
中國大學MOOC課程資訊爬取與資料儲存
-
寫在前面
暑假沒事玩玩爬蟲,看到中國大學MOOC便想爬取它所有課程資訊。無奈,它不是靜態網頁,課程資料都是動態載入的。而爬取動態頁面目前來說有兩種方法:
- 分析頁面Ajax請求
- selenium模擬瀏覽器行為
可能方法不正確,我嘗試了前者發現行不通,便採用了後者。由於第一次寫部落格且自己程式設計能力有限,文中有不足或需要改進的地方請不吝賜教。
-
環境配置及模組安裝
編譯環境: Python3.6 、Spyder
依賴模組:pymysql,selenuim,bs4,re等
另外還要下載chromedriver並配置,參考這篇文章
-
簡要分析流程
-
主頁分析

主頁上便有課程類別,可以將其儲存為字典,通過不同課程類別便可到達相應課程類別介面。
subjects={'全部':'all_sub','計算機':'computer','經濟管理':'management','心理學':'psychology', '外語':'language','文學歷史':'literary_history','藝術設計':'art','工學':'engineering', '理學':'science','生命科學':'biomedicine','哲學':'philosophy','法學':'law', '教育教學':'teaching_method','大學先修課':'advanced_placement','職業教育課程':'TAFE'} for i,subject in enumerate(subjects): subject_Eng=subjects[subject] mooc_crawl(subject,subject_Eng)

每個頁面都有都可找到多個這樣的課程資訊。

點選下一頁可實現翻頁。
2.網頁解析
載入Chrome網頁
url = 'http://www.icourse163.org/category/all'
driver = webdriver.Chrome()
driver.set_page_load_timeout(50)
driver.get(url)
driver.maximize_window() # 將瀏覽器最大化顯示
driver.implicitly_wait(5) # 控制間隔時間,等待瀏覽器反應選擇課程類別,模擬點選;獲取網頁原始碼,Beautifulsou解析
ele=driver.find_element_by_link_text(subject)
ele.click()
htm_const = driver.page_source
soup = BS(htm_const,'xml')
返回soup物件,便可看到動態載入好的網頁原始碼。由於是txt文件,雖然不好檢視,但並不妨礙我們找到需要的資訊。從上面截圖可以看到了一些課程的課程名、開課老師、網頁連結、參與人數等。因此從這裡入手,我們便可得到該頁面的課程資訊!
c_names=soup.find_all(name='img',attrs={'height':'150px'})
c_schools=soup.find_all(name='a',attrs={'class':'t21 f-fc9'})
c_teachers=soup.find_all(name='a',attrs={'class':'f-fc9'})
c_introductions=soup.find_all(name='span',attrs={'class':'p5 brief f-ib f-f0 f-cb'})
c_stunums=soup.find_all(name='span',attrs={'class':'hot'})
c_start_times=soup.find_all(name='span',attrs={'class':'txt'})
c_links=soup.find_all(name='span',attrs={'class':' u-course-name f-thide'})
for i in range(len(c_names)):
kc_names.append(c_names[i]['alt'])
kc_schools.append(c_schools[i].string)
kc_teachers.append(c_teachers[i].string)
if c_introductions[i].string ==None:
c_introduction=''
else:
c_introduction=c_introductions[i].string
kc_introductions.append(c_introduction)
c_stunum=re.compile('[0-9]+').findall(c_stunums[i].string)[0]
kc_stunums.append(int(c_stunum))
kc_start_times.append(c_start_times[i].string)
kc_links.append('http:'+c_links[i].parent['href'])
c_id_num=re.compile('[0-9]{4,}').findall(c_links[i].parent['href'])[0]
kc_id_nums.append(int(c_id_num))
kc_info=[kc_names,kc_schools,kc_teachers,kc_introductions,kc_stunums,kc_start_times,kc_links,kc_id_nums]如下:

接下來,便是資料儲存啦。
-
資料儲存
由於mysql功能強大,操作簡便,python對其支援性較好,我就選用了mysql。不過其他資料庫皆可,資料儲存原理大同小異。在實現過程中,遇到了很多問題(SQL語句報錯,主鍵的設定讓每次插入資料都不重複,以變數為表單名的表單建立等等),好在花了一些功夫後,最終得以解決。下面是存入資料庫函式:
def save_mysql(subject,kc_info):
db = pymysql.connect(host='localhost',user='root',passwd='root',db='mooc_courses',charset='utf8')
cur = db.cursor()
try:
cur.execute("select * from %s"% subject)
results=cur.fetchall()
ori_len=len(results)
except:
#建立新表
sql = "create table %s"% subject+"(order_num int(4) not null,\
course varchar(50),\
school varchar(20),\
teacher varchar(20),\
start_time varchar(20),\
stu_num int(6),\
introduction varchar(255),\
link varchar(50),\
id int(11) not null,\
primary key(id)\
)"
cur.execute(sql)
db.commit()
ori_len=0
print('已在mooc_course資料庫中建立新表'+subject)
for i in range(len(kc_info[0])):
cur = db.cursor()
sql = "insert into %s"% subject+"(order_num,course,school,teacher,introduction,stu_num,start_time,link,id) VALUES ('%d','%s','%s','%s','%s','%d','%s','%s','%d')" %\
(ori_len+i,kc_info[0][i],kc_info[1][i],kc_info[2][i],kc_info[3][i],kc_info[4][i],kc_info[5][i],kc_info[6][i],kc_info[7][i])#執行資料庫插入操作
try:
# 使用 cursor() 方法建立一個遊標物件 cursor
cur.execute(sql)
except Exception as e:
# 發生錯誤時回滾
db.rollback()
print('第'+str(i+1)+'資料存入資料庫失敗!'+str(e))
else:
db.commit() # 事務提交
print('第'+str(i+1)+'資料已存入資料庫')
db.close()噹噹噹!修成正果,部分資料展示如下:
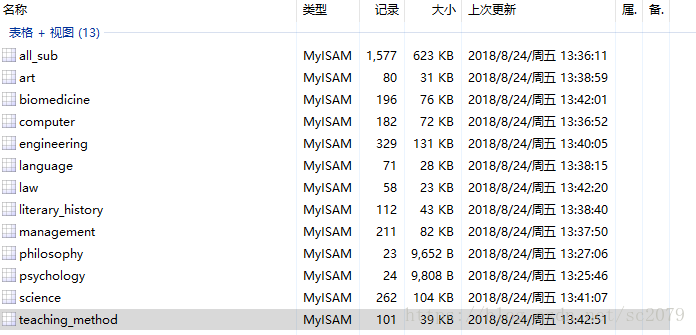
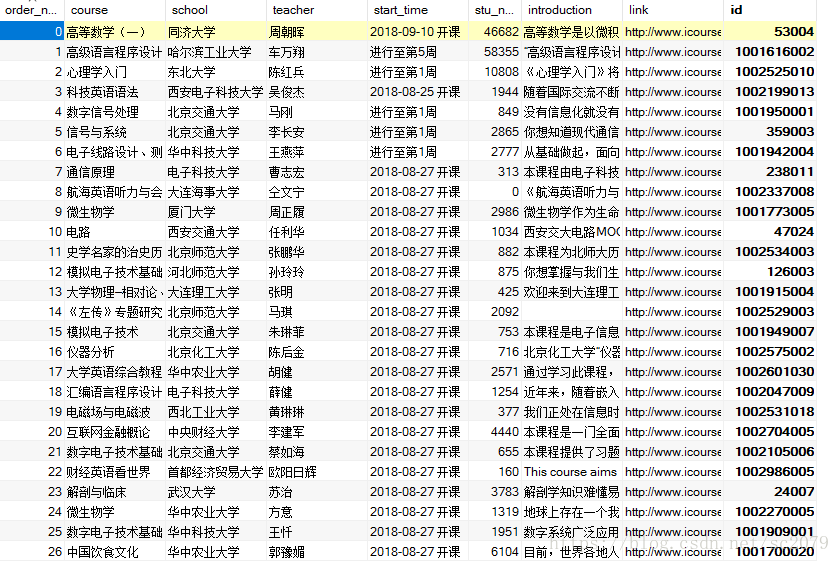
執行整個程式一共花了:726s,效率有待提高。不過對於我來說,還過得去。(實在不行,加多執行緒撒)。當然,資料爬取了,必須利用嘛,不然放在那裡養老不?有空,我做做資料分析,看看什麼課最受歡迎,哪些院校開課最多等等。。。。。。