
ElasticSearch6.2.4(18)——Elasticsearch Suggester詳解
現代的搜尋引擎,一般會具備"Suggest As You Type"功能,即在使用者輸入搜尋的過程中,進行自動補全或者糾錯。 通過協助使用者輸入更精準的關鍵詞,提高後續全文搜尋階段文件匹配的程度。例如在Google上輸入部分關鍵詞,甚至輸入拼寫錯誤的關鍵詞時,它依然能夠提示出使用者想要輸入的內容:
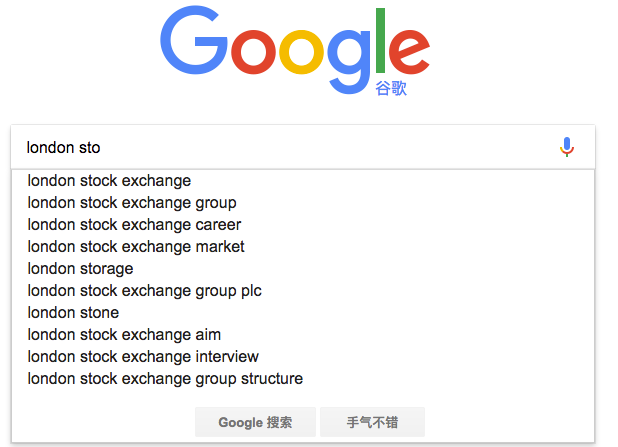
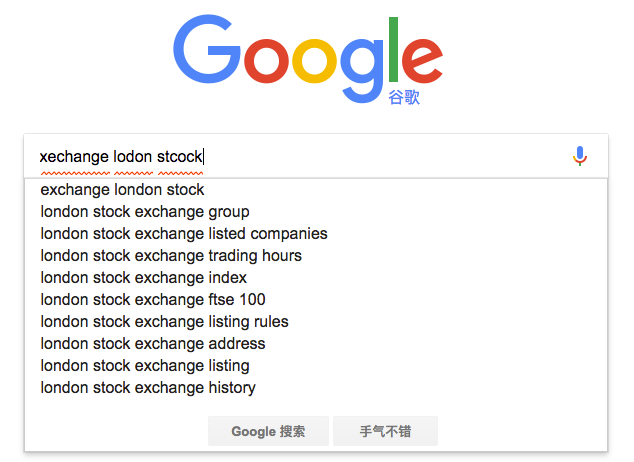
如果自己親手去試一下,可以看到Google在使用者剛開始輸入的時候是自動補全的,而當輸入到一定長度,如果因為單詞拼寫錯誤無法補全,就開始嘗試提示相似的詞。 那麼類似的功能在Elasticsearch裡如何實現呢? 答案就在Suggesters API。 Suggesters基本的運作原理是將輸入的文字分解為token,然後在索引的字典裡查詢相似的term並返回。 根據使用場景的不同,Elasticsearch裡設計了4種類別的Suggester,分別是:
- Term Suggester
- Phrase Suggester
- Completion Suggester
- Context Suggester
在官方的參考文件裡,對這4種Suggester API都有比較詳細的介紹,但苦於只有英文版,部分國內開發者看完文件後仍然難以理解其運作機制。 本文將在Elasticsearch 5.x上通過示例講解Suggester的基礎用法,希望能幫助部分國內開發者快速用於實際專案開發。限於篇幅,更為高階的Context Suggester會被略過。 首先來看一個Term Suggester的示例: 準備一個叫做blogs的索引,配置一個text欄位。
PUT /blogs/ { "mappings": { "tech": { "properties": { "body": { "type": "text" } } } } }
通過bulk api寫入幾條文件
POST _bulk/?refresh=true { "index" : { "_index" : "blogs", "_type" : "tech" } } { "body": "Lucene is cool"} { "index" : { "_index" : "blogs", "_type" : "tech" } } { "body": "Elasticsearch builds on top of lucene"} { "index" : { "_index" : "blogs", "_type" : "tech" } } { "body": "Elasticsearch rocks"} { "index" : { "_index" : "blogs", "_type" : "tech" } } { "body": "Elastic is the company behind ELK stack"} { "index" : { "_index" : "blogs", "_type" : "tech" } } { "body": "elk rocks"} { "index" : { "_index" : "blogs", "_type" : "tech" } } { "body": "elasticsearch is rock solid"} { "index" : { "_index" : "blogs", "_type" : "tech" } } { "body": "lucene and elasticsearch rocks"}
此時blogs索引裡已經有一些文件了,可以進行下一步的探索。為幫助理解,我們先看看哪些term會存在於詞典裡。 將輸入的文字分析一下:
POST _analyze
{
"text": [
"Lucene is cool",
"Elasticsearch builds on top of lucene",
"Elasticsearch rocks",
"Elastic is the company behind ELK stack",
"elk rocks",
"elasticsearch is rock solid"
]
}(由於結果太長,此處略去) 這些分出來的token都會成為詞典裡一個term,注意有些token會出現多次,因此在倒排索引裡記錄的詞頻會比較高,同時記錄的還有這些token在原文件裡的偏移量和相對位置資訊。 執行一次suggester搜尋看看效果:
POST blogs/_search
{
"size":0,
"suggest":{
"text":"lucne rock",
"my_suggest1":{
"term":{
"field":"body",
"suggest_mode":"missing"
}
}
}
}suggest就是一種特殊型別的搜尋,DSL內部的"text"指的是api呼叫方提供的文字,也就是通常使用者介面上使用者輸入的內容。這裡的lucne是錯誤的拼寫,模擬使用者輸入錯誤。 "term"表示這是一個term suggester。 "field"指定suggester針對的欄位,另外有一個可選的"suggest_mode"。 範例裡的"missing"實際上就是預設值,它是什麼意思?有點撓頭... 還是先看看返回結果吧:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
},
"suggest": {
"my_suggest1": [
{
"text": "lucne",
"offset": 0,
"length": 5,
"options": [
{
"text": "lucene",
"score": 0.8,
"freq": 2
}
]
},
{
"text": "rock",
"offset": 6,
"length": 4,
"options": [
{
"text": "rocks",
"score": 0.75,
"freq": 2
}
]
}
]
}
}在返回結果裡"suggest" -> "my-suggestion"部分包含了一個數組,每個陣列項對應從輸入文字分解出來的token(存放在"text"這個key裡)以及為該token提供的建議詞項(存放在options數組裡)。 示例裡返回了"lucne","rock"這2個詞的建議項(options),其中"rock"的options是空的,表示沒有可以建議的選項,為什麼? 上面提到了,我們為查詢提供的suggest mode是"missing",由於"rock"在索引的詞典裡已經存在了,夠精準,就不建議啦。 只有詞典裡找不到詞,才會為其提供相似的選項。 如果將"suggest_mode"換成"popular"會是什麼效果? 嘗試一下,重新執行查詢,返回結果裡"rock"這個詞的option不再是空的,而是建議為rocks。
"suggest": {
"my_suggest1": [
{
"text": "lucne",
"offset": 0,
"length": 5,
"options": [
{
"text": "lucene",
"score": 0.8,
"freq": 2
}
]
},
{
"text": "rock",
"offset": 6,
"length": 4,
"options": [
{
"text": "rocks",
"score": 0.75,
"freq": 2
}
]
}
]
}回想一下,rock和rocks在索引詞典裡都是有的。 不難看出即使使用者輸入的token在索引的詞典裡已經有了,但是因為存在一個詞頻更高的相似項,這個相似項可能是更合適的,就被挑選到options裡了。 最後還有一個"always" mode,其含義是不管token是否存在於索引詞典裡都要給出相似項。 有人可能會問,兩個term的相似性是如何判斷的? ES使用了一種叫做Levenstein edit distance的演算法,其核心思想就是一個詞改動多少個字元就可以和另外一個詞一致。 Term suggester還有其他很多可選引數來控制這個相似性的模糊程度,這裡就不一一贅述了。 Term suggester正如其名,只基於analyze過的單個term去提供建議,並不會考慮多個term之間的關係。API呼叫方只需為每個token挑選options裡的詞,組合在一起返回給使用者前端即可。 那麼有無更直接辦法,API直接給出和使用者輸入文字相似的內容? 答案是有,這就要求助Phrase Suggester了。 Phrase suggester在Term suggester的基礎上,會考量多個term之間的關係,比如是否同時出現在索引的原文裡,相鄰程度,以及詞頻等等。看個範例就比較容易明白了:
POST blogs/_search
{
"size":0,
"suggest":{
"text":"lucne and elasticsear rock",
"my_suggest1":{
"phrase":{
"field":"body",
"highlight":{
"pre_tag":"<div>",
"post_tag":"</div>"
}
}
}
}
}返回結果:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
},
"suggest": {
"my_suggest1": [
{
"text": "lucne and elasticsear rock",
"offset": 0,
"length": 26,
"options": [
{
"text": "lucene and elasticsearch rock",
"highlighted": "<div>lucene</div> and <div>elasticsearch</div> rock",
"score": 0.104138166
},
{
"text": "lucene and elasticsear rocks",
"highlighted": "<div>lucene</div> and elasticsear <div>rocks</div>",
"score": 0.10027636
},
{
"text": "lucne and elasticsearch rocks",
"highlighted": "lucne and <div>elasticsearch rocks</div>",
"score": 0.084910564
},
{
"text": "lucene and elasticsear rock",
"highlighted": "<div>lucene</div> and elasticsear rock",
"score": 0.082233466
},
{
"text": "lucne and elasticsearch rock",
"highlighted": "lucne and <div>elasticsearch</div> rock",
"score": 0.06963246
}
]
}
]
}
}options直接返回一個phrase列表,由於加了highlight選項,被替換的term會被高亮。因為lucene和elasticsearch曾經在同一條原文裡出現過,同時替換2個term的可信度更高,所以打分較高,排在第一位返回。Phrase suggester有相當多的引數用於控制匹配的模糊程度,需要根據實際應用情況去挑選和除錯。 最後來談一下Completion Suggester,它主要針對的應用場景就是"Auto Completion"。 此場景下使用者每輸入一個字元的時候,就需要即時傳送一次查詢請求到後端查詢匹配項,在使用者輸入速度較高的情況下對後端響應速度要求比較苛刻。因此實現上它和前面兩個Suggester採用了不同的資料結構,索引並非通過倒排來完成,而是將analyze過的資料編碼成FST和索引一起存放。對於一個open狀態的索引,FST會被ES整個裝載到記憶體裡的,進行字首查詢速度極快。但是FST只能用於字首查詢,這也是Completion Suggester的侷限所在。 為了使用Completion Suggester,欄位的型別需要專門定義如下:
PUT /blogs_completion/
{
"mappings": {
"tech": {
"properties": {
"body": {
"type": "completion"
}
}
}
}
}用bulk API索引點資料:
POST _bulk/?refresh=true
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "Lucene is cool"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "Elasticsearch builds on top of lucene"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "Elasticsearch rocks"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "Elastic is the company behind ELK stack"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "the elk stack rocks"}
{ "index" : { "_index" : "blogs_completion", "_type" : "tech" } }
{ "body": "elasticsearch is rock solid"}查詢:
POST blogs_completion/_search?pretty
{ "size": 0,
"suggest": {
"blog-suggest": {
"prefix": "elastic i",
"completion": {
"field": "body"
}
}
}
}結果:
"suggest": {
"blog-suggest": [
{
"text": "elastic i",
"offset": 0,
"length": 9,
"options": [
{
"text": "Elastic is the company behind ELK stack",
"_index": "blogs_completion",
"_type": "tech",
"_id": "AVrXFyn-cpYmMpGqDdcd",
"_score": 1,
"_source": {
"body": "Elastic is the company behind ELK stack"
}
}
]
}
]
}值得注意的一點是Completion Suggester在索引原始資料的時候也要經過analyze階段,取決於選用的analyzer不同,某些詞可能會被轉換,某些詞可能被去除,這些會影響FST編碼結果,也會影響查詢匹配的效果。 比如我們刪除上面的索引,重新設定索引的mapping,將analyzer更改為"english":
PUT /blogs_completion/
{
"mappings": {
"tech": {
"properties": {
"body": {
"type": "completion",
"analyzer": "english"
}
}
}
}
}bulk api索引同樣的資料後,執行下面的查詢:
POST blogs_completion/_search?pretty
{ "size": 0,
"suggest": {
"blog-suggest": {
"prefix": "elastic i",
"completion": {
"field": "body"
}
}
}
}居然沒有匹配結果了,多麼費解! 原來我們用的english analyzer會剝離掉stop word,而is就是其中一個,被剝離掉了! 用analyze api測試一下:
POST _analyze?analyzer=english
{
"text": "elasticsearch is rock solid"
}
會發現只有3個token:
{
"tokens": [
{
"token": "elasticsearch",
"start_offset": 0,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "rock",
"start_offset": 17,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "solid",
"start_offset": 22,
"end_offset": 27,
"type": "<ALPHANUM>",
"position": 3
}
]
}FST只編碼了這3個token,並且預設的還會記錄他們在文件中的位置和分隔符。 使用者輸入"elastic i"進行查詢的時候,輸入被分解成"elastic"和"i",FST沒有編碼這個“i” , 匹配失敗。 好吧,如果你現在還足夠清醒的話,試一下搜尋"elastic is",會發現又有結果,why? 因為這次輸入的text經過english analyzer的時候is也被剝離了,只需在FST裡查詢"elastic"這個字首,自然就可以匹配到了。 其他能影響completion suggester結果的,還有諸如"preserve_separators","preserve_position_increments"等等mapping引數來控制匹配的模糊程度。以及搜尋時可以選用Fuzzy Queries,使得上面例子裡的"elastic i"在使用english analyzer的情況下依然可以匹配到結果。
preserve_separators 如果為true,foof將找不到foo Full,只能用foo找到,因為他不能忽略停頓符號 如果為false,foof能找到foo Full,因為忽略了停頓符,當然foo F也能匹配到foo Full
size
返回數量
skip_duplicates
去重(預設為false) 因此用好Completion Sugester並不是一件容易的事,實際應用開發過程中,需要根據資料特性和業務需要,靈活搭配analyzer和mapping引數,反覆除錯才可能獲得理想的補全效果。 回到篇首Google搜尋框的補全/糾錯功能,如果用ES怎麼實現呢?我能想到的一個的實現方式:
- 在使用者剛開始輸入的過程中,使用Completion Suggester進行關鍵詞字首匹配,剛開始匹配項會比較多,隨著使用者輸入字元增多,匹配項越來越少。如果使用者輸入比較精準,可能Completion Suggester的結果已經夠好,使用者已經可以看到理想的備選項了。
- 如果Completion Suggester已經到了零匹配,那麼可以猜測是否使用者有輸入錯誤,這時候可以嘗試一下Phrase Suggester。
- 如果Phrase Suggester沒有找到任何option,開始嘗試term Suggester。
精準程度上(Precision)看: Completion > Phrase > term, 而召回率上(Recall)則反之。從效能上看,Completion Suggester是最快的,如果能滿足業務需求,只用Completion Suggester做字首匹配是最理想的。 Phrase和Term由於是做倒排索引的搜尋,相比較而言效能應該要低不少,應儘量控制suggester用到的索引的資料量,最理想的狀況是經過一定時間預熱後,索引可以全量map到記憶體。
原創地址:http://elasticsearch.cn/article/142