輸入的大小(fixed-size)。但在現實中,我們的輸入的影象尺寸總是不能滿足輸入時要求的大小。然而通常的手法就是裁剪(cr
深度學習論文翻譯解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
論文標題:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 標題翻譯:用於視覺識別的深度卷積神經網路中的空間金字塔池 論文作者:Kaiming He, Xiangyu Zhang, Shao
深度學習中的池化詳解 | Pooling in Deep learning
本文由多篇部落格總結整理而成,參考部落格見文末,侵刪。 目錄 最大池化 : 平均池化 重疊池化 參考文獻 參考部落格 首先,什麼是CNN ------------------------------------
[譯]深度神經網絡的多任務學習概覽(An Overview of Multi-task Learning in Deep Neural Networks)
noi 使用方式 stats 基於 共享 process machines 嬰兒 sdro 譯自:http://sebastianruder.com/multi-task/ 1. 前言 在機器學習中,我們通常關心優化某一特定指標,不管這個指標是一個標準值,還是企業KPI。為
Flower classification using deep convolutional neural networks 閱讀筆記
** Flower classification using deep convolutional neural networks ** 本部落格主要是對該篇論文做一個閱讀筆記 ,用FCN+CNN去做識別 期刊: IET Computer Vision 內容: (1)自動分割
論文閱讀之獻給新手的深度學習綜述——Recent Advances in Deep Learning: An Overview
這篇綜述論文列舉出了近年來深度學習的重要研究成果,從方法、架構,以及正則化、優化技術方面進行概述。本人認為,這篇綜述對於剛入門的深度學習新手是一份不錯的參考資料,在形成基本學術界圖景、指導文獻查詢等方面都能提供幫助。 論文地址:https://arxiv.org/pdf/1807.08169v1
深度神經網路的多工學習概覽(An Overview of Multi-task Learning in Deep Neural Networks)
譯自:http://sebastianruder.com/multi-task/ 1. 前言 在機器學習中,我們通常關心優化某一特定指標,不管這個指標是一個標準值,還是企業KPI。為了達到這個目標,我們訓練單一模型或多個模型集合來完成指定得任務。然後,我們通過精細調參,來改進模型直至效能不再
Image Super-Resolution Using Very Deep Residual Channel Attention Networks 閱讀理解
2018 CVPR Image Super-Resolution Using Very Deep Residual Channel Attention Networks Code https://github.com/yulunzhang/RCAN 親測效果不錯
Feed Forward and Backward Run in Deep Convolution Neural Network 論文閱讀筆記
徒手實現CNN:綜述論文詳解卷積網路的數學本質 Abstract 對卷積網路的數學本質和過程仍然不是太清楚,這也就是本論文的目的。 我們使用灰度圖作為輸入資訊影象, ReLU 和 Sigmoid 啟用函式構建卷積網路的非線性屬性, 交叉熵損失函式用於計算
An Overview of Multi-Task Learning in Deep Neural Networks
在人類學習中,不同學科之間的往往能起到相互促進的作用。那麼,對於機器學習是否也是這樣的,我們不僅僅讓它專注於學習一個任務,而是讓它學習多個相關的任務,是否可以讓機器在各個任務之間融會貫通,從而提高在主任務上面的結果呢? 1.multi-task的兩種形式 前面的層是權
Explainability in Deep Neural Networks
The wild success of Deep Neural Network (DNN) models in a variety of domains has created considerable excitement in the machine learning community. Despite
Nonlinear Computation in Deep Linear Networks
We've shown that deep linear networks — as implemented using floating-point arithmetic — are not actually linear and can perform nonlinear computati
【論文閱讀】Beyond Short Snippets: Deep Networks for Video Classification
【論文閱讀】Beyond Short Snippets: Deep Networks for Video Classification 之前3DCNN網路的論文算是記錄完了,雖然最近又出了幾篇,但是時間有限,很快要去實習去了,剩下的以後有時間再講吧。 本篇論文算是CNN+LSTM網路結構
How to Reduce Overfitting in Deep Neural Networks Using Weight Constraints in Keras
Weight constraints provide an approach to reduce the overfitting of a deep learning neural network model on the training data and improve the performance o
Grad-CAM:Visual Explanations from Deep Networks via Gradient-based L閱讀筆記-網路視覺化NO.3
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization 閱讀筆記 這是網路視覺化的第三篇,其餘兩篇分別是: ①《Visualizing and
Transfer learning & The art of using Pre-trained Models in Deep Learning
tran topic led super entire pooling file under mina 原文網址: https://www.analyticsvidhya.com/blog/2017/06/transfer-learning-the-art-of-fine