pandas 行列轉換總結
阿新 • • 發佈:2018-12-18
pandas 行列轉換總結
資料
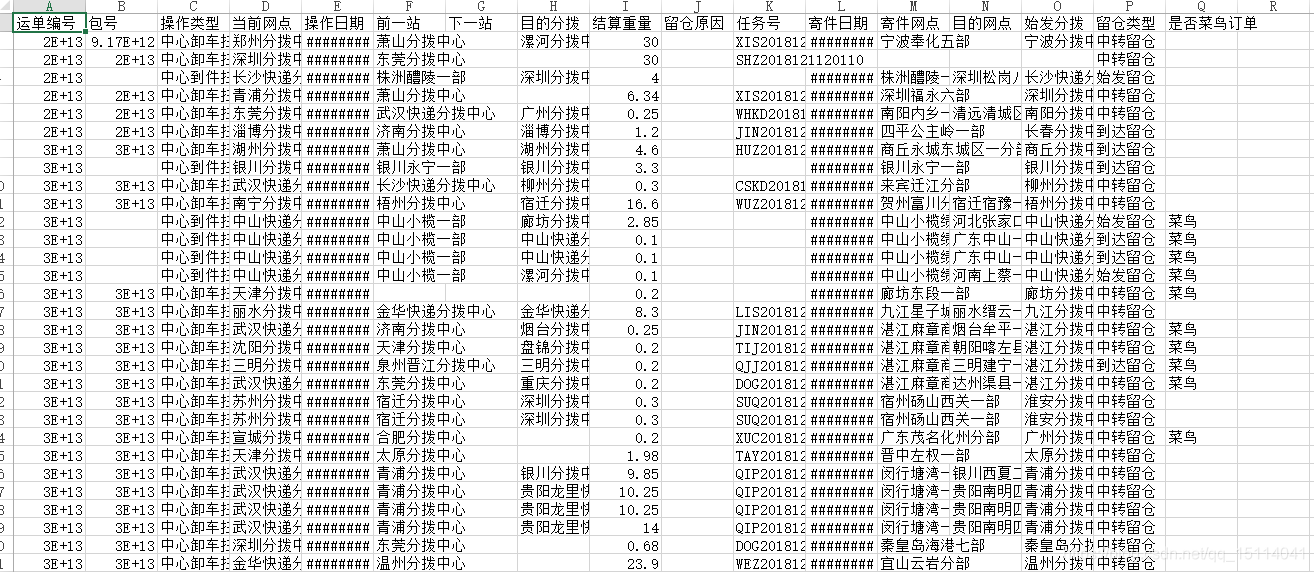
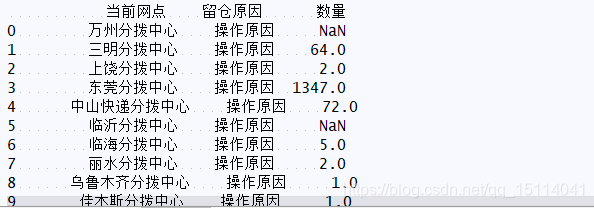
行轉列或者列轉行的資料一般都是groupby後的資料
b = kd.groupby(by=[“當前網點”, “留倉原因”], as_index=False)[“運單編號”].count()
c = kd.groupby(by=[“當前網點”, “留倉原因”])[“運單編號”].count()
(as_index=False)同groupby後再 reset_index()。
pandas預設groupby後將聚類的特徵設定為index。
b和c為兩個不同的dateframe,在stack和unstack進行行列轉置時轉換的實際是index和column,而pivot_table、pivot、melt 轉置的是特徵的資料。
groupby後的資料

stack、unstack
print(bd.set_index(["當前網點", "留倉原因"]).unstack(level=1))

print(bd.set_index(["當前網點","留倉原因"]).unstack(level=1).stack())

print(bd.set_index(["當前網點","留倉原因"]).unstack(level=1).stack().reset_index())
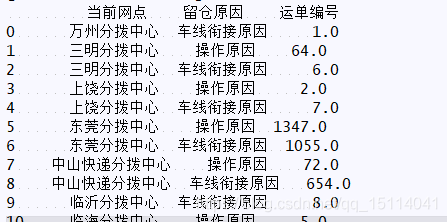
unstack index最外層轉到columns最外層,level 控制層
stack columns最外層轉到index最外層,level控制層
pivot,pivot_table,melt
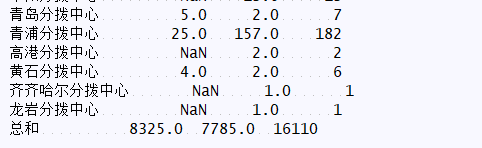
print(bd.pivot_table("運單編號",index="當前網點",columns="留倉原因",aggfunc="sum",margins=True,margins_name="總和"))
print(pd.pivot_table(bd,"運單編號", index="當前網點", columns="留倉原因", aggfunc="sum", margins=True, margins_name="總和"))
兩種寫法效果一致
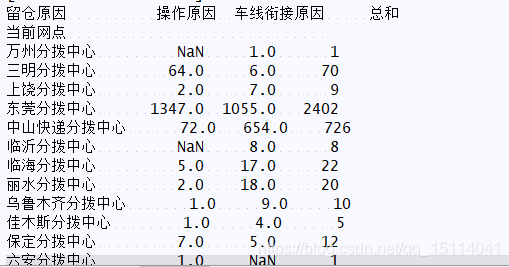
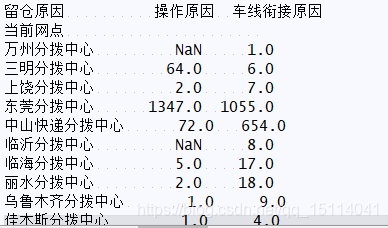
gg=bd.pivot("當前網點","留倉原因","運單編號") print(gg)
melt的作用類似於stack
g = pd.melt(g, id_vars=['當前網點'],
value_vars=['操作原因', '車線銜接原因'],
var_name='留倉原因', value_name='數量')