
Flume+HBase+Kafka整合與開發
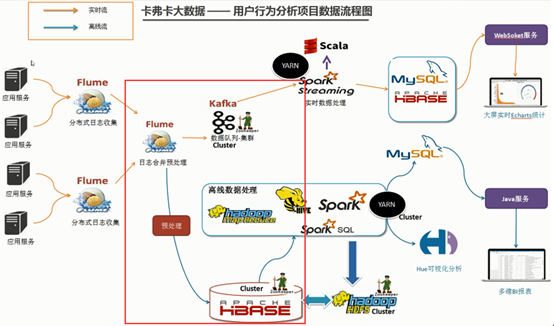
今天的內容是完成Flume+HBase+Kafka的整合開發。如下圖紅框中所示,節點1的Flume的source有兩個:節點2和節點3的sink輸出。節點1接收後進行預處理然後分別以AsyncHBaseSink(HBaseSink)和Kafka Sink的方式推送給HBase和Kafka進行離線資料處理和實時資料處理。
1.下載Flume原始碼並匯入Idea開發工具
1)將apache-flume-1.7.0-src.tar.gz原始碼下載到本地解壓
2)通過idea匯入flume原始碼
開啟idea開發工具,選擇File—>Open
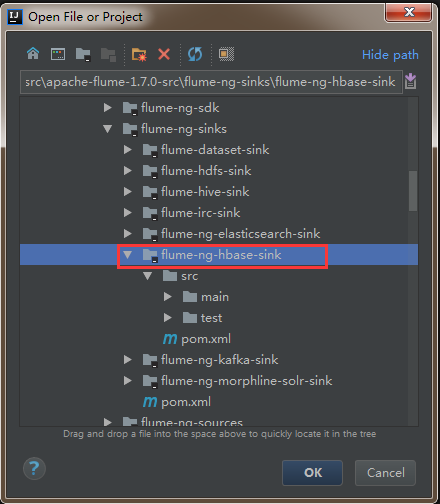
然後找到flume原始碼解壓檔案,選中flume-ng-hbase-sink,點選ok載入相應模組的原始碼。
2.官方flume與hbase整合的引數介紹

其中,加粗的屬性是必須配置的,其它則作為優化引數。payloadColumn屬性是告知HBase有多少個列要寫入列簇columnFamily下。
3.下載日誌資料並分析
到搜狗實驗室下載使用者查詢日誌(該過程在前面HBase環境部署中已經完成,有問題的可以回去檢視一下: HBase分散式叢集部署與設計)
1)介紹
搜尋引擎查詢日誌庫設計為包括約1個月(2008年6月)Sogou搜尋引擎部分網頁查詢需求及使用者點選情況的網頁查詢日誌資料集合。為進行中文搜尋引擎使用者行為分析的研究者提供基準研究語料
2)格式說明
資料格式為:訪問時間\t使用者ID\t[查詢詞]\t該URL在返回結果中的排名\t使用者點選的順序號\t使用者點選的URL
其中,使用者ID是根據使用者使用瀏覽器訪問搜尋引擎時的Cookie資訊自動賦值,即同一次使用瀏覽器輸入的不同查詢對應同一個使用者ID
該資料將作為本專案的源資料,存放於節點2和節點3。
4.flume agent-3聚合節點與HBase整合的配置
用notepad++連線節點1,對配置檔案進行重新命名。
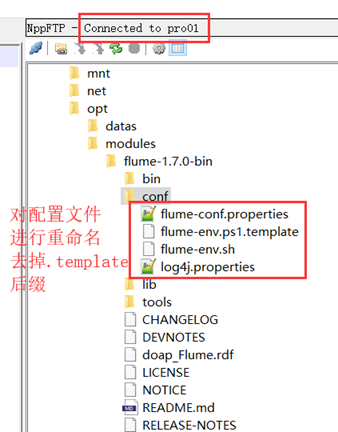
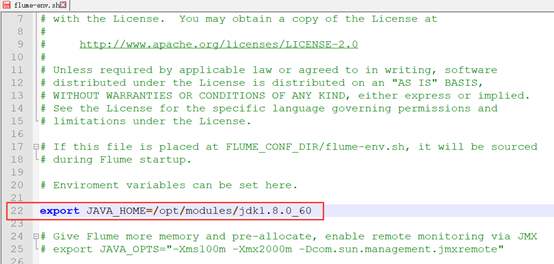
配置fulme-env.sh檔案
配置flume-conf.properties檔案

原模板格式凌亂,直接全部幹掉,輸入以下內容:
agent1.sources = r1
agent1.channels = kafkaC hbaseC
agent1.sinks = kafkaSink hbaseSink
agent1.sources.r1.type = avro
agent1.sources.r1.channels = hbaseC
agent1.sources.r1.bind = bigdata-pro01.kfk.com
agent1.sources.r1.port = 5555
agent1.sources.r1.threads = 5
agent1.channels.hbaseC.type = memory
agent1.channels.hbaseC.capacity = 100000
agent1.channels.hbaseC.transactionCapacity = 100000
agent1.channels.hbaseC.keep-alive = 20
agent1.sinks.hbaseSink.type = asynchbase
agent1.sinks.hbaseSink.table = weblogs
agent1.sinks.hbaseSink.columnFamily = info
agent1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.KfkAsyncHbaseEventSerializer
agent1.sinks.hbaseSink.channel = hbaseC
agent1.sinks.hbaseSink.serializer.payloadColumn = datatime,userid,searchname,retorder,cliorder,cliurl5.對日誌資料進行格式處理
1)將檔案中的tab更換成逗號
cat weblog.log|tr "\t" "," > weblog2.log2)將檔案中的空格更換成逗號
cat weblog2.log|tr " " "," > weblog3.log 
[[email protected] datas]$ rm -f weblog2.log
[[email protected] datas]$ rm -f weblog.log
[[email protected] datas]$ mv weblog3.log weblog.log
[[email protected] datas]$ ls
wc.input weblog.log3)然後分發到節點2和3
[[email protected] datas]$ scp weblog.log bigdata-pro02.kfk.com:/opt/datas/
weblog.log 100% 145MB 72.5MB/s 00:02
[[email protected] datas]$ scp weblog.log bigdata-pro03.kfk.com:/opt/datas/
weblog.log6.自定義SinkHBase程式設計與開發
1)模仿SimpleAsyncHbaseEventSerializer自定義KfkAsyncHbaseEventSerializer實現類,修改一下程式碼即可。

@Override
public List getActions() {
List actions = new ArrayList();
if (payloadColumn != null) {
byte[] rowKey;
try {
/*---------------------------程式碼修改開始---------------------------------*/
//解析列欄位
String[] columns = new String(this.payloadColumn).split(",");
//解析flume採集過來的每行的值
String[] values = new String(this.payload).split(",");
for(int i=0;i < columns.length;i++){
byte[] colColumn = columns[i].getBytes();
byte[] colValue = values[i].getBytes(Charsets.UTF_8);
//資料校驗:欄位和值是否對應
if(colColumn.length != colValue.length) break;
//時間
String datetime = values[0].toString();
//使用者id
String userid = values[1].toString();
//根據業務自定義Rowkey
rowKey = SimpleRowKeyGenerator.getKfkRowKey(userid,datetime);
//插入資料
PutRequest putRequest = new PutRequest(table, rowKey, cf,
colColumn, colValue);
actions.add(putRequest);
/*---------------------------程式碼修改結束---------------------------------*/
}
} catch (Exception e) {
throw new FlumeException("Could not get row key!", e);
}
}
return actions;
}2)在SimpleRowKeyGenerator類中,根據具體業務自定義Rowkey生成方法
/**
* 自定義Rowkey
* @param userid
* @param datetime
* @return
* @throws UnsupportedEncodingException
*/
public static byte[] getKfkRowKey(String userid,String datetime)throws UnsupportedEncodingException {
return (userid + datetime + String.valueOf(System.currentTimeMillis())).getBytes("UTF8");
}7.自定義編譯程式打jar包
1)在idea工具中,選擇File—>ProjectStructrue

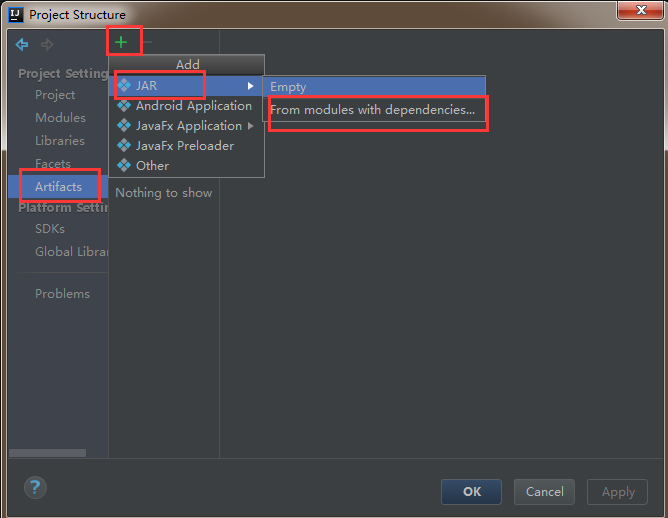
2)左側選中Artifacts,然後點選右側的+號,最後選擇JAR—>From modules with dependencies
3)然後直接點選ok
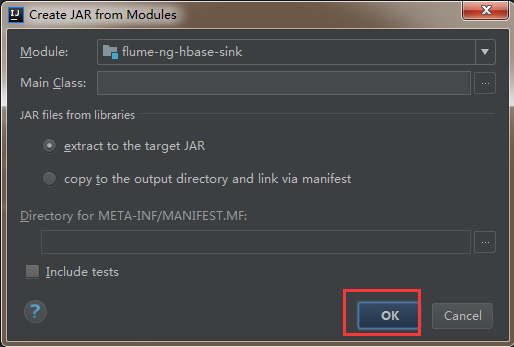
4)然後依次點選apply,ok

6)點選build進行編譯,會自動打成jar包

7)到專案的目錄下找到剛剛打的jar包

8)將打包名字替換為flume自帶的包名flume-ng-hbase-sink-1.7.0.jar ,然後上傳至flume/lib目錄下,覆蓋原有的jar包即可。

8.flume聚合節點與Kafka整合的配置
繼續在flume-conf.properties檔案中追加以下內容:
#*****************flume+Kafka***********************
agent1.channels.kafkaC.type = memory
agent1.channels.kafkaC.capacity = 100000
agent1.channels.kafkaC.transactionCapacity = 100000
agent1.channels.kafkaC.keep-alive = 20
agent1.sinks.kafkaSink.channel = kafkaC
agent1.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.kafkaSink.brokerList = bigdata-pro01.kfk.com:9092,bigdata-pro02.kfk.com:9092,bigdata-pro03.kfk.com:9092
agent1.sinks.kafkaSink.topic = test
agent1.sinks.kafkaSink.zookeeperConnect = bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181
agent1.sinks.kafkaSink.requiredAcks = 1
agent1.sinks.kafkaSink.batchSize = 1
agent1.sinks.kafkaSink.serializer.class = kafka.serializer.StringEncoder以上就是博主為大家介紹的這一板塊的主要內容,這都是博主自己的學習過程,希望能給大家帶來一定的指導作用,有用的還望大家點個支援,如果對你沒用也望包涵,有錯誤煩請指出。如有期待可關注博主以第一時間獲取更新哦,謝謝!同時也歡迎轉載,但必須在博文明顯位置標註原文地址,解釋權歸博主所有!