
hadoop-2.7.4-翻譯文件-聯邦HDFS
背景
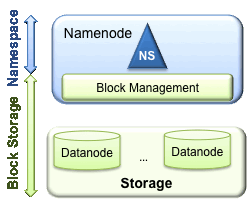
HDFS有兩個主要層:
- 名字空間
- 包含目錄,檔案和塊資訊。
- 它支援所有名字空間相關的檔案系統操作,如建立,刪除,修改和列出檔案和目錄。
-
塊儲存服務有兩部分:
- 塊管理(在Namenode中執行)
- 通過處理註冊和週期性心跳資訊來提供Datanode叢集成員管理服務。
- 處理塊報告並持久儲存塊的位置資訊。
- 支援塊相關操作,如增、刪、改、查。
- 管理塊副本的存放,對副本數不足的塊進行復制,以及對副本數超量的塊進行副本刪除。
- 塊儲存 - 由Datanodes提供服務,通過在本地檔案系統上進行塊儲存,並提供讀/寫訪問來實現。
之前的HDFS架構只執行一個NN來對整個叢集提供支援。在該配置下,單個NN管理整個名字空間。而聯邦HDFS通過向HDFS新增對多個Namenodes/namespaces的支援,解決了此限制。
- 塊管理(在Namenode中執行)
多個Namenodes/namespaces
為了水平副檔名稱服務,聯邦模式使用多個獨立的Namenodes/namespaces。多個Namenode之間組成了一個聯盟,並且各個Namenode之間是獨立的,不需要相互協調。Datanodes被所有Namenodes通用,來做塊的儲存工作。
使用者可以使用ViewFs來建立個性化的名稱空間檢視。ViewFs類似於某些Unix / Linux系統中的客戶端安裝表。
ViewFS使用參照 http://blog.csdn.net/anyuzun/article/details/78109320 。
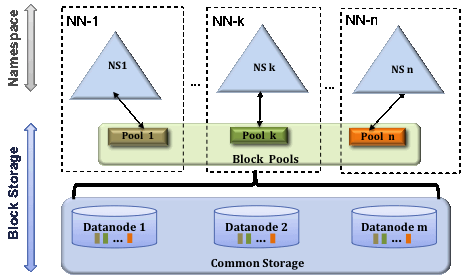
塊池
單個塊池是屬於單個名字空間的一個元件。Datanodes為叢集中所有的塊池提供塊儲存服務。每個塊池都是獨立管理的。這將允許名字空間為新塊生成塊ID,並且不需要與其他名字空間協調。叢集中單個
名字空間及其所屬塊池統稱為名字空間卷。這是一個獨立的管理單位。當Namenode或名字空間被刪除時,在Datanodes中其相應的塊池也被刪除。在叢集升級期間,每個名字空間卷都將作為單獨一個單元進行升級。
叢集ID
叢集ID用於識別該叢集中的所有節點。當一個Namenode被格式化時時,其叢集ID被主動提供或自動生成。該ID將用於格式化其他的Namenodes到叢集。
主要優點
- 名字空間的可擴充套件性 - 聯邦模式水平拓展了NameSpace。在叢集中通過增加NameNode來水平拓展名字空間,使得大型叢集或包含多量小檔案的叢集得以受益。
- 效能的提高 - 檔案系統的吞吐量不再受單個Namenode限制。向叢集新增更多的Namenode大大提高了檔案系統的讀/寫吞吐量。
- 隔離性 - 單個Namenode並不能在多使用者環境中提供隔離。例如,一個實驗階段的應用程式可能會使生產環境的應用程式達到超載。通過使用多個Namenode,可以使得不同類別的應用程式和使用者隔離到不同的名字空間中去。
聯邦配置
聯盟配置向後相容,並允許單個Namenode使用現有的配置繼續工作,而無需任何變化。新的配置模式使得叢集中的所有節點具有相同的配置,不需要根據叢集中的節點型別部署不同而做出改變。
聯邦模式添加了一個新的NameServiceID抽象。一個Namenode及其對應的secondary/backup/checkpointer節點都屬於同一個NameServiceId。為了支援多個NameNode配置寫入到單個配置檔案中,Namenode和其附屬節點r配置引數均新增NameServiceID作為字尾。
配置
步驟1:將dfs.nameservices引數新增到配置檔案中,並使用逗號分隔的NameServiceID列表進行配置。Datanodes將使用此配置來確定叢集中的Namenode。
步驟2:對於每個Namenode和其附屬節點的配置資訊,以相應的NameServiceID為字尾,新增到通用配置檔案中:
| 守護程序 | 配置引數 |
|---|---|
| Namenode | dfs.namenode.rpc-address dfs.namenode.servicerpc-address dfs.namenode.http-address dfs.namenode.https-address dfs.namenode.keytab.file dfs.namenode.name.dir dfs.namenode.edits.dir dfs.namenode.checkpoint.dir dfs.namenode.checkpoint.edits.dir |
| Secondary Namenode | dfs.namenode.secondary.http-address dfs.secondary.namenode.keytab.file |
| BackupNode | dfs.namenode.backup.address dfs.secondary.namenode.keytab.file |
這是一個包含雙Namenode的配置示例:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>nn-host1:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>nn-host1:http-port</value>
</property>
<property>
#官網中此配置少了一個 "." ,我也是無語了。以下是正確配置。
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>snn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>nn-host2:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>nn-host2:http-port</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>snn-host2:http-port</value>
</property>
.... Other common configuration ...
</configuration>
格式化Namenode
步驟1:使用以下命令格式化Namenode:
[hdfs]$ $HADOOP_PREFIX/bin/hdfs namenode -format [-clusterId <cluster_id>]
選擇一個不會與其他叢集發生衝突的cluster_id。如果未提供cluster_id,則會自動生成。
步驟2:使用以下命令格式化其他的Namenodes:
[hdfs]$ $HADOOP_PREFIX/bin/hdfs namenode -format -clusterId <cluster_id>
請注意,步驟2中的cluster_id必須與步驟1中的cluster_id相同。如果它們不同,則附加的Namenode不會成為聯邦叢集的一部分。
從舊版本升級為聯邦叢集
較舊的版本只支援單個Namenode。需要將叢集升級到較新版本以啟用聯邦模式,在升級期間,您可以使用如下的ClusterID:
[hdfs]$ $HADOOP_PREFIX/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
如果未提供cluster_id,則會自動生成。
將新的Namenode新增到現有的HDFS叢集
執行以下步驟:
-
將dfs.nameservices引數新增到配置檔案中。
-
使用NameServiceID字尾更新配置。配置鍵名稱已更改為0.20釋出版本。您必須使用新的配置引數名才能啟用聯邦模式。
-
將新的Namenode相關配置資訊新增到配置檔案中。
-
將配置檔案分發到叢集中的所有節點。
-
啟動新的Namenode及其附屬節點。
-
通過對叢集中的所有Datanode執行以下命令,來重新整理Datanode以使其獲取新新增的Namenode:
[hdfs]$ $HADOOP_PREFIX/bin/hdfs dfsadmin -refreshNameNodes <datanode_host_name>:<datanode_rpc_port>
管理叢集
啟動和停止叢集
要啟動叢集,請執行以下命令:
[hdfs]$ $HADOOP_PREFIX/sbin/start-dfs.sh
要停止叢集,請執行以下命令:
[hdfs]$ $HADOOP_PREFIX/sbin/stop-dfs.sh
這些命令可以在擁有HDFS配置檔案的任何節點執行。該命令使用配置檔案來確定叢集中的Namenode節點,然後在這些節點上啟動Namenode程序。DataNode則在[slaves]檔案中獲取節點資訊,並在指定的節點上啟動。該指令碼可參考用來構建自己的指令碼以啟動和停止叢集。
平衡器
使用多個NameNode時,平衡器已經發生更改。可以使用以下命令執行平衡器:
[hdfs]$ $HADOOP_PREFIX/sbin/hadoop-daemon.sh start balancer [-policy <policy>]
策略引數可以是以下任一項:
-
datanode - 這是預設策略。這樣可以在DataNode級別平衡儲存空間。這與以前版本的平衡策略相似。
-
blockpool -這將在塊池級別平衡儲存空間,同時也對Datanode級別的儲存空間進行平衡。
請注意,平衡器僅平衡資料,不會平衡名字空間。有關完整的命令用法,請參閱平衡器文件。
退役
退役類似於以前的版本。將需要退役的節點新增到所有Namenodes的[exclude]檔案中。每個Namenode將會退役其對應的Block Pool。當所有Namenode完成DataNode的退役後,Datanode宣告退役。
步驟1:要將排除檔案分發到所有的Namenodes,請使用以下命令:
[hdfs]$ $HADOOP_PREFIX/sbin/distribute-exclude.sh <exclude_file>
步驟2:重新整理所有的Namenode以接收新的排除檔案:
[hdfs]$ $HADOOP_PREFIX/sbin/refresh-namenodes.sh
上述命令使用HDFS配置資訊來確定叢集中的Namenode,並重新整理它們來接收新的排除檔案。
叢集Web控制檯
與Namenode狀態網頁類似,當使用聯邦叢集時,可以通過訪問 http://<any_nn_host:port>/dfsclusterhealth.jsp 頁面來使用Cluster Web Console監視聯邦叢集。叢集中的任何Namenode都可用於訪問此網頁。
叢集Web控制檯提供以下資訊:
-
一個叢集摘要,顯示了整個叢集的檔案數量,塊數,總配置儲存容量以及可用/已用儲存。
-
一個Namenodes的列表和一個摘要,包含了每個Namenode的檔案數,塊數,缺失塊數,以及存活和掛掉的資料節點數。它還提供訪問每個Namenode的Web UI的連結。
-
Datanodes的退役狀態。