
Internet路由之路由表查詢演算法概述-雜湊/LC-Trie樹/256-way-mtrie樹
1.基本概念
路由的概念:路由是一種指向標,因為網路是一跳一跳往前推進的,因此在每一跳都要有一系列的指向標。實際上不僅僅是分組交換網需要路由,電路交換網在建立虛電路的時候也需要路由,更實際的例子,我們日常生活中,路由無處不在。簡單的說,路由由三元素組成:目標地址,掩碼,下一跳。注意,路由項中其實沒有輸出埠-它是鏈路層概念,Linux作業系統將路由表和轉發表混為一談,而實際上它們應該是分開的(分開的好處之一使得MPLS更容易實現)。 路由項通過兩種途徑加入核心,一種是通過使用者態路由協議程序或者使用者靜態配置配置加入,另一種是主機自動發現的路由。所謂自動發現的路由實際上是“發現了一個路由項和一個轉發表”,其含義在主機某一個網絡卡啟動的時候生效,比如eth0啟動,那麼系統生成下列路由表項/轉發項:往eth0同一IP網段的包通過eth0發出。路由表:2.Linux的雜湊查詢演算法
這是Linux作業系統的經典的路由查詢演算法,直到現在還是預設的路由查詢演算法。然而它很簡單。由於它的簡單性,核心(kernel)開發組一直很推崇它,雖然它有這樣那樣的侷限性,但由於Linux核心的哲學就是“夠用即可”,因為Linux幾乎從來不被用於專業的核心網路路由系統,因此雜湊查詢法一直都是預設的選擇。2.1.查詢過程
查詢結構如下圖所示:
查詢順序如下圖所示:
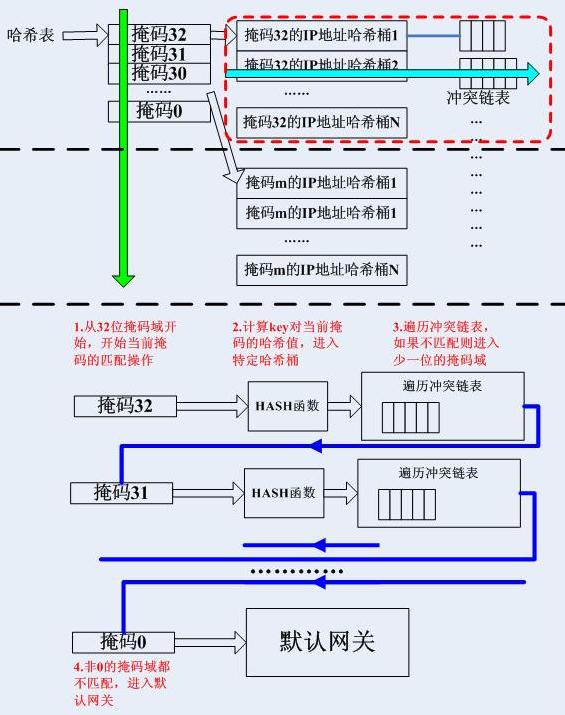
為了實現最長字首匹配,從最長的掩碼開始匹配,每一個掩碼都有一個雜湊表,目的IP地址雜湊到這些雜湊表的特定的桶中,然後遍歷其衝突連結串列得到最終結果。
注意,雜湊查詢演算法是基於掩碼的遍歷來實現嚴格的最長字首匹配的,也就是說如果一條最終將要通過預設閘道器發出的資料報,它起碼要匹配32次才能得到結果。這種方式十分類似於傳統的Netfilter的filter表的過濾方式-一個一個嘗試匹配,而不像HiPac的過濾方式,是基於查詢的。接下來我們會看到,高效能的路由器在查詢路由的時候使用的都是基於查詢型資料結構的方式,最常用的就是查詢樹了。2.2.侷限性
我們知道,雜湊演算法的可擴充套件性一直都是一個問題,一個特定的雜湊函式只適合一定數量的匹配項,幾乎很難找到一個通用的雜湊函式,能夠適應從幾個匹配項到幾千萬個匹配項的情形,一般而言,隨著匹配項的增加,雜湊碰撞也會隨著增加,並且其時間複雜性不可控,這是一個很大的問題,這個問題阻止了雜湊路由查詢演算法走向核心專用路由器,限制了Linux路由的規模,它根本不可能使用雜湊來應對大型網際網路絡或者BGP之類的域間路由協議產生的大量路由資訊。 核心路由器上,使用雜湊演算法無疑是不妥的,必定需要找到一種演算法,使得其查詢的時間複雜度限制在一個範圍(我們不關心空間複雜度,這和端到端使用者的體驗沒有關係,只和他們花的錢多少有關,花10萬買的路由器有4G記憶體,花100萬買的路由器則支援64G記憶體...)。我們知道,基於樹的查詢演算法可以做到這一點,實際上,很多的路由器都是使用基於樹的查詢演算法來實現的。我們先從Linux的trie樹開始。便於查閱程式碼(雖然本文不分析程式碼...)。3.Linux的LC-Trie樹查詢演算法
trie演算法分為三大塊,第一塊是查詢,第二塊是插入/刪除,第三塊是平衡。我們首先先不管其名稱為何這麼叫,也不必非要去深入理解一下Trie樹的概念,直接實踐就是了。雖然很多的教科書都喜歡最後講查詢型資料結構的插入,而我這裡卻要先說插入,因為一旦你明白了插入,查詢就不言自明瞭,另外,講完插入之後,接下來我要說的是trie樹的平衡以及多路操作,因為這樣的話,最終的查詢才會變得高效。我們權當高效的查詢操作是一個必然結果吧。3.1.基本理論
很不好意思,這裡沒什麼理論,一切都很簡單。我們可以通過電話號碼來認識trie樹,trie樹本質上是一棵檢索樹,和全球電話號碼簿一樣,我們知道,電話號碼有三部分組成:國家碼+地區號+號碼,比如086+372+5912345,如果從美國撥出這個號碼,首先要決定送往哪個國家,所要做的就是用確定位數的國家碼和出口交換機的轉發表的國家碼部分進行匹配,發現086正好是中國,然後該號碼到達中國後,再匹配區號,發現要送往安陽市,最後到達安陽市,然後將請求發往5912345這個號碼。 現在的問題是,在每一個環節如何使用最快的方式檢索到請求下一步要發往哪裡?我想最好的方式就是使用“桶演算法”,舉個例子,在美國的電話請求出口處放置一張表,表項有X個,其中X代表全球所有國家和地區的總和,中國的國家碼是086,那麼它就是第86個表項,這樣直接取第86個表項,得到相應的交換資訊,電話請求通過資訊中指示的鏈路發往中國... 另外一個例子就是計算機的頁表,這個我們在3.3節再談。 trie樹,其實和上述的結構差不多,只不過上述結構的檢索分段是固定的,比如電話號碼就是3位10進位制數字等,且匹配檢測索引的位置也是固定的,比如電話號碼的地區號就是從第4位十進位制數字開始等。對於trie樹而言,需要檢測的位置不是固定的,它用pos表示,而檢測索引的長度也不固定,它由bits表示,我們把每一個檢測點定為一個CheckNode,它的結構體如下:CheckNode{ int pos; int bits; Node children[1<<bits];}union Node{ Leaf entry; CheckNode node;}圖解如下: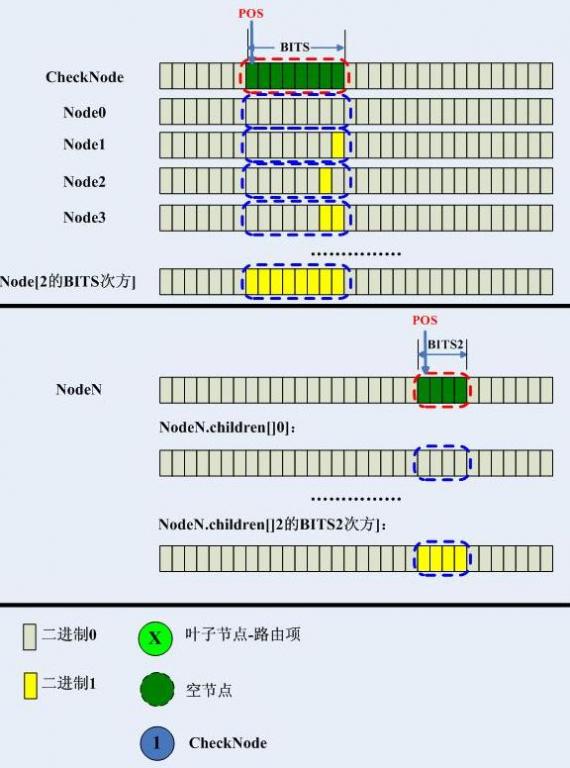
可見pos和bits是一個CheckNode的核心,pos指示從哪一位開始檢測,bits指示了孩子結點陣列,直接取key[pos...pos+bits]即可直接取到孩子結點。
3.2.trie樹的插入
我以為,研究一種樹型結構的時候,首先理解其插入演算法無疑是最好的,然而很多的教科書都是從檢索開始,然後將插入操作一筆帶過,這是很不妥的。我認為只要把插入操作理解深刻了,接下來的查詢和刪除就很簡單了,畢竟插入是第一步!插入雖然重要,但是想學習的人不要認為它很難,要知道,只要是人想出的東西,理解它們都不會很難,難的是什麼?難的是你不會首先想不出來!插入應該怎麼進行呢?:第一步,如果一個CheckNode節點都沒有,則建立根CheckNode節點,並且建立一個葉子,結束。注意,每一個路由項都是一片葉子。如果已經有了根CheckNode,則需要計算新節點插入的位置。第二步,計算插入位置前的位置匹配。步驟如下:根據已有CheckNode的pos/bits資訊,從根開始執行一系列比較:1).取出根CheckNode2).設當前CheckNode為PreCheckNode3).判斷是否需要繼續匹配。4).如果需要繼續匹配,則看看自己是其哪個孩子或者該孩子的分支,並且取出該孩子Child-CheckNode為當前CheckNode,回到2。5).如果不需要繼續匹配,退出匹配過程其中判斷CheckNode是否需要繼續匹配其Child-CheckNode的演算法如下:
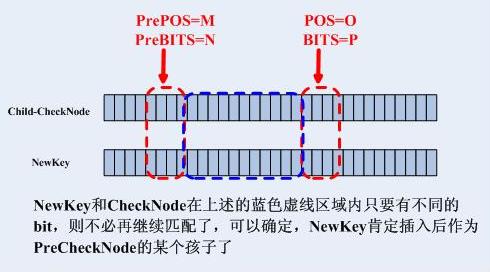
NewKey和CheckNode在上述的藍色虛線區域內只要有不同的bit,則不必再和Child-CheckNode繼續匹配了,可以確定,NewKey肯定插入後作為PreCheckNode的某個孩子了。如果需要繼續匹配,判斷是哪個孩子的方式如下:
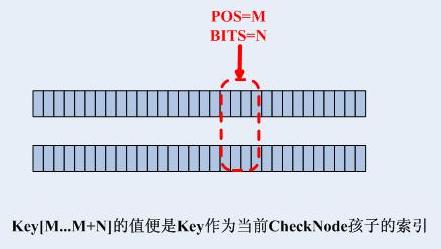
第三步,確定插入位置並且插入,步驟如下:
0).如果沒有發生第二步中的和Child-CheckNode不匹配的情形,則直接將NewKey作為葉子作為PreCheckNode的第NewKey[PreCheckNode的pos...PreCheckNode的pos+PreCheckNode的bits]插入,結束。否則執行下面的步驟,處理和Child-CheckNode的衝突1).建立一個CheckNode,然後看下圖:
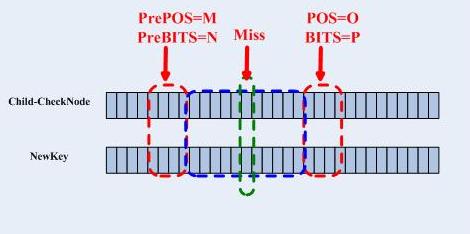
假設上圖中的綠色圈起來的位是Child-CheckNode和NewKey首次不匹配的地方,記為miss,那麼NewKey將建立一個新的CheckNode,記為NewNode,其POS為miss,其bits為1,這樣原來的Child-CheckNode就成了NewNode的一個孩子,而待插入的NewKey建立一個新的葉子,作為NewNode的另一個孩子。NewNode代替Child-CheckNode作為PreCheckNode的孩子插入其孩子陣列中。
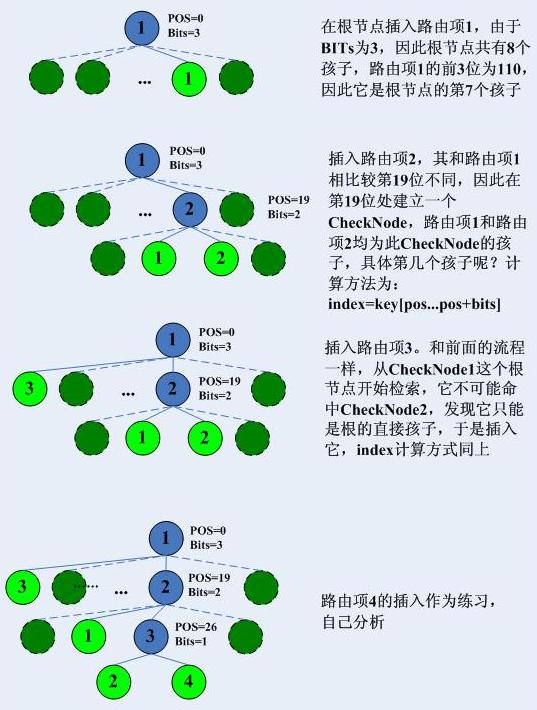
第四步,完畢基本上,上述的過程已經很清楚了,然而給出一個例子會更好些,接下來我給出一個例子,依次插入3條路由項:1:192.168.10.0/242:192.168.20.0/243:2.232.20.0/24然後我們看圖說話,首先看一下位元圖:
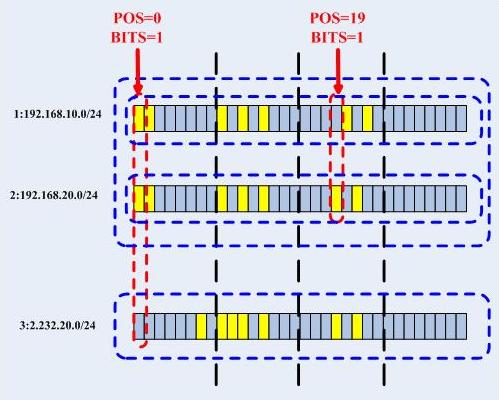
接下來看一下插入trie的情形:

3.3.trie平衡以及多路trie
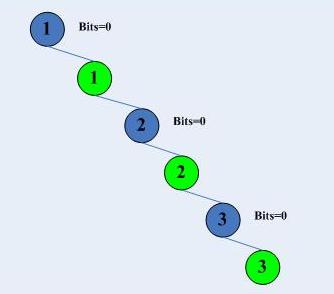
如果僅僅看3.2節所論述的內容,我們發現trie不過是一棵二叉查詢樹而已,這又有何好說的呢?然而作為路由表結構的trie卻遠不止這麼簡單。如果我們現在還想不到作為路由表的trie樹長什麼樣子,我們可以先考慮一下頁表,畢竟這是實現虛擬記憶體的關鍵,處理器設計者一定會選擇一種相當高效的方式來從虛擬地址查詢實體地址的,頁表使用分段索引的方式來快速定位頁表項,也就是說將一個虛擬地址分為N段,每一段定位一個索引,然而將這些索引層接起來就是最終的頁表項。這裡就不再給出圖示了,關於頁表的資料很多。 如果把頁表結構從頁目錄展開來看的話,頁表結構就是一棵大分叉的樹,足有4096叉,然而卻不高,也就兩層到四層。我們想一下它為何如此高效,因為它比較矮小,索引可以快速定位樹的分支,最終快速到達葉子。 但是,且慢,樹矮小的代價是什麼?時間複雜度小了,空間複雜度一般都會變大。它太耗記憶體了。因此最好的方案就是,樹不能太高,也不能太矮。多路的trie樹就是這樣設計的。極端情況下,多路trie樹會退化成一個連結串列或者進化成一棵“2的32次方”叉的只有兩層的樹:連結串列情形-bits=0
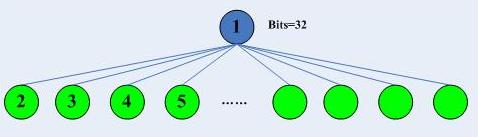
多叉樹情形-bits=32

再看一下多路trie樹:
這就是多路trie樹。
所謂的平衡操作很簡單,每次插入新的節點都會平衡這棵樹,原則如下:1).如果太高了,那麼就壓胖它。使該CheckNode的pos不變,bits加1,使得其孩子的容量增大一倍,然後依次將其孩子重新加入新的CheckNode,加入過程中遞迴執行平衡操作。2).如果太胖了,那就拉高它。使該CheckNode的pos不變,bits減1,使得其孩子的容量減少一倍,然後依次將其孩子重新加入新的CHeckNode,加入過程中遞迴執行平衡操作。 總之,Linux實現的trie樹是動態變化的,這種動態變化的優點是可以根據系統當前的負載以及記憶體情況動態對trie樹的形態做出調整,使得資源的總體利用率提高,然而也有缺點,那就是演算法本身太複雜,不適合做擴充套件,最重要的是不適合用硬體實現。3.4.trie樹的查詢
終於到查詢操作了。在我們理解了上述的插入和平衡操作之後,查詢就變得很簡單了,我們不但可以看得出其簡單-好的演算法一般都簡單,並且由於平衡操作演算法還來得很高效,唯一的新東西就是回溯,不過這一節我們只介紹一般回溯,下一節介紹關於回溯的優化。查詢其實非常簡單,簡單的讓我都不想寫演算法流程了,我家小小又鬧了,加上又喝點酒...來個例子吧,比如來了一個數據包,目的地址是192.168.10.23,來看一下怎麼查詢,將該地址寫成二進位制:
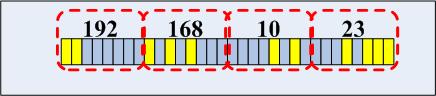
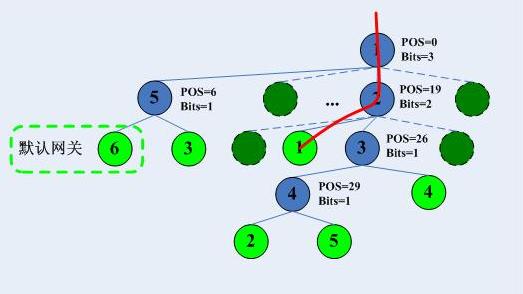
根據trie樹根,得知pos=0/bits=3,因此知道應該去往根CheckNode的第7個孩子,於是到達CheckNode2,類似的,我們檢查該ip地址的第19位後面的兩位,到達葉子節點1,由於其掩碼為24,通過,順利找到,在描述樹查詢過程前,我先將新增預設閘道器的位元圖給出:
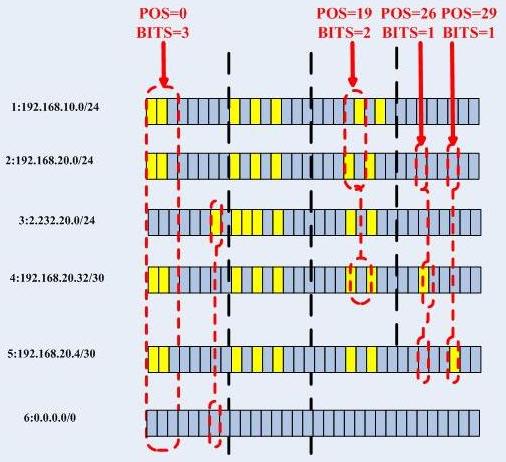
然後給出trie樹:
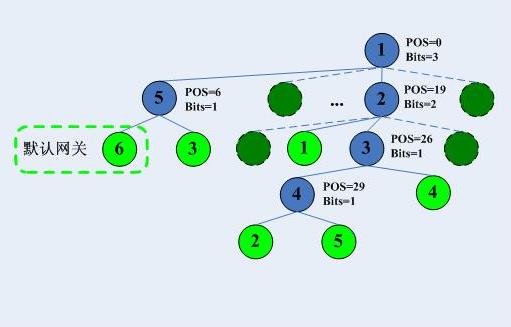
整個trie查詢過程為,紅線標示查詢過程:
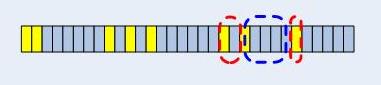
比如來了一個目的地址是192.169.20.32,按照上面的方式,將跳過第16位的不同,最終達到的葉子節點是4,然而最終的整體檢查失敗,進入最長字首匹配,也就是回溯,首先回溯到哪呢?當然是CheckNode3,然後下一步呢?在介紹下一步之前,我們看看回溯的原則。最長字首匹配中,0是很重要的,只要某個匹配項除了後面的0,前面都匹配,那就算成功匹配,我們需要做的是找到“最長”的匹配。哪個是最長的匹配呢?我們可以通過一個演算法得到結果,這也是Linux核心中所使用的演算法:
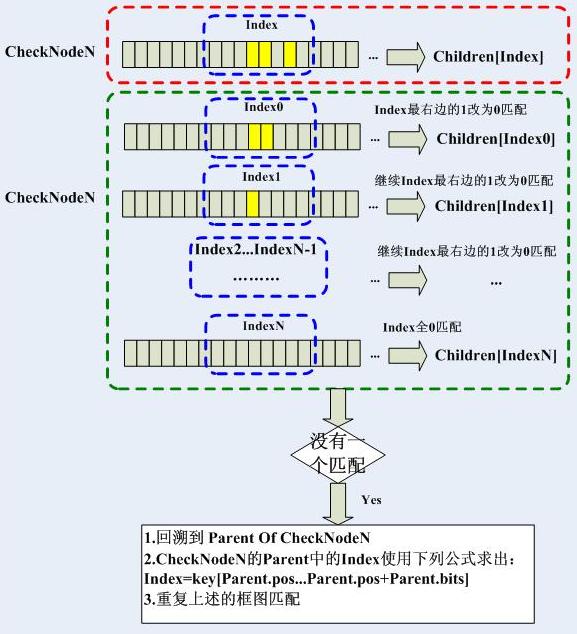
這樣的結果,我們看一下整個過程:
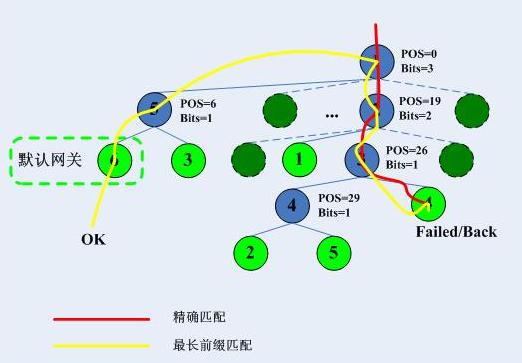
3.5.回溯優化
回溯是很低效的,比如上面的例子,整個繞了兩圈,如果能提前發現那個不匹配的位,那就不用耗費那麼多的無用功了,實際上做到這一點很簡單,那就是在取下一個孩子的時候,判斷一下:在當前CheckNode的[pos+bits]和欲往的孩子節點的[pos+bits]之間有不同的位元嗎?如果有,看看CheckNode中不同的那位以後是否全0,如果是,則直接檢測該CheckNode的掩碼連結串列,否則直接回溯,這樣就不必做無用功了。這種“忽略的不匹配”現象如下所示:
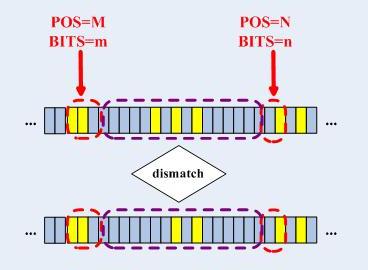
檢查到了這種情況之後,匹配過程馬上進入“最長字首匹配”,將掩碼從32位(精確匹配)減少到和當前CheckNode的key[pos+bits]個孩子的第一個不匹配的位指示的那個位置:
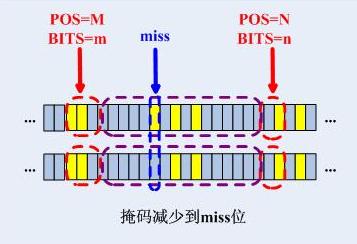
檢索鍵和匹配項相差別的那一位,不是0就是1,只有在匹配項的那位是0(檢索鍵的那位是1)的時候,檢索才能繼續下去,否則,回溯!繼續檢索之後,按照常規的匹配來匹配,區別就是掩碼不同,精確匹配時是32位掩碼匹配,而最長掩碼匹配是N位掩碼匹配。
3.6.動態多路trie樹的本質-路徑壓縮
由於多路trie樹的目的快速從根節點找到一個葉子節點,然後匹配,如果不匹配的話就回溯,因此表示路由表的trie樹就應該能快速一條唯一的從根到葉子的路徑,因此樹的高度不便太高,因此沒有必要對查詢鍵每一個位元位都進行檢測,trie樹中的CheckNode中的pos以及bits決定了在哪個地方檢測已經檢測多少位,而trie樹此時是已經建好的,可以把當前已插入路由項之外的位元資訊檢測全部忽略掉,這就是路徑壓縮,見下圖:
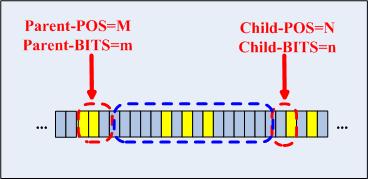
檢索鍵的藍顏色圈起來的位在精確匹配過程中暫時不需要進行匹配,等到最長字首匹配時再考慮。路徑壓縮的好處在於匹配時計算的次數會減少,然而隨著更多的路由項的插入,很多的節點將會使下列的等式成立:
node.pos=Pnode.pos+Pnode.bits(Pnode為node的Parent)如果一個CheckNode有太多這樣的孩子,說明進入此分支的匹配全部都要“走很長的路”了,那麼為了使匹配操作“路途更短”,該進行一次平衡操作了,所要做的就是將高樹壓低壓胖。4.BSD/Cisco的Radix查詢演算法
4.1.基本理論
很多時候,還是這個名稱造成了極大的困惑,radix樹?基樹?二叉樹?...停吧!4.2.radix查詢
複雜的多路trie樹查詢我們都已經會了,這個還難嗎?可能唯一的區別就是BSD的樹相對於Linux的而言比較固定,因此更易於用硬體來並行實現,華為的VRP因此也受益良多!舉個例子來說明這一點,如果我們將IP地址分為相等的4個部分,每一部分就是8個位,那麼就很容易將4個索引並行處理,即使不併行處理,使用硬體交叉網路來實現也是蠻快的,可以看到,這和頁面的查詢非常類似了,只是頁表查詢失敗會引發缺頁異常,而路由查詢失敗將回溯。還是那個問題,回溯到哪裡?基本演算法和trie樹一樣,也是依賴每一個CheckNode都存在一個掩碼連結串列...5.BSD/Cisco的X叉樹查詢演算法
5.1.基本理論和查詢
用空間換時間,這是一種不太瘋狂且很正當的舉動,因為時間相比空間要重要的多,人們對時間的敏感性也比對空間的敏感性更高,空間廣義的說可以是無限的,而時間卻存在一個個的閥值。另外,並行也是空間換時間的一個直接益處,我們知道並行是一個時間上的概念。 Linux的trie樹的回溯優化版本中,發現不匹配就回溯,回溯的過程中包含了一個一個嘗試的步驟,無非就是從右到左依次將1變成0後再次嘗試字首匹配,這種方式固然可行,然而如果能直接指出下個匹配哪個節點,那就不需要回溯過程中的嘗試行為了。而這正是Cisco的實現,傳說中的256叉樹就是用固定的4個8位一組來定位索引的,和頁表項查詢一樣,一旦出現不匹配的或者索引對應的孩子為NULL的,直接根據節點結構中指示的“下一個節點”來直接到達下一個節點處繼續匹配。位元結構見下圖: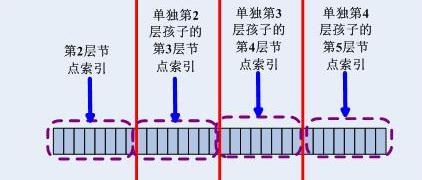
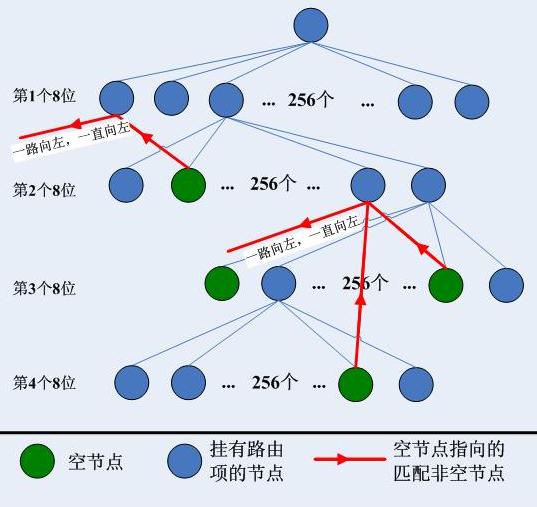
5.2.評價
256叉樹的查詢結構是一個一般性的路由表結構,實際上Cisco路由器的CEF的實現是上述256叉樹的某種優化-CEF使用的資料結構是一個256-way-mtrie,它本質上也是分為4層,和上述的沒有什麼兩樣,只是不再存在空節點,也沒有了紅色粗線表示的靜態回溯路徑,而是直接把那條紅線最終指向的節點的資訊直接寫入到那個空節點中。看起來如下這個樣子: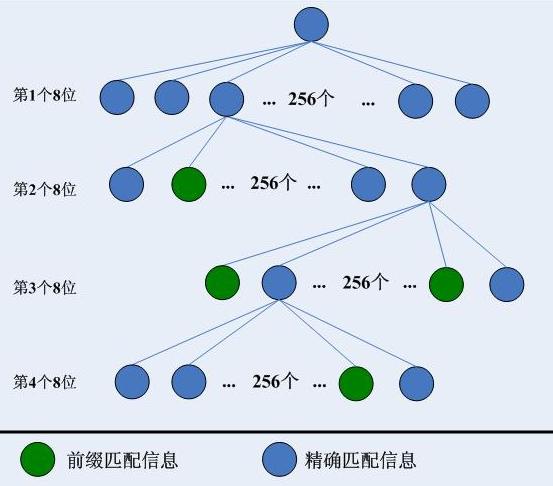
6.總的評價
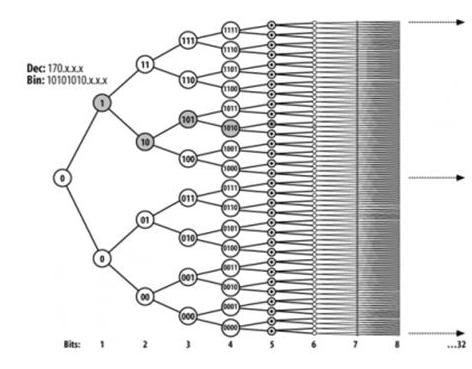
總的評價不談雜湊演算法,因為雜湊函式的可擴充套件性很差,我本身也不是很喜歡這個東西,雖然Linux核心中大量使用了雜湊,但是正是這些雜湊限制了Linux支援應用的規模,尋找好的雜湊函式簡直太難了,如果這會兒你的西牆倒了,並且你此時並不在乎東牆,那麼你就用雜湊吧,拆了東牆補西牆! 樹演算法是不錯的選擇,確定性強,而且越是簡單的樹實際上效率越高,這是為什麼呢?因為易於用硬體實現,專業級的硬體還是要比單純使用cpu的軟體效率高几個級別的。是設計高效複雜的純軟體演算法還是用硬體實現一個簡單然而並不怎麼高效的演算法,這是一個問題。基本上可以確定,一般而言,純硬體實現的遍歷要比純軟體實現的雜湊好很多,硬體是訊號,電流驅動的,而軟體依賴cpu指令,時鐘週期等...本文基本就介紹了路由查詢使用的兩種樹,第一種是二叉樹,如下圖(圖片來自google的結果):
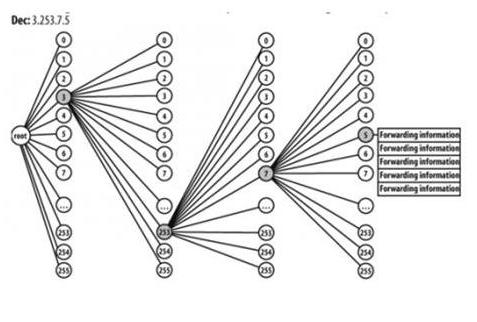
第二種是256叉樹,如下圖(圖片來自google的結果):
 另外一種樹,多路動態的trie樹,實際上是介於退化成連結串列的二叉樹和2的32次方叉樹之間的一種樹。
另外一種樹,多路動態的trie樹,實際上是介於退化成連結串列的二叉樹和2的32次方叉樹之間的一種樹。