
五分鐘零基礎搞懂Hadoop
資料學習社
welcome
「大資料」,想必大家經常聽到這個被炒得很熱的話題。隨之而來的是各種看似高大上的專業術語,比如「擴充套件性」、「可靠性」、「容錯性」,好像真的很高深,要積累多年經驗才能學習。
很多同學都剛剛進入網際網路這個行業,對分散式計算還沒有很多瞭解,那是不是就要花很多力氣才能搞懂「大資料」呢?用淺顯易懂深入淺出的語言,幫助沒有基礎的同學快速的入手「大資料」,讓每位同學都能迅速學會最前沿的技術。今天,我們先學習當前使用最廣泛的大資料處理框架 Hadoop.

我自己是一名大資料架構師,每天都會直播分享免費公開課,大家可以加群參加。以及我自己整理了一套最新的大資料學習系統教程,包括Hadoop,資料探勘,資料分析。送給正在學習大資料的小夥伴!這裡是大資料學習者聚集地,歡迎初學和進階中的小夥伴!
加QQ群:684290783(招募中)
Hadoop,是怎麼來的?
今天的社會產生越來越多的資料,比如:你登入Facebook以後點選了哪些好友,你在Amazon上瀏覽了哪些產品,你在linkedin上瀏覽了哪些公司,甚至到從石油礦井裡的鑽頭收集了哪些地質資訊。
我們還發現,通過分析這些資料總結規律,我們可以讓Facebook和Amazon顯示讓使用者更感興趣的廣告,公司HR會更準確找到合適的求職者,石油公司也能用更低的成本開採更多的石油。
那找個軟工寫演算法不就行了嗎?
確實,這些決策都是通過演算法找到規律的。可問題是現在的資料量太大了,一臺機器要完成一個問題要算好久好久。
那用多臺機器處理不就行了嗎?
Hadoop以及其他任何大資料框架都是多臺機器共同處理的。可問題是,這些演算法都要完成一個特定的問題,給出一個答案,多臺機器不能自己算自己的,他們要有不同的分工,聯合起來共同算完這個問題。這裡就是Hadoop等框架的特長。
我們舉個例子吧:
Google是大家常用的搜尋引擎,作為業務的重要特徵,它自然想知道大家對哪些關鍵字感興趣,比如以天為單位,收集所有人搜過的關鍵字,統計其出現的次數。
這聽起來像個雜湊表就能幹的問題對吧?可是,每天那麼多人使用Google,它不可能把這些關鍵字都放在記憶體裡,而且Google也是用很多伺服器為大家完成搜尋的,所以一天裡所有搜過的關鍵字,都以檔案的形式存在多臺機器上。我們就叫這些機器1, 2, 3......n.
比如在機器1上儲存了一個檔案,內容是所有搜過的關鍵字:Deer, Bear, River …...
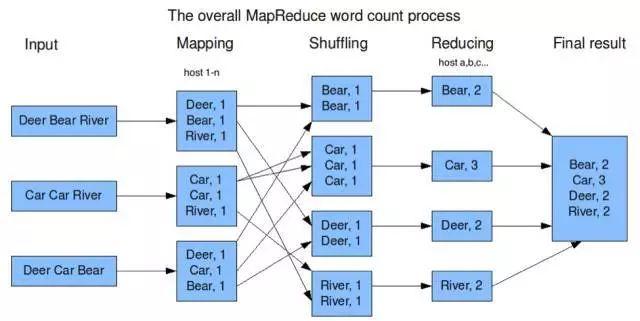
既然Log檔案存放在多臺機器中,那如何計算關鍵字出現的總次數呢?
一種直觀的演算法,就是先讓每臺機器統計本機上每個關鍵字的搜尋次數,寫段演算法統計一個檔案裡的關鍵字很簡單。比如機器1的處理結果為:
Deer 150000
River 110000
Car 100000
…
(參見圖1的mapping)
注意到這裡,每臺機器知道的是本機上關鍵字的搜尋次數,而我們關心的是所有機器上的關鍵字的搜尋總次數。
那下一步再找一組機器,不妨稱其為:A, B, C, D......
每臺機器只統計一部分關鍵字出現在所有機器上的總次數,比如:
讓機器A統計 在機器1, 2, 3.......n上“Bear”出現的總次數;
讓機器B統計,在機器1, 2, 3.......n上“Car”出現的總次數;
讓機器C統計,在機器1, 2, 3.......n上“Deer”出現的總次數;
讓機器D統計,在機器1, 2, 3......n上“River”出現的總次數;
(參見圖1的reducing)
這樣,當A, B, C, D......完成自己的任務以後,我們就知道每個關鍵字在過去一天出現的次數了。
所以每臺機器不但要計算自己的任務,還要和其他機器「合作」,在我們剛才的例子裡就是機器A, B, C, D......要從機器1, 2, 3, 4......那裡知道關鍵字的出現次數,而且,A, B, C, D.....還要溝通好,分別統計不同的關鍵字,即不能兩臺機器都統計同一個關鍵字,也不能有的關鍵字沒有機器統計。
好吧,大資料計算真複雜,那我們什麼時候說說Hadoop?
其實,如果你明白了剛才的例子,你就明白Hadoop了!
我們剛才計算搜尋引擎關鍵字出現次數的例子,就是一個使用Hadoop的經典案例。
像我們剛才說的,大資料計算非常複雜,各個機器之間要協調工作。但是,當總結常用的大資料演算法後,我們發現他們有一定的共同點(稍後介紹),很多演算法都要做一些類似的工作。
既然有共同點,我們就沒有必要重造輪子。這些類似的工作可以做成Framework,以後再開發類似大資料分析軟體可以重用這些Framework的功能。Hadoop就是這樣一個Framework,它來源於Google一篇關於MapReduce的Paper.
那Hadoop總結了演算法的哪些共同點呢?
那篇MapReduce Paper的作者發現,很多計算,就比如我們剛才的例子,都可以拆分成Map, Shuffle, Reduce三個階段:
Map階段中,每臺機器先處理本機上的資料,像圖1中各個機器計算本機的檔案中關鍵字的個數。
各個機器處理完自己的資料後,我們再把他們的結果彙總,這就是Shuffle階段,像剛才的例子,機器A, B, C, D......從1-n所有機器上取出Map的結果,並按關鍵字組合。
最後,進行最後一步處理,這就是Reduce,我們剛才的例子中就是對每一個搜尋關鍵字統計出現總次數。
這幾步我們就稱為MapReduce Model.
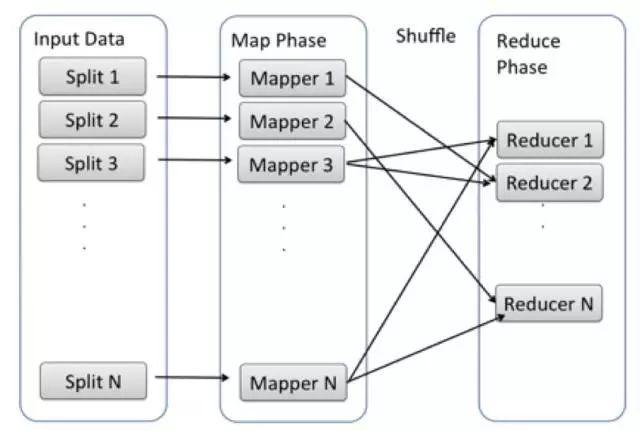
為了完成MapReduce Model的計算,實際開發的軟體需要一些輔助的功能。想像一下,起始時的一組機器上面儲存了要處理的資料,但是Map, Shuffle, Reduce階段的Function在哪兒呢?所以我們需要把Mapper Function, Reducer Function (Java code或者其他語言的code) 安裝在機器 1-n 和A-Z上,並且執行。
而且在Map階段以後,計算結果儲存在本機上,沒辦法Shuffle到Reduce的機器上。所以,也需要有軟體按照Shuffle演算法,把Mapper Function的結果搬運到Reduce階段的機器上。
執行整個Hadoop Job的流程中,很多工作對於所有演算法都是需要的,不同的演算法只是Mapper Function和Reducer Function. 換句話說,
Hadoop實現了通用的功能,開發人員只需要告訴Hadoop需要執行的Mapper, Reducer Function,就可以完成想要的計算,而不需要開發所有步驟。