基於Infiniband高效能叢集硬體配置方案
 摩爾定律的一再驗證殘酷的揭示了一個現實:速度是技術發展的終極目標。高效能運算領域也是一樣,如何使高效能運算平臺執行的更快、更高效一直是伺服器廠商研究的方向,曙光作為中國高效能運算的領頭羊,作為高階伺服器廠商,也在為此做著不懈的努力。Infiniband高速網路是近幾年產生的一種新興技術,因其具有高頻寬、低延遲的特色,得到了計算領域的青睞。本文介紹了Infiniband的硬體組成及其在不同應用中的選擇依據,最後通過四個案例進行分析,構建一套符合使用者需求的高效能運算網路。 1. 前言
摩爾定律的一再驗證殘酷的揭示了一個現實:速度是技術發展的終極目標。高效能運算領域也是一樣,如何使高效能運算平臺執行的更快、更高效一直是伺服器廠商研究的方向,曙光作為中國高效能運算的領頭羊,作為高階伺服器廠商,也在為此做著不懈的努力。Infiniband高速網路是近幾年產生的一種新興技術,因其具有高頻寬、低延遲的特色,得到了計算領域的青睞。本文介紹了Infiniband的硬體組成及其在不同應用中的選擇依據,最後通過四個案例進行分析,構建一套符合使用者需求的高效能運算網路。 1. 前言近年來,世界上的超級計算已經由價格昂貴、無擴充套件性的微控制器架構轉變為採用商業處理器而擁有無限擴充套件能力的集群系統,稱為高效能運算機叢集(HPC:High Performance Computing)。美國Top500.org組織每年分別兩次排列出當今世界上最強大的超級計算機,該排名按照超級計算機的實際計算能力(FLOPS:每秒浮點運算)按遞減順序排列。這個列表顯示出叢集架構正在逐漸取代微控制器架構的趨勢。由於HPC系統能夠快速準確計算出結果,有助於解決商業和科學研究中面臨的問題,所以,HPC系統越來越多的被政府部門、商業組織和科學院所採用。
然而,有一些部門和組織所面臨的是更具挑戰性的計算問題,他們需要更強大、高效能價格比的HPC系統。這就意味著人們必須要關注大叢集的建設,這裡的大叢集是指規模超過100個節點,達到幾百個、上千個甚至上萬個節點的集群系統;將集群系統擴充套件到這樣的規模而帶來的困難和複雜程度是難以想象的;使這樣規模的叢集能夠正常、穩定的工作也是一個痛苦的過程。在超級計算機發展的道路上不乏失敗了的大型HPC系統的“屍體”,也說明了這是一個值得研究的問題。
選擇一個正確的互連網路是能否達到甚至超過您對叢集效能預期的關鍵。如上所述,一個叢集中需要支援多種型別的資料流,所以,我們可以選擇在同一叢集中同時採用不同型別的網際網路絡,這些不同的網路將各自支援不同的網路協議,同時,這些不同的網路也擁有不同的網路效能和特性。例如,基於千兆乙太網的網路,可以通過TCP/IP通道來傳輸資訊,但缺點是需要佔用大量CPU資源來處理網路通訊,導致整體處理效率的下降;Myrinet 網路採用解除安裝引擎(offload engine)技術降低了CPU資源在處理通訊方面的消耗,並且擁有千兆乙太網兩倍的頻寬。在目前的Top500排名上千兆乙太網技術和Myrinet都很普遍;然而Infiniband,由於是一個標準化的、開放的高效能互聯技術平臺,從小規模到大規模的可擴充套件性叢集中也擁有很強的生命力。
2. Infiniband背景介紹 2.1. Infiniband發展歷史
Infiniband是一種新型的匯流排結構,它可以消除目前阻礙伺服器和儲存系統的瓶頸問題,是一種將伺服器、網路裝置和儲存裝置連線在一起的交換結構的I/O技術。 它是一種致力於伺服器端而不是PC端的高效能I/O技術。
Infiniband最初於2000年上市,但由於當時經濟的不景氣和IT預算緊縮,人們對它的興趣很快就消散了。發展至今,I/O技術在企業伺服器中無論是速率上還是吞吐量上都取得了穩步提高。但是,毫無疑問,現有的基於PCI架構的I/O技術仍然是系統處理器、系統主存以及I/O外設之間的主要瓶頸。這種I/O架構已經不能滿足網際網路、電子商務、儲存網路等大量的I/O需求。隨著對稱多處理器(SMP)、叢集計算、網格以及遠端備份的廣泛應用,這種基於PCI架構的I/O技術的缺陷和侷限性日益突出。目前人們對互連技術的興趣開始恢復,而且非常希望互連技術能夠幫助資料中心降低成本或實現高效能的計算。隨著各種高速I/O標準相繼登場,Infiniband逐漸嶄露頭角。
Infiniband技術通過一種交換式通訊組織(Switched Communications Fabric)提供了較區域性匯流排技術更高的效能,它通過硬體提供了可靠的傳輸層級的點到點連線,並在線路上支援訊息傳遞和記憶體映像技術。不同於PCI,Infiniband允許多個I/O外設無延遲、無擁塞地同時向處理器發出資料請求 。 目前,叢集計算(Cluster)、儲存區域網(SAN)、網格、內部處理器通訊(IPC)等高階領域對高頻寬、高擴充套件性、高QoS以及高RAS(Reliability、Availability and Serviceability)等有迫切需求,Infiniband技術為實現這些高階需求提供了可靠的保障。
2.2. Infiniband發展趨勢
基於共享匯流排(Shared-Bus)的架構的諸多侷限性決定了這項I/O技術已經不能適合日益龐大的計算機系統的I/O需求。這些侷限性主要包括速率極限、可擴充套件性、單點故障等幾個主要方面。而基於交換架構的Infiniband技術在避開PCI架構上述問題的同時,提供了其他方面的更高效能。基於Fabric與基於共享匯流排I/O技術之間的簡要對比如下表所示。
1.Shared-Bus架構的侷限性
PCI-X 133的頻寬只有2GB/s,雖然目前公佈的PCI-E的頻寬峰值到4GBps,但這沒有從根本上緩解伺服器端的I/O頻寬瓶頸。同樣,PCI架構(主要是PCI-X)的可擴充套件性也非常有限,它主要通過兩種方式來實現:要麼增加同層PCI匯流排(PCI本身就是一種層次結構I/O技術),要麼增加PCI-to-PCI橋。前者主要通過在主機板上整合額外的Host-to-PCI匯流排晶片以及增加PCI聯結器來實現,而後者主要通過在主機板上增加PCI-to-PCI橋接晶片來實現。無論採用什麼方式擴充套件PCI架構的I/O匯流排,其代價都是比較昂貴的。 在基於共享匯流排的I/O結構中,所有通訊共享單一匯流排頻寬,由此就造成外設越多,可用頻寬就越少,從而帶來更嚴重的系統I/O瓶頸。不僅如此,在基於共享並行I/O總線上,大量的引腳數目也帶來了一定的電氣特性和機械特性等問題,使得PCB空間、訊號頻率以及訊號可傳輸距離都受到很大程度的制約。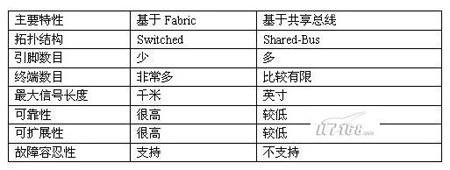
2.Switched Fabric體系結構的高可擴性
Infiniband所採用的交換結構(Switched Fabric)是一種面向系統故障容忍性和可擴充套件性的基於交換的點到點互聯結構。這種結構如下圖所示。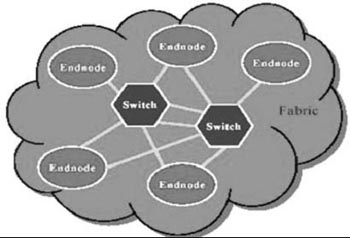
在上圖中,通過向Infiniband系統新增交換機可以很容易地實現I/O系統的擴充套件,進而允許更多的終端裝置接入到I/O系統。與基於共享匯流排的I/O系統相反,這種Switched Fabric系統的總體頻寬會隨著所接入交換裝置數目的增加而不斷提高。另外,正如上圖所指出的那樣,通過在Infiniband子結構之間新增路由裝置,可以更大範圍地擴充整個Infiniband系統。
Infiniband技術是一種開放標準的、目前全球頻寬最高的高速網路互聯技術,Infiniband產品是目前主流的高效能運算機互連裝置之一。目前基於Infiniband技術的網路卡的單埠頻寬最大可達到20Gbps,基於Infiniband的交換機的單埠頻寬最大可達60Gbps,單交換機晶片可以支援達480Gbit每秒的頻寬。到2006年,Infiniband技術可以達到單埠120Gbps,其單埠的頻寬甚至遠高於目前的主流交換機的總頻寬,可以為目前和未來對於網路頻寬要求非常苛刻的應用提供了可靠的解決方案。
Infiniband技術是採用RDMA傳輸機制實現了低延遲,高頻寬的新型網路標準,並得到了行業中所有領軍企業的支援;部分伺服器廠家已經或計劃將Infiniband晶片移植到主機板上。
Infiniband 架構的這種快速增長主要得益於越來越多的企業級資料中心的建立部署和持續發展的高效能運算的應用。
2004年1月,IBM開始將Infiniband技術應用於其解決方案; 2004年1月,SUN 開始推出Infiniband解決方案; 2004年2月,HP的Infiniband 產品在市場上出現; 2004年2月,Dell 開始推出Infiniband解決方案; 2004年5月,SKY Computer 的嵌入式Infiniband方案被用於軍事和工業應用; 2004年6月,NEC開始應用Infiniband到NEC刀片式伺服器; 2004年6月,SBS 公司率先宣佈推出基於VXWorks的 InfninBand 驅動; 2004年, HP和 Oracle多次重新整理TPCH效能測試紀錄; 2004年11月,在美國國家航空和宇宙航行局(NCSA),SGI完成了基於Infiniband互聯技術的超級計算機,其運算速度位居世界第二。 2005年4月,Cisco 公司宣佈收購 Infiniband 方案提供商-Topspin, 成為 Infiniband 產品的最大使用者。
除此之外,Apple、Hitachi、Fujitsu等廠商也都已推出了基於Infiniband的解決方案;Engenio、NetApp、DataDirect、Engenio、Isilon、Terrascale和CFS等儲存廠商也已推出或即將推出基於Infiniband技術的儲存解決方案;Arima,、Iwill,、SuperMicro和Tyan等伺服器主機板廠商也陸續推出了基於Infiniband晶片的LOM(Landed on Mainboard)方案。
而基於Infiniband技術的晶片、網絡卡和交換機主要供應商Mellanox公司已取得里程碑式的銷售成績----50萬個 Infiniband 埠,這些埠體現在多種產品形式上,包括:叢集伺服器、高頻寬交換機、嵌入式平臺和叢集儲存系統。
“因為 Infiniband 有著極佳的擴充套件性與效能,由許多公司包括Mellanox在內所生產的10Gb/s適配卡,會幫助使用者壓低叢集中每個節點的成本,”英特爾 數字企業集團行銷主管 Jim Pappas 說道:“ Infiniband 產品種類的增多對應用於商業和科學計算領域的 10Gb/s 頻寬計算機叢集的發展有著積極的影響。”另外,InfiniHost III Lx HCA 卡把這種高效能通訊技術同時打入了高速儲存和嵌入式應用這兩個市場。
由此可見,Infiniband的整體解決方案已經成形,這個整體解決方案的出現,必將帶來高效能運算平臺和資料中心的一次變革,讓長期以來一直高高在上的高效能解決方案變得大眾化。
2.3. Infiniband技術特色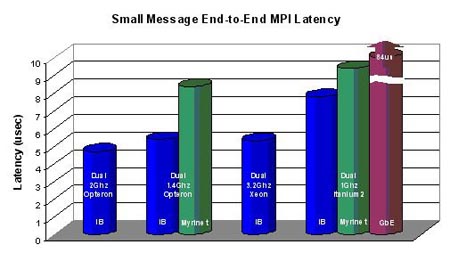
圖示: 傳輸小資料包的效能測試
許多應用對資訊傳輸的延遲是很敏感的,傳輸的延遲隨著所傳輸資訊的大小而有所不同,所以,同時瞭解互連網路在傳輸小資訊和大資訊時的延遲非常重要。通過對叢集中兩節點間進行的延遲基準測量,可以看到Infiniband裝置在各種處理器平臺上延遲都是最低。
需要指出的是,延遲的基準測試中一般都是採用了最小的資料包及0位元組的資料包進行傳輸,得到結果,並沒有反映出實際工作時的情況;而實際應用中,資料包一般比較大,這時就對頻寬提出了要求。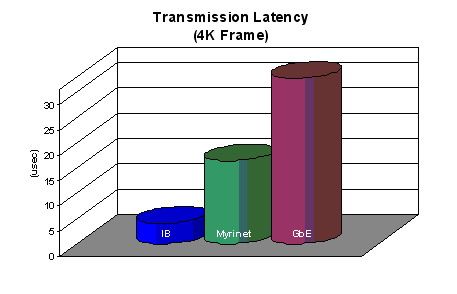 圖示4K資料包時各種網路的延遲
圖示4K資料包時各種網路的延遲
在傳輸4K大小的資料包時,Infiniband 10Gbps的頻寬優勢很明顯,傳輸速度遠遠優於Myrinet和千兆乙太網。
需要注意的是,所有公開的網路延遲都是在最佳情況下測得的。最佳情況是指參與測試的兩臺伺服器只通過了一個交換晶片連線;但是,隨著叢集規模的擴大,底層的交換結構也將擴大,傳輸資料包所需經過的交換裝置也在不斷的增加,每一個交換裝置都會在資料包傳輸到目的地的過程中增加額外的延遲;單獨看待一臺交換機硬體上的延遲是很小的,相比其他部分產生的延遲,可以忽略;但是站在整套叢集架構來看,考慮這個延遲的重要性就顯現出來。考慮了裝置的延遲,還需要考慮物理層(裝置)以上的各種網路協議在傳輸資料時產生的延遲。Infiniband的設計採用了傳輸協議解除安裝和繞過OS技術,也稱為RDMA(遠端直接儲存訪問),從而減少了通訊對CPU的開銷,將CPU的計算資源留給了應用。對於應用,越多的CPU資源意味著計算工作能夠更快的完成或更多複雜的模擬可以在同一時間內完成。所有的這些降低延遲的特性集合起來證明
了Infiniband的能力。
由於協議、通訊和CPU的負載將會隨著節點的增加而佔用越來越多的CPU計算資源,所以,保證可用的CPU資源總數能夠隨著叢集規模而線性增加是非常重要的。這一效能可以通過HPL(High-Performance Linpack)測試結果來體現。HPL的測試結果用百分數表示:實際應用所佔的計算資源與整體計算資源相除得出百分比。需要指明的是,即使是一臺雙CPU的伺服器,沒有任何互聯裝置,在做HPL測試時,也不可能達到100%的效率。這就要求互連裝置能夠隨著叢集增大而儘量保持較高的HPL效率,下圖表顯示了使用同種處理器而處理器數量從4到288個時的HPL效率,Infiniband再次取得了最好的效能。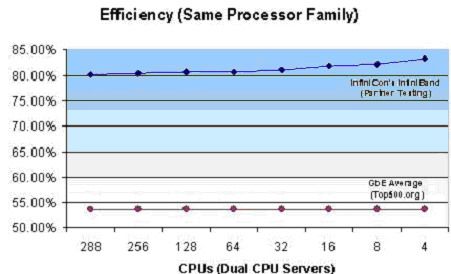 Top500 上相同CPU各種網路的HPL效率
Top500 上相同CPU各種網路的HPL效率
與同類其它產品(如10Gbit乙太網卡)相比較,Infiniband產品也具有明顯的優勢,其價格是目前10Gbit乙太網卡的十分之一,但是Infiniband HCA卡的功耗卻是10Gbit乙太網卡的七分之一,同時具有頻寬更大,延時更低,面積更小,對於CPU的佔用率更低,基於Infiniband平臺的軟體更加成熟等優勢。
隨著雙核處理器的出現、PCI-Express匯流排的發展、超級計算機的規模越來越大,對於高頻寬、低延時的需求變得越來越苛刻;資料庫機群的發展,華爾街/金融分析的精確度的增加,製造業、石油、氣象、生物等模擬技術的發展; 等等。高效能、低價格的網路互連方案變得日益重要,所有的一切都在推動Infiniband在快速的成為市場的主流,在科學計算、高速儲存和嵌入式應用等市場變得越來越普及。
2.3.1. Infiniband常用術語
HCA – Host Channel Adapter (主通道介面卡)
TCA – Target Channel Adapter (目標通道介面卡) QP – Queue Pair 每一個HCA可以同時支援幾千個QP(s)。QP(s)由需要通訊的節點產生。 SM – Subnet Manager 子網管理器(配置IB結構的軟體) ULP – Upper Layer Protocol (軟體包,採用Infiniband提供所定義的功能和服務) CM – Communication Manager (ULP所使用的軟體,用來調節節點機間所產生的QP) LID – 16bit Local Identifier 由子網管理器分配的標識
2.3.2. Infiniband技術優勢
Infiniband是一種交換結構I/O技術,其設計思路是通過一套中心機構(中心Infiniband交換機)在遠端存貯器、網路以及伺服器等裝置之間建立一個單一的連線鏈路,並由中心Infiniband交換機來指揮流量,它的結構設計得非常緊密,大大提高了系統的效能、可靠性和有效性,能緩解各硬體裝置之間的資料流量擁塞。而這是許多共享匯流排式技術沒有解決好的問題,例如這是基於PCI的機器最頭疼的問題,甚至最新的PCI-E也存在這個問題,因為在共享匯流排環境中,裝置之間的連線都必須通過指定的埠建立單獨的鏈路。
Infiniband的四大優點:基於標準的協議,每秒10 GB效能,遠端直接記憶體存取(Remote Direct Memory Access,簡稱RDMA)和傳輸解除安裝(transport offload)。
標準:成立於1999年的Infiniband貿易協會 由225家公司組成,它們共同設計了該開放標準。主要掌控該協會的成員包括:Agilent, Dell, HP, IBM, InfiniSwitch, Intel, Mellanox, Network Appliance和Sun Microsystems公司。其他的100多家成員則協助開發和推廣宣傳該標準。
速度:Infiniband每秒10gigabytes的效能明顯超過現有的Fibre Channel的每秒4 gigabits,也超過乙太網的每秒1 gigabit的效能。
記憶體:支援Infiniband的伺服器使用主機通道介面卡(Host Channel Adapter,簡稱HCA),把協議轉換到伺服器內部的PCI-X或者PCI-Xpress匯流排。HCA具有RDMA功能,有時也稱之為核心旁路(Kernel Bypass)。RDMA對於叢集來說很適合,因為它可以通過一個虛擬的定址方案,讓伺服器知道和使用其他伺服器的部分記憶體,無需涉及作業系統的核心。
傳輸解除安裝(Transport Offload): RDMA 能夠幫助傳輸解除安裝,後者把資料包路由從OS轉到晶片級,節省了處理器的處理負擔。要是在OS中處理10 Gbps的傳輸速度的資料,就需要 80 GHz處理器。
中央處理器CPU與其儲存子系統的設計是集群系統效能的指示器;但是,隨著叢集規模的擴充套件,保證CPU的資源不被佔用的關鍵是互連網路。互連網路的任務就是將叢集中海量的應用資料以儘可能快的速度從節點“A”傳到節點“B”,那麼從不同部分產生的延遲就是需要考慮的關鍵。所以,為了達到最佳的應用效率,就要
對可能產生延遲的部分做到延遲最小化。幸運的是,雖然產生延遲的部分有很多,但是,大多數延遲的瓶頸可以在互連網路這一級得到解決。 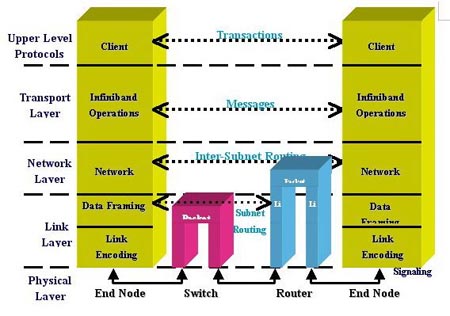 圖示:Infiniband在資料傳輸中的位置
圖示:Infiniband在資料傳輸中的位置
採用Infiniband的系統具有很強的可擴充套件性:按需購買,按需升級,按需擴充套件
a) 效能升級 :硬體和軟體可以進行上下相容,新的驅動可以在原有裝置上進行安裝,提高效能。 b)頻寬升級:3.3Gbps和5Gbps和10Gbps的三種解決方案之間可以進行靈活的升級;客戶所需要的只是增加交換機的背板模組。 c)規模升級:交換機之間可以進行堆疊來實現叢集擴充套件。IO9120(144埠),IO9240(288埠)的交換機,都是以12埠為單元進行擴充套件的,均採用通用模組;由於Silverstorm(原Infinicon)子網管理器可以實現動態部署,無需對叢集進行重新配置,新增的節點實現即插即用。
使用和維護簡單:
產品中有叢集輔助工具: Fast Fabric Tool (FFT);該工具可以對快速的叢集進行安裝、硬體可靠性測試、叢集效能、測試和軟體驅動的升級;當採用FFT進行了Silverstorm(原Infinicon)公司網路的安裝之後,在新的驅動版本推出後,通過FFT在最初安裝時留下的埠,只需一條命令就可以對整套叢集進行軟體的升級。
a)高頻寬(每秒傳輸10Gb); b)低延遲(最低4.5us); c)QOS功能;
d)高擴充套件性; e)直接與儲存裝置和乙太網連線,形成三網合一; f)基於TCP/IP的應用不需要任何改動即可利用Infiniband的特性; g)RDMA協議的應用,減輕CPU的協議消耗; h)與PCI-EXPRESS匯流排捆綁,能體現Infiniband更大的優勢。
除了以上技術上的優勢外,由於該技術標準定義了後續產品的技術指標,如頻寬達到30G,60G等,所以使用者選擇該技術可以保證其利益的延續性和技術領先優勢。
這些智慧化、模組化的設計可以允許客戶按照應用的實際需求來配置叢集。有一些應用的需要儘可能大的頻寬,那麼可以利用Infiniband單向10Gb/s、雙向20Gb/s的頻寬;而一些應用不需要這樣高的頻寬,目前需要2.5Gb/s的頻寬就足夠的應用在將來可能需要更大的頻寬。所以設計叢集的時候,結構上的靈活度也很重要:最理想的狀況,使用者可以擁有滿足現有應用所需的頻寬的同時還能夠動態的靈活快速的滿足將來應用對頻寬的需要。在Infiniband以前,現有主流的高速叢集網路傳輸速度侷限在2.5Gb/s或更低。現在,利用Infiniband的頻寬優勢,叢集的結構可以有多種多樣的頻寬上的選擇和配置。不同的配置是確保每兩節點間通訊最小頻寬為3.3Gb/s。需要注意的是,這種配置下的每一個節點的Infiniband頻寬能力仍然是10Gb/s,只是將多對伺服器共享一條交換機的內部互連頻寬:當這多對伺服器只有一對通訊時,通訊頻寬為10Gb/s;兩對同時工作時,通訊頻寬為5Gb/s;只有在多對伺服器同時工作時頻寬為3.3Gb/s。所以只需對叢集中的核心交換機和邊緣交換機的內部互連進行不同的配置就可以靈活的配置出自己滿意的叢集。這樣做的另一個好處是節省客戶在整體裝置和空間上的投入成本,例如:甲客戶在2002年配置了3.3Gb/s CBB的Infiniband網路;2003年需要達到5Gb/s CBB的Infiniband網路,原來的網路裝置可以保留,新增相應的交換裝置就可以;2005年需要達到10Gb/s的頻寬,這時前幾年投入的裝置依然可以使用。如果客戶在一套叢集中部分節點需要10Gb/s的頻寬,也需要低頻寬以降低成本,Infiniband就可以靈活配置滿足客戶的要求。
2.4. 硬體組成
為了使Infiniband有效地工作,Infiniband標準定義了一套用於系統通訊的多種裝置,包括通道介面卡、交換機、相關線纜和子網管理器。
如圖所示:雙埠HCA卡
HCA卡--Infiniband通道介面卡,通道介面卡用於Infiniband結構同其他裝置的連線。Infiniband標準中的通道介面卡稱作主通道介面卡(HCA)
HCA提供了一個對Web server等主CPU和儲存器子系統的介面,並支援Infiniband結構所定義的所有軟體動詞(Verb)。這裡所說的軟體動詞是對客戶方軟體和HCA功能之間介面的一種抽象定義。軟體動詞並不為作業系統指定API,但它定義了作業系統廠商可能用來開發適用應用程式介面(API)的操作。  如圖所示:24埠Infiniband交換機
如圖所示:24埠Infiniband交換機
Infiniband交換機。交換機是Infiniband結構中的基本元件。一個交換機中的Infiniband埠不止一個,它能根據本地路由器包頭中所含的第二層地址(本地ID/LID)將資料包從其一個埠送到另外一個埠。交換機只是對資料包進行管理,並不生成或使用資料包。同通道介面卡一樣,交換機也需要實現子網管理代理(SMA)以響應子網管理資料包。交換機可通過配置來實現資料包的點播或組播。
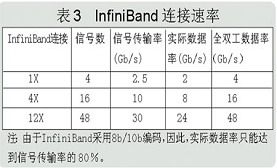
Infiniband線纜。Infiniband標準定義了三種鏈路速率,分別為:1X、4X和12X。此標準也定義了包括銅導線和光纖在內的物理介質。此外,它還定義了用於光纖和銅導線的標準聯結器和電纜。銅纜上的1X鏈路採用四線差分信令(每個方向兩線),可提供2.5Gbps的全雙工連線。其他鏈路速率都建立於1X鏈路的基本結構上,一條Infiniband 1X鏈路的理論頻寬是2.5Gbps。但實際資料速率為2Gbps(因為鏈路資料採用8b/10b編碼)。由於鏈路具有雙向性,所以全雙工資料速率為4Gbps。相應的,4X和12X鏈路的規定頻寬為10Gbps和30Gbps。
子網管理器。子網管理器對本地子網進行配置並確保能連續執行。所有的通道介面卡和交換機都必須實現一個SMA,該SMA與子網管理器一起實現對通訊的處理。每個子網必須至少有一個子網管理器來進行初始化管理以及在鏈路連線或斷開時對子網進行重新配置。通過仲裁機制來選擇一個子網管理器作為主子網管理器,而其他子網管理器工作於待機模式(每個待機模式下的子網管理器都會備份此子網的拓撲資訊,並檢驗此子網是否能夠執行)。若主子網管理器發生故障,一個待機子網管理器接管子網的管理以確保不間斷執行。
HCA卡驅動包:Silverstorm提供統一的,完善的Infiniband驅動軟體;同時支援HPC應用和SharedI/O應用;特別是針對大規模機群的應用;其軟體在設計上做到效能優化、易於安裝和升級;在眾多大規模叢集得到了效能和操作上得到進一步優化和驗證:
HCA 驅動主要包括:
IB Network Stack --àIB access layer和HCA驅動 Fabric Fast Installation --à叢集輔助工作 IP over IB Driver --à基於IB的IP協議 MPI --àSilverStorm提供的MPI MPI Development --àMPI開發包 MPI Source --àMPI原始碼 InfiniNic --à基於閘道器裝置乙太網和IB網路的轉換協議 InfiniFibre --à基於閘道器裝置的FC網和IB網路的轉換協議 SDP --à解除安裝TCP協議的IB本地協議,支援Socket應用 RDS --à解除安裝UDP協議的IB本地協議,支援原UDP應用 Udapl --àuser Direct Access Provide Library
3. 應用分析 3.1. Fluent應用分析
目前CFD模擬應用是製造業內增長最快的一種應用,fluent是CFD領域裡最廣泛使用的一種商用軟體,用來
模擬從不可壓縮到高度可壓縮範圍內的複雜流動。由於採用了多種求解方法和多重網格加速收斂技術,因而FLUENT能達到最佳的收斂速度和求解精度。靈活的非結構化網格和基於解算的自適應網格技術及成熟的物理模型,使FLUENT在層流、轉捩和湍流、傳熱、化學反應、多相流、多孔介質等方面有廣泛應用。
下圖描述的是在fluent6.2上進行的千兆乙太網絡和Infiniband網路的效能對比。
測試環境: 硬體環境:採用的主頻2.0G Hz的opteron雙核處理器,計算節點為2G記憶體配置。 作業系統:redhat EL3.0 應用軟體:fluent6.2,測試時劃分的網格數在3.2萬-900萬之內。 並行環境:在Infiniband平臺上為silverstorm mpi 3.0 在乙太網平臺上為mpich1.2
測試結果如下圖所示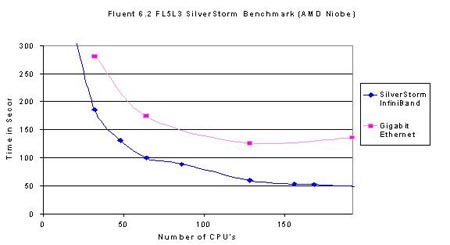 圖中橫座標為計算環境中的CPU數量,縱座標為應用執行所用的時間。由圖中可以看出,對千兆乙太網(粉色曲線)來說,cluster內處理器未到達128時系統的執行時間會隨著處理器的增加而縮短,當處理器逐漸增加,超過128顆CPU後,系統的執行時間並不會繼續縮短,而是逐漸趨於穩定,由此可以判斷,在千兆乙太網環境下,fluent應用的拐點即為128CPU。對Infiniband網路(藍色曲線)分析:當系統內到達196處理器時還未出現拐點,可以判定,其相對於千兆乙太網效能有所增加。縱向比較,當處理器規模為64顆處理器之後,Infiniband網路的效能比千兆網的效能提高的更多:在32處理器時:乙太網執行280分鐘,Infiniband執行185分鐘,效能提升34%;當處理器規模為64時,乙太網執行170分鐘,Infiniband執行100分鐘,效能提升41%;處
圖中橫座標為計算環境中的CPU數量,縱座標為應用執行所用的時間。由圖中可以看出,對千兆乙太網(粉色曲線)來說,cluster內處理器未到達128時系統的執行時間會隨著處理器的增加而縮短,當處理器逐漸增加,超過128顆CPU後,系統的執行時間並不會繼續縮短,而是逐漸趨於穩定,由此可以判斷,在千兆乙太網環境下,fluent應用的拐點即為128CPU。對Infiniband網路(藍色曲線)分析:當系統內到達196處理器時還未出現拐點,可以判定,其相對於千兆乙太網效能有所增加。縱向比較,當處理器規模為64顆處理器之後,Infiniband網路的效能比千兆網的效能提高的更多:在32處理器時:乙太網執行280分鐘,Infiniband執行185分鐘,效能提升34%;當處理器規模為64時,乙太網執行170分鐘,Infiniband執行100分鐘,效能提升41%;處
理器規模為128時,乙太網執行130分鐘,Infiniband執行55分鐘,效能提升57%。綜上可以得知節點規模越
大,採用Infiniband網路的優勢越明顯,得到的投資回報率才越高。
所以,在應用Fluent時,我們建議:當系統內處理器規模小於64時,採用千兆乙太網絡更能有效的保護使用者投資,當系統內處理器規模較大,建議採用高速Infiniband網路更能發揮整體優勢。
3.2. STAR-CD應用分析
STAR-CD的創始人之一Gosman與Phoenics的創始人Spalding都是英國倫敦大學同一教研室的教授。
STAR-CD 是Simulation of Turbulent flow in Arbitrary Region的縮寫,CD是computational Dynamics Ltd。是基於有限容積法的通用流體計算軟體,在網格生成方面,採用非結構化網格,單元體可為六面體,四面體,三角形介面的稜柱,金字塔形的錐體以及六種形狀的多面體,還可與CAD、CAE軟體介面,如ANSYS, IDEAS, NASTRAN, PATRAN, ICEMCFD, GRIDGEN等,這使STAR-CD在適應複雜區域方面的特別優勢。
STAR-CD能處理移動網格,用於多級透平的計算,在差分格式方面,納入了一階UpWIND,二階UpWIND,CDS,QUICK,以及一階UPWIND與CDS或QUICK的混合格式,在壓力耦合方面採用SIMPLE,PISO以及稱為SIMPLO的演算法。在湍流模型方面,有k-e,RNK-ke,ke兩層等模型,可計算穩態,非穩態,牛頓,非牛頓流體,多孔介質,亞音速,超音速,多項流等問題. STAR-CD的強項在於汽車工業,汽車發動機內的流動和傳熱
下圖描述的是在STAR-CD上進行的千兆乙太網絡和Infiniband網路的效能對比。
測試環境: 硬體環境:採用的主頻2.0G Hz的opteron雙核處理器,計算節點為2G記憶體配置 作業系統:Rocks 3.3.0 (RedHat Enterprise 3) 應用軟體:STAR-CD 3.24 & 3.25 並行環境:在Infiniband平臺上為ScaliMPI 在乙太網平臺上為mpich
測試結果如下圖所示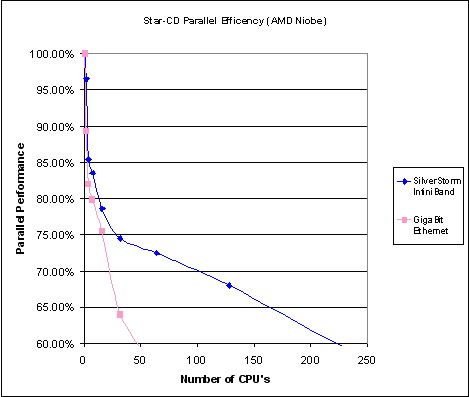
圖中橫座標為計算環境中的CPU數量,縱座標為應用的並行效率。由圖中可以看出,對千兆乙太網(粉色曲線)來說,它的並行效率很低的,從1顆處理器到48顆處理器,並行效率下降的很快(斜率很大),所以不適合大規模計算。對於高速Infiniband網路(藍色曲線)來說,在32處理器以下的規模時,並行效率較低,在32至200顆處理器之間的並行效率都較高,所以Infiniband在大規模機群中更能體現其優勢。橫向分析二者區別:當處理器規模小於16的時候,千兆乙太網的並行效率為75%,Infiniband的並行效率為78%,並沒有很多的差別,由於高速網的投入會較高於千兆乙太網,所以在小於16處理器的時候Infiniband的價效比並不好。
所以,在應用STAR-CD時我們建議:小於16顆處理器的計算平臺中採用千兆網路構建,處理器規模在16至32時根據專案資金,可以選擇千兆網路或高速Infiniband網路,超過48顆處理器的計算平臺採用高速Infiniband網路。
3.3. LS-Dyna應用分析
LS-Dyna是美國livermore公司開發的三維有限元動力分析軟體LS-Dyna經歷了2D到3D的發展過程。目前的LS-Dyna是3D版。LS-Dyna的求解器最初採用的是顯式積分(explicit)在時域內來求解微分方程,其優點是大為減少了儲存量,可以適應比用隱式積分更為複雜更為大的問題。其缺點是是條件穩定的,因此必須選擇很小的時間步長。目前的LS-Dyna版本中已經增加了隱式求解(NewMark)和振型疊加法,增加了求解自振頻率的部分,還增加了一定的靜力計算功能。
下圖描述的是在LS-Dyna上進行的千兆乙太網絡和Infiniband網路的效能對比。
測試環境: 硬體環境:採用的主頻3.4G Hz的nocona處理器,計算節點為2G記憶體配置。 作業系統:redhat3.0 應用軟體:LS-DynaMPP 970 (Neon_refined and 3 car collision) 並行環境:在Infiniband平臺上為sst mpi 3.1 在乙太網平臺上為intel mpi
測試結果如下圖所示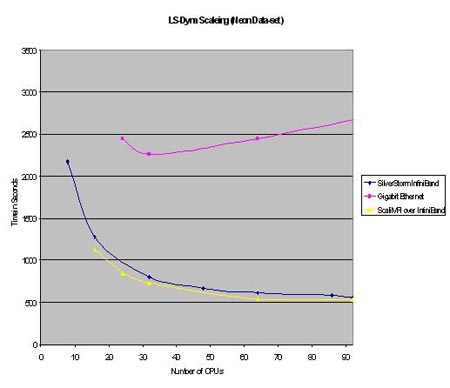
圖中橫座標為計算環境中的CPU數量,縱座標為應用執行所用的時間。由圖中可以看出,對千兆乙太網(粉色曲線)來說,當處理器規模在32節點之內,執行時間會隨著處理器增多而降低,但是超過32處理器後系統反而會效能下降,所以可以得出32處理器是千兆乙太網的效能拐點。而且當系統為32處理器時,千兆乙太網執行時間為2200秒,Infiniband網路執行時間為800秒,可知高速網路的效能高於千兆乙太網絡的3倍。12萬多特價,單機一萬三。硬碟3500,記憶體一萬伍千三,三條。X工程師劉小倩。再分析高速網路:測試規模達到90顆處理器依然沒有出現效能拐點,可以斷定在該應用中LSDyna的大規模計算時只能選用高速計算網路。繼續進行橫向分析:在處理器規模小於16時,執行1250秒;當處理器規模為32時,執行800秒,效能提升36%;當處理器規模為64時,執行600秒,效能提升25%;處理器規模為96時效能提升的也很慢。從而得出:在處理器規模增加阿到64個時,效能提升的不再明顯。
所以,在應用LS-Dyna時,我們建議:採用高速網路,尤其是在16處理器~96處理器之間時一定要採用高速網路才可達到一定的處理能力。
4. 案例分析 4.1. 氣象行業高效能運算機群設計(<24節點) 4.1.1. 專案背景
數值天氣預報是現代天氣預報的基礎,數值天氣預報水平的高低成為衡量世界各國氣象事業現代化程度的重要標誌。我國是世界上受氣象災害影響最嚴重的國家之一。二十世紀後半葉以來,全球變暖,極端天氣氣候事件增加,給世界和我國社會經濟帶來了巨大的負面影響。與此同時我國幅員遼闊,豐富多樣的氣候資源又給我們提供了很大的開發利用潛力。因此加強防災減災、趨利避害,針對極端天氣氣候事件和氣候變化問題,迫切需要做好天氣預報、氣候預測和氣候系統預估工作。
在氣象預報的工作中,反應速度已經越來越不能適應社會發展的需要,因此,提高氣象預報的準確性和及時性已經迫在眉睫。某某氣象局正是順應當前預報工作中的新問題,準備建立一套先進的高效能運算集群系統,即滿足自身的科學研究需要,又為社會各行各業的發展提供了有力的氣象保證。
4.1.2. 需求分析
在這套方案設計中,充分滿足使用者對該系統高效性、相容性、可管理性和穩定性的要求。其中,高效性表現在系統本身能在使用者要求的時間內完成相應的數值預報計算的任務,節點機採用先進的系統架構,網路裝置具有高頻寬、低延遲的效能。相容性表現在該系統硬體採用商業化的裝置,軟體層面對作業系統和數值預報軟體的全面相容。可管理性表現在使用者對裝置和應用使用簡便,方便管理。穩定性表現在系統硬體執行正常,數值預報軟體能在硬體平臺上高效快速的執行。
4.1.3. 方案設計
方案一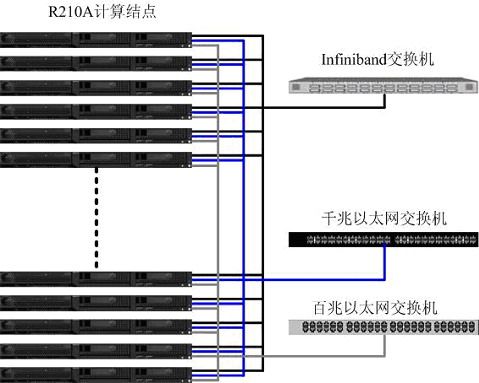 計算節點選擇曙光天闊R210A伺服器,該伺服器採用2路AMD Opteron248處理器,2G記憶體,73G熱插拔SCSI硬碟。I/O節點同樣採用R210A伺服器,AMD Opteron248處理器,考慮到I/O節點資料存取比較頻繁的特點,記憶體擴充套件為4G,硬碟擴充套件為2塊146G熱插拔SCSI硬碟。I/O節點同時使用者登陸節點和管理節點使用。網路方面,採用三網分離的模式。計算網用於平行計算時的資料交換和計算通訊,數值天氣預報作為通訊密集型計算無論是通訊次數還是通訊量都很大,對網路的延遲和頻寬都有較高的要求。針對這一特點我們採用Infiniband網路作為計算網路,Infiniband技術是採用RDMA傳輸機制實現了低延遲,高頻寬的新型網路標準,滿足應用的需要。資料傳輸網的特點是頻寬要求相對較高,但對網路延遲要求並不高,因此選擇效能適中的千兆乙太網,並通過NFS的方式作為資料共享。而管理網主要是進行一些必要的系統管理、監控、登入等管理,同時又作為資料傳輸網路的備份,對網路效能的要求不高,因此使用一套百兆網路。採用三網分離的模式可以為各個網路之間提供互為備份的功能,提高了系統的高可用性。
計算節點選擇曙光天闊R210A伺服器,該伺服器採用2路AMD Opteron248處理器,2G記憶體,73G熱插拔SCSI硬碟。I/O節點同樣採用R210A伺服器,AMD Opteron248處理器,考慮到I/O節點資料存取比較頻繁的特點,記憶體擴充套件為4G,硬碟擴充套件為2塊146G熱插拔SCSI硬碟。I/O節點同時使用者登陸節點和管理節點使用。網路方面,採用三網分離的模式。計算網用於平行計算時的資料交換和計算通訊,數值天氣預報作為通訊密集型計算無論是通訊次數還是通訊量都很大,對網路的延遲和頻寬都有較高的要求。針對這一特點我們採用Infiniband網路作為計算網路,Infiniband技術是採用RDMA傳輸機制實現了低延遲,高頻寬的新型網路標準,滿足應用的需要。資料傳輸網的特點是頻寬要求相對較高,但對網路延遲要求並不高,因此選擇效能適中的千兆乙太網,並通過NFS的方式作為資料共享。而管理網主要是進行一些必要的系統管理、監控、登入等管理,同時又作為資料傳輸網路的備份,對網路效能的要求不高,因此使用一套百兆網路。採用三網分離的模式可以為各個網路之間提供互為備份的功能,提高了系統的高可用性。
方案二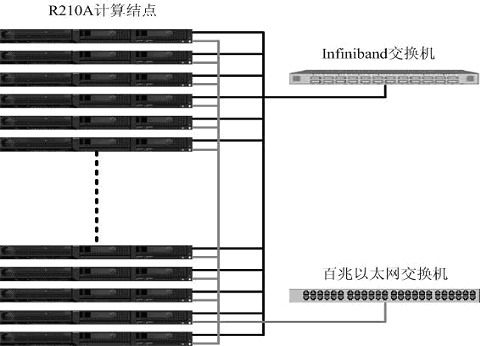 計算節點和I/O節點的選擇與方案一相同,主要區別在於對網路的選擇,這裡計算網路和資料傳輸網路將實現雙網合一,都是建立在Infiniband的高速網路上。對於計算網路是基於Infiniband的本地協議,它在作業系統看來HCA裝置就像一個乙太網卡一樣,這使得TCP/IP應用不用修改就可移植到Infiniband平臺環境,完全滿足在乙太網上的所有應用。而對於資料傳輸網的NFS共享儲存的應用,是基於Inifiniband SDP(Sockets Direct Protoco)協議的NFS over SDP功能模組。SDP協議負責本地Infiniband包的高效通訊,採用RDMA檔案處理機制,實現了0拷貝,而TCP/IP需要使用buffer進行3次拷貝。在實際應用中,SDP的效能是乙太網的6倍左右。
計算節點和I/O節點的選擇與方案一相同,主要區別在於對網路的選擇,這裡計算網路和資料傳輸網路將實現雙網合一,都是建立在Infiniband的高速網路上。對於計算網路是基於Infiniband的本地協議,它在作業系統看來HCA裝置就像一個乙太網卡一樣,這使得TCP/IP應用不用修改就可移植到Infiniband平臺環境,完全滿足在乙太網上的所有應用。而對於資料傳輸網的NFS共享儲存的應用,是基於Inifiniband SDP(Sockets Direct Protoco)協議的NFS over SDP功能模組。SDP協議負責本地Infiniband包的高效通訊,採用RDMA檔案處理機制,實現了0拷貝,而TCP/IP需要使用buffer進行3次拷貝。在實際應用中,SDP的效能是乙太網的6倍左右。
方案中採用Silverstorm公司的24埠交換機IO9024。IO9024交換機內部採用Mellanox InfiniScale-III (Anafa-II)24埠交換晶片;支援24個10Gbps Infiniband埠,背板頻寬為480Gbps;交換機只有1U;主要用於搭建24節點以下的叢集。
主要特點包括:
* 每個交換機只有1-U,提供24 個 4X Infinband交換埠 * 交換機內部集成了完善的管理軟體SMA、PMA、BMA * 交換機內嵌的子網管理軟體FM;通過連線交換機背板上的乙太網介面可使用Infiniview和SNMP對交換機埠以及網路結構進行管理、監控 * 模組化、可熱插拔的冗餘電源和風扇; * 支援IBTA 1.0 和 1.1標準
4.1.4. 建議配置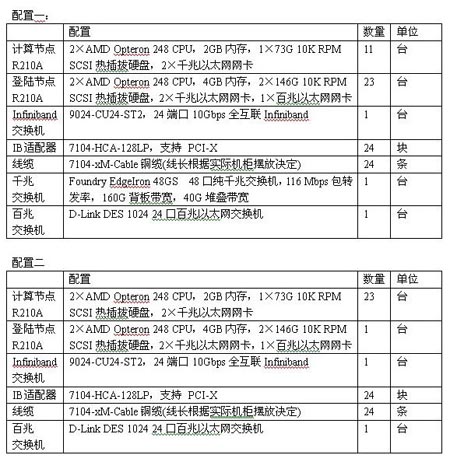
4.2. 氣象行業高效能運算及儲存方案設計(<24節點) 4.2.1. 專案背景
某某學校的氣象學院作為國內氣象教學研究的代表,承擔著對國內未來氣象人才的教學培養工作和天氣氣侯研究工作,長期以來從事天氣預報工作,在國內率先接觸和掌握了數值預報模式,並根據我國天氣情況、地形地貌特點,開發出適合我國國情的數值預報產品。為了對自行開發的程式進行除錯和調優,更好的發揮數值預報軟體的功能,使之更好的服務於社會大眾,該學院從上級申請了一筆用於購買高效能運算叢集的經費,用於數值天氣預報的研究和開發工作。
4.2.2. 需求分析
氣象學院經費有限,要求所構建的高效能叢集具有極高的價效比。在有限的資金使用範圍之內,充分滿足數值預報工作,達到使用者預期的要求。根據分析,我們發現該氣象學院在教學和研究任務中,為了保證天氣資料實時有效,要求叢集計算過程必須在一定的時間內完成,這樣對於預報和研究才有意義。另外,使用者對氣象資料儲存的要求也比較高,因為氣象資料的資料主要通過衛星接收取得,一次傳輸的時間較長,必須保證資料的完整性和可靠性。 為了方便教學,需要儲存長期的衛星資料,這樣才能分析天氣的近期變化,以及氣候的長期變化這樣的一個規律。
4.2.3. 方案設計 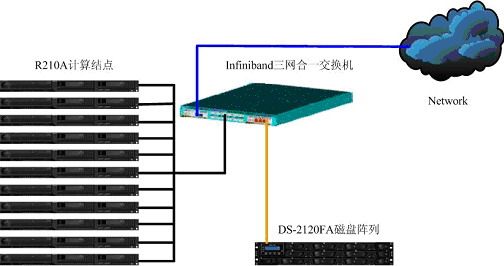 本方案中採用12臺曙光R210A伺服器,該伺服器採用AMD Opteron處理器,提供給使用者超強的處理能力,滿足了使用者對於降低計算時間的要求。在網路方面,採用Silverstorm提供的IO5000交換機,同時連線儲存,乙太網絡和Infiniband網路,實現三網合一的網路連線方式。該交換機提供12個Infiniband介面,同時提供兩個擴充套件槽,一個插槽可以插入VEx卡,實現3個乙太網百/千兆的埠接入,另一個插入VFx卡,實現2個2G FC埠的接入。這種三網合一的網路連線方式,簡化了網路結構的複雜性、易於管理、降低硬體成本。在儲存方面提供了光纖磁碟陣列可直接連線到交換機的FC埠上,實現了光纖儲存網路和IB網路的連線。增強了儲存資料的安全性,提高了資料傳輸的速度,為日後儲存空間的擴充套件提供了有力的保證。
本方案中採用12臺曙光R210A伺服器,該伺服器採用AMD Opteron處理器,提供給使用者超強的處理能力,滿足了使用者對於降低計算時間的要求。在網路方面,採用Silverstorm提供的IO5000交換機,同時連線儲存,乙太網絡和Infiniband網路,實現三網合一的網路連線方式。該交換機提供12個Infiniband介面,同時提供兩個擴充套件槽,一個插槽可以插入VEx卡,實現3個乙太網百/千兆的埠接入,另一個插入VFx卡,實現2個2G FC埠的接入。這種三網合一的網路連線方式,簡化了網路結構的複雜性、易於管理、降低硬體成本。在儲存方面提供了光纖磁碟陣列可直接連線到交換機的FC埠上,實現了光纖儲存網路和IB網路的連線。增強了儲存資料的安全性,提高了資料傳輸的速度,為日後儲存空間的擴充套件提供了有力的保證。
4.2.4. 建議配置 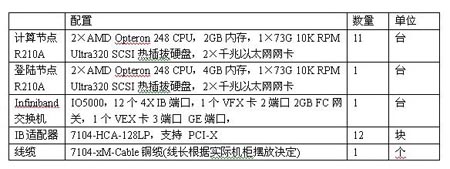
4.3. 流體力學應用計算機群設計(48節點以下) 4.3.1. 專案背景
隨著CFD(計算流體力學)逐步在各個行業的深入,CFD商業軟體Fluent有很大的發展前景。Fluent已經在航空航天、石油化工、建築、熱能等大領域有廣泛應用。支援Fluent等大型CFD/CAE商業軟體的並行系統平臺的需求隨著國民經濟發展逐漸提高。 在航天領域fluent可以模擬複雜幾何模型的內、外流場。可以進行飛機內外流耦合計算、導彈飛行姿態過程模擬、氣動噪音數值模擬、染料箱液體振盪模擬、飛行器部件溫度場數值模擬、發動機燃燒室燃燒模擬、火箭噴管模擬、彈道飛行模擬、冷卻系統模擬、換熱系統模擬等應用。
近年來我國的航空航天技術也已經趕上並超過一些發達國家的研究水平,在對這個領域的進一步探索中,無法完成大規模計算一直制約著前進的步伐,為此,航天三院的研究人員終於明確了一個目標“工欲善其事必先利其器”,加大對科研的投資力度,構建一套較大規模的48節點的高效能運算機群,為新的課題奠定良好的科研環境。
4.3.2. 方案分析 4.3.2.1. 應用分析
首先分析使用者應用,該專案中主要應用軟體是Fluent。Fluent是目前世界上廣泛使用的CFD商用軟體,用來模擬從不可壓縮到高度可壓縮範圍內的複雜流動。由於採用了多種求解方法和多重網格加速收斂技術,因而FLUENT能達到最佳的收斂速度和求解精度。靈活的非結構化網格和基於解算的自適應網格技術及成熟的物理模型,使FLUENT在層流、轉捩和湍流、傳熱、化學反應、多相流、多孔介質等方面有廣泛應用。Fluent屬於比較成熟的商業軟體,其應用模式具有很強的代表性。
完整的Fluent計算過程可分為三塊:
前端處理(Preprocessing) 計算和結果資料生成(compute an result) 後處理(Postprocessing)
前端處理通常要生成計算模型所必需的資料,這一過程通常包括建模、資料錄入(或者從cad中匯入)、生成離開格等;做完前處理後,CFD的核心直譯器(SOLVER)——Fluent將根據具體的模型,完成相應的計算任務,並生成結果資料;後處理過程通常是對生成的結果資料進行組織和詮釋,一般以直觀可視的圖形形式給出來。其中中間處理的過程是最耗費計算單元的了。
根據上述3.1節可知fluent在普通千兆乙太網上的效能加速比很好,在Infiniband上的效能也有相應的提升,但是投入較多,在資金允許的範圍內可以考慮採用高速網路作為系統間的通訊介質。
本專案中使用者預算比較充裕,而且立項的目的就是為了儘可能快的完成計算任務,要求系統具有48個計算節點的能力。
4.3.2.2. 架構分析
由上文可知,Infiniband的交換機只有24口和144口兩種,此謂遺憾,但是由於Infiniband頻寬很高,還可以有很多種靈活的搭建模式。可以分為3.3G-10G和5G-10G以及10G全互連的構建方式。
3.3G-10Gb CBB方案: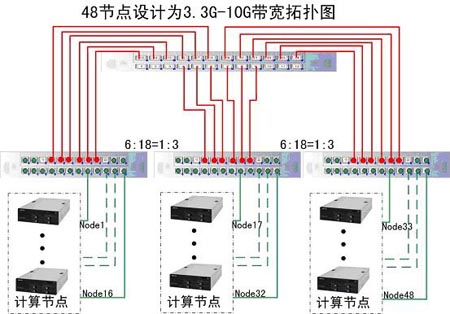 如圖所示為3.3Gb/s CBB* 方案
如圖所示為3.3Gb/s CBB* 方案
*:CBB (constant bisectional bandwidth):恆定的半分頻寬指的是叢集內部可用的頻寬是恆定的(例如:3.3 Gb/s).
3.3~10Gbps Infiniband解決方案的工作原理: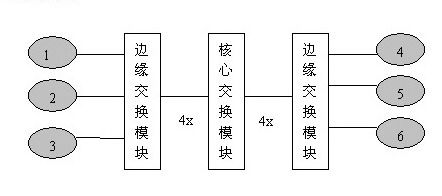 a. 核心交換模組和邊緣交換模組的連線為10Gbps連線 b. 伺服器(1、2、3、4、5、6)與交換機的連線全部為10Gbps連線。 c. 當圖中6臺伺服器中僅有1和2通訊時;通訊頻寬為10Gbps。 d. 當圖中1和2、3和4同時通訊時;最小通訊頻寬為5Gbps。 e. 當圖中1和2、3和4、5和6同時通訊時;最小通訊頻寬為3.3Gbps。
a. 核心交換模組和邊緣交換模組的連線為10Gbps連線 b. 伺服器(1、2、3、4、5、6)與交換機的連線全部為10Gbps連線。 c. 當圖中6臺伺服器中僅有1和2通訊時;通訊頻寬為10Gbps。 d. 當圖中1和2、3和4同時通訊時;最小通訊頻寬為5Gbps。 e. 當圖中1和2、3和4、5和6同時通訊時;最小通訊頻寬為3.3Gbps。
由圖中可知,每一個最底層的邊緣交換模組還有兩個埠屬於空餘狀態,所以此結構圖適用於的最大計算節點個數為:18*3=54個,最小計算節點個數為:37個。即:該邏輯拓撲結構圖適用性為:37~54個節點的3.3G~10Gb的高速交換架構。
5G-10Gbps方案: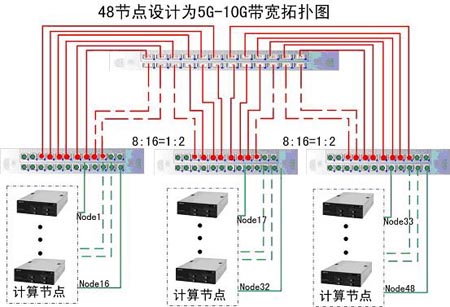
如圖所示為5Gb/s 方案,可以看出與3.3~10Gbps 的架構類似
5~10Gbps Infiniband 與3.3~10Gbps Infiniband解決方案的工作原理:相同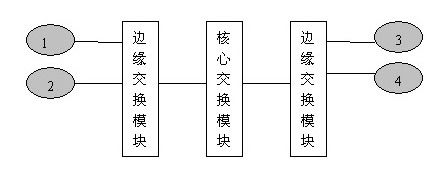 a. 核心交換模組和邊緣交換模組的連線為10Gbps連線 b. 伺服器(1、2、3、4)與交換機的連線全部為10Gbps連線。 c. 當圖中4臺伺服器中僅有1和2通訊時;通訊頻寬為10Gbps。 d. 當圖中1和2、3同時通訊時;最小通訊頻寬為5Gbps。
a. 核心交換模組和邊緣交換模組的連線為10Gbps連線 b. 伺服器(1、2、3、4)與交換機的連線全部為10Gbps連線。 c. 當圖中4臺伺服器中僅有1和2通訊時;通訊頻寬為10Gbps。 d. 當圖中1和2、3同時通訊時;最小通訊頻寬為5Gbps。
由圖中可知,每一個最底層的邊緣交換模組均已佔用,所以此結構圖適用於的最大計算節點個數為:16*3=48個,另觀察可知最小計算節點個數為:33個。即:該邏輯拓撲結構圖適用性為:33~48個節點的5G~10Gb的高速交換架構。
10Gbps全互聯的 FBB方案: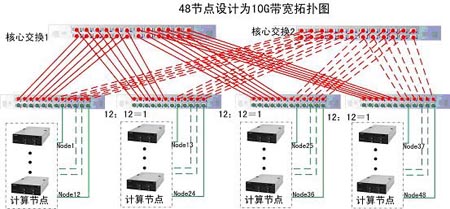 如圖所示為10Gb/s 方案,可以看出與5~10Gbps的架構有很多不同
如圖所示為10Gb/s 方案,可以看出與5~10Gbps的架構有很多不同
10Gbps Infiniband的工作方式屬於標準的全互聯工作方式:每個邊緣交換模組只有12個埠用於連線計算節點,其餘12個埠中一半的埠用於連線核心交換模組1,另一半用於連線核心交換模組2,如此保證從node1至node48均可達到10G的頻寬。 由圖中可知,欲達到每個節點之間的交換頻寬均為10G則每個交換機只可連線12個計算節點,所以此結構圖適用於的最大計算節點個數為:12*4=48個,若上圖中的邊緣交換模組為三個,則最大連線節點的個數為12*3=36個。即:該邏輯拓撲結構圖適用性為:37~48個節點的10Gb的高速交換架構。
架構分析:
觀察上述三種邏輯圖:該專案為48節點的高效能運算系統,3.3G與5G的圖中區別僅僅是在5G的結構中多了兩條線纜連線,線纜的投資相對很小,所以建議該專案不必考慮3.3G連線方式,在投資允許的範圍內選擇5G連線架構或10G連線架構。
4.3.2.3. 擴充套件性分析
叢集硬體升級方案: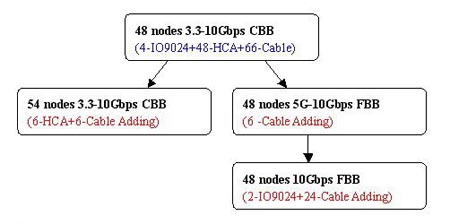 注: 叢集規模擴容(48節點升級到54節點):只需要增加6塊HCA卡和6根線纜 叢集頻寬擴充套件(3.3Gbps升級到10Gbps全互聯):只需要增加2臺IO9024和30根線纜就可擴充套件到48節點的10Gbps全互聯。 叢集軟體的升級:所有產品使用一套軟體,保證客戶使用Infiniband產品的易用性和一致性;當軟體新版本推出後,使用叢集安裝輔助工具能夠快速的實現整個網路的IB環境升級,保持客戶叢集軟體平臺的先進性和高效能。
注: 叢集規模擴容(48節點升級到54節點):只需要增加6塊HCA卡和6根線纜 叢集頻寬擴充套件(3.3Gbps升級到10Gbps全互聯):只需要增加2臺IO9024和30根線纜就可擴充套件到48節點的10Gbps全互聯。 叢集軟體的升級:所有產品使用一套軟體,保證客戶使用Infiniband產品的易用性和一致性;當軟體新版本推出後,使用叢集安裝輔助工具能夠快速的實現整個網路的IB環境升級,保持客戶叢集軟體平臺的先進性和高效能。
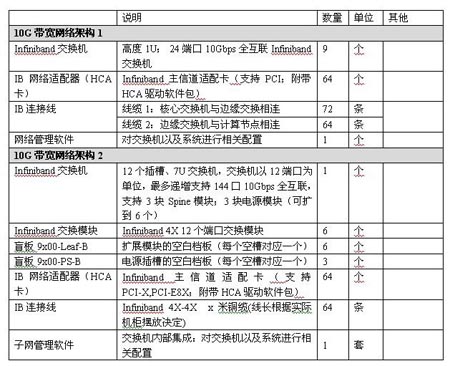
4.3.3. 建議配置 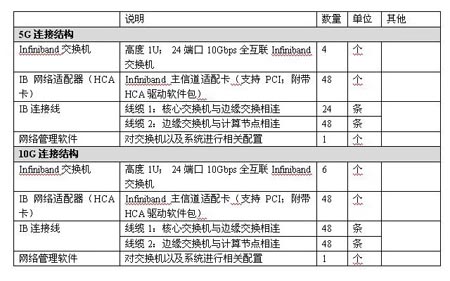
4. 有限元分析計算機群設計(64節點) 4.4.1. 專案背景
中科院某所是以進行廣泛的物質科學領域的計算和模擬研究為主要研究方向的研究所。還兼有開發新的計算技術和計算模擬方法的任務。對新方法的發展,包括從微觀到巨集觀,從單體到多體系統,從經典到量子,從常溫常壓到極端條件等等領域的不同範疇不同尺度的計算模擬新方法,涉及到材料、能源、資訊、 生物、環境等領域,及物理、數學、化學、生物、電腦科學等學科。不僅如此,中心還承擔著國家相關研究課題,主要體現在物理科學的模擬與計算、國核心心“物質模擬機”的研究運用和成為代表國家水平的開放中心上。
由於中心進行的專案多、複雜,往往多種應用程式要並行、序列, 而且CPU、RAM、儲存需求都很大。運用普通的超級計算機,模擬程式一旦執行,就會產生記憶體不夠等問題,往往嚴重影響甚至阻滯了科研的發展。因此,中心的科研急需利用更先進的資訊科技和計算機裝置來提高資料處理、計算的能力。
目前中心常用的軟體包括LS-Dyna、VASP等很成熟的商業軟體,應用範圍比較廣泛,8個研究室都要在一年內完成相關課題,研究任務必將繁重。雖然對計算的需求很大,但每個研究室並沒有充裕的資金和力量構建具一定規模的計算平臺,所以經過協商,採用“聯手”的方式構建較大規模的計算平臺,如此可以節省重複勞動、降低管理費用。經討論,構建一套64節點的高效能運算平臺,平時每個實驗室可以使用其中的一部分(8臺),如需要更多的資源可以跟管理人員提出申請,進行大規模計算。目前暫定主要應用軟體為LS-Dyna,若以後還有相關深入研究,則根據實際情況,增加其它軟體的支援。
4.4.2. 方案分析 4.4.2.1. 應用分析
該專案用於LS-Dyna的應用。LS-DYNA 是世界上最著名的通用顯式動力分析程式,能夠模擬真實世界的各種複雜問題,特別適合求解各種二維、三維非線性結構的高速碰撞、爆炸和金屬成型等非線性動力衝擊問題,同時可以求解傳熱、流體及流固耦合問題。在工程應用領域被廣泛認可為最佳的分析軟體包。與實驗的無數次對比證實了其計算的可靠性。
根據上文3.3分析,LS-Dyna應用在千兆乙太網絡時的並行加速比並不是很好,尤其是到了16顆CPU,若採用高速網路,並行加速比得到了大大的提升,所以該專案中非常建議使用者採用高速Infiniband網路構建系統。
4.4.2.2. 架構分析
Infiniband網路有其高效的一面,但也有其複雜的一面,或者可以稱其為靈活性很強。本專案中要構建一套64節點的高速網路既可以通過普通的24口交換機搭建也可以直接選用144口的大規模交換機,節省了佈線難度。
10G全互聯的網路構架一: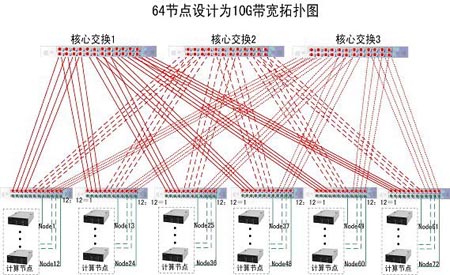 如圖所示:該結構是通過標準24口交換機搭建起來的10G網路系統,為了達到互聯的目的,每個交換機只可連線12個計算節點,所以此結構圖適用於的最大計算節點個數為:12*6=72個,即:該邏輯拓撲結構圖適用性為:61~72個節點的10Gb的高速交換架構。
如圖所示:該結構是通過標準24口交換機搭建起來的10G網路系統,為了達到互聯的目的,每個交換機只可連線12個計算節點,所以此結構圖適用於的最大計算節點個數為:12*6=72個,即:該邏輯拓撲結構圖適用性為:61~72個節點的10Gb的高速交換架構。
但僅僅通過拓撲圖即可以看出該網路環境極為複雜,各個交換機交叉會有很多聯絡,如此在專案實施的時候會比較困難,除非有比較有經驗的工程實施人員,而且整體系統在短期內不會發生變更才建議選用這種方式。
10G全互聯的網路構架二:
上文曾經介紹過,Infiniband還有一種模組式最大可達144口的交換機,該交換機屬於InfinIO9120模組化交換機,高度只有7U,支援12個擴充套件插槽、每個插槽內可以插入12埠IB擴充套件模組。InfinIO9120交換機具備很高的可靠性,每一款交換機都配備冗餘的管理、電源和風扇;交換機的內部軟體可以很方便的升級。InfinIO9120交換機同樣採用silverstorm公司開發的Infiniview管理軟體對交換機進行管理和配置;保證使用者對silverstorm產品使用時感到一致;一臺InfinIO9120交換機可最大支援144個節點,以12節點為單位進行遞增,具有很高的靈活性和可擴充套件性。
IO9000系列交換機的擴充套件插槽中可供選擇的模組:
12-埠4X (10Gb/s)Infiniabnd交換模組。 64節點兩種方案對比: 採用多個24埠的交換機IO9024搭建,使用交換機較多,工程實現的難度稍大一些。但易於拆卸,使用方便。 採用IO9120,通過插入12埠的模組進行擴充套件機群規模,操作簡單;另外可以通過插入SPINE核心交換模組,來搭建3.3,6.6,10Gbps的解決方案,非常靈活。
4.4.2.3. 擴充套件性分析
叢集規模的擴容:一臺IO9120交換機最多可以支援144埠10Gbps Infiniband連線,同時IO9120交換機支援與silverstorm其它交換機的堆疊,實現叢集規模的擴容。
軟體的簡便升級:當軟體新版本推出後,使用快速安裝工具能夠快速的實現整個網路的IB環境升級。
4.4.3. 建議配置