
撩課-Mysql第20部分索引
阿新 • • 發佈:2018-12-19
學習地址:
撩課-JavaWeb系列1之基礎語法-前端基礎
撩課-JavaWeb系列2之XML
撩課-JavaWeb系列3之MySQL
撩課-JavaWeb系列4之JDBC
撩課-JavaWeb系列5之web伺服器-idea
什麼是索引
索引用於快速找出
在某個列中有一特定值的行,
不使用索引,
MySQL必須從第一條記錄開始
讀完整個表,
直到找出相關的行,
表越大,
查詢資料所花費的時間就越多,
如果表中查詢的列有一個索引,
MySQL能夠快速到達一個位置
去搜索資料檔案,
而不必檢視所有資料,
那麼將會節省很大一部分時間

索引的優勢與劣勢
優勢
類似大學圖書館建書目索引, 提高資料檢索效率, 降低資料庫的IO成本。 通過索引對資料進行排序, 降低資料排序的成本,降低了CPU的消耗。
劣勢
實際上索引也是一張表,
該表儲存了主鍵與索引欄位,
並指向實體表的記錄,
所以索引列也是要佔空間的。
雖然索引大大提高了查詢速度,
同時確會降低更新表的速度,
如對錶進行INSERT、UPDATE、DELETE。

索引的分類
單值索引
即一個索引只包含單個列,
一個表可以有多個單列索引。
唯一索引
索引列的值必須唯一,
但允許有空值。
複合索引
一個索引包含多個列。
INDEX MultiIdx(id,name,age)
全文索引
只有在MyISAM引擎上才能使用,
只能在CHAR,VARCHAR,
TEXT型別欄位上使用全文索引

索引操作
建立索引
CREATE INDEX 索引名稱 ON table (column[, column]...);create INDEX salary_index ON emp(salary)刪除索引
DROP INDEX 索引名稱 ON 表名
檢視索引
show index from 表名; Table 表名 Non_unique 如果索引不能包括重複詞,則為0。如果可以,則為1。 Key_name 索引的名稱 Seq_in_index 索引中的列序列號,從1開始。 Column_name 列名稱。 Collation 列以什麼方式儲存在索引中。 在MySQL中,有值‘A'(升序)或NULL(無分類)。 Cardinality 索引中唯一值的數目的估計值。 過執行ANALYZE TABLE或myisamchk -a可以更新。 基數根據被儲存為整數的統計資料來計數, 所以即使對於小型表, 該值也沒有必要是精確的。 基數越大,當進行聯合時, MySQL使用該索引的機會就越大。 Sub_part 如果列只是被部分地編入索引,則為被編入索引的字元的數目。如果整列被編入索引,則為NULL。 Packed 指示關鍵字如何被壓縮。 如果沒有被壓縮,則為NULL。 Null 如果列含有NULL,則含有YES。如果沒有,則該列含有NO。 Index_type 用過的索引方法(BTREE, FULLTEXT, HASH, RTREE)。 Comment 索引備註資訊
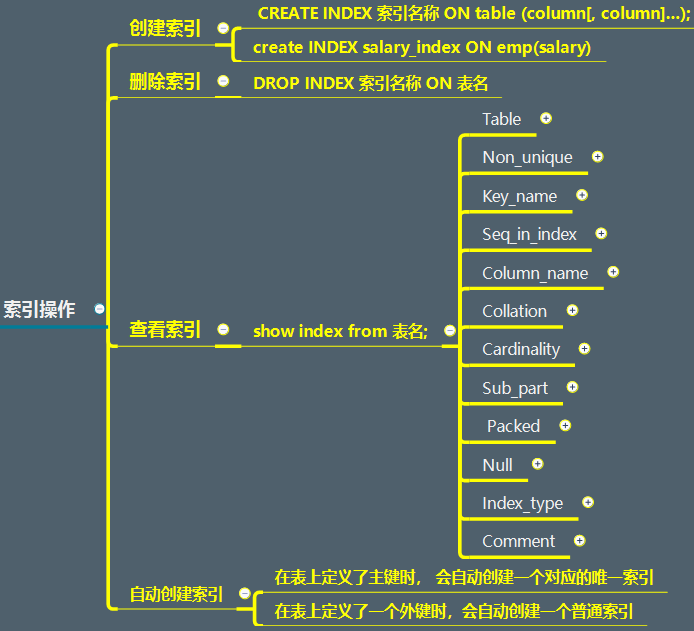
自動建立索引
在表上定義了主鍵時,
會自動建立一個對應的唯一索引
在表上定義了一個外來鍵時,
會自動建立一個普通索引
**EXPLAIN **
用來檢視索引是否正在被使用,並且輸出其使用的索引的資訊。
id:
SELECT識別符。
這是SELECT的查詢序列號,也就是一條語句中,
該select是第幾次出現。
在次語句中,
select就只有一個,所以是1.
select_type:
所使用的SELECT查詢型別,
SIMPLE表示為簡單的SELECT,
不實用UNION或子查詢,
就為簡單的SELECT。
table:
資料表的名字。
他們按被讀取的先後順序排列
type:
指定本資料表和其他資料表之間的關聯關係,
該表中所有符合檢索值的記錄都會被取出來和
從上一個表中取出來的記錄作聯合。
key:
實際選用的索引
possible_keys:
MySQL在搜尋資料記錄時可以選用的各個索引,
該表中就只有一個索引,year_publication
key_len:
顯示了mysql使用索引的長度(也就是使用的索引個數),
當 key 欄位的值為 null時,索引的長度就是 null。
注意,key_len的值可以告訴你
在聯合索引中mysql會真正
使用了哪些索引。
這裡就使用了1個索引,所以為1,
ref:
給出關聯關係中另一個數據表中資料列的名字。
常量(const),這裡使用的是1990,就是常量。
rows:
MySQL在執行這個查詢時
預計會從這個資料表裡讀出的資料行的個數。
extra:
提供了與關聯操作有關的資訊,
沒有則什麼都不寫。
索引結構
先會對資料進行排序
btree索引
B+樹索引
B+樹是一個平衡的多叉樹,
從根節點到每個葉子節點的高度差值不超過1
而且同層級的節點間有指標相互連結。
hash索引
雜湊索引就是採用一定的雜湊演算法,
把鍵值換算成新的雜湊值,
檢索時不需要類似B+樹那樣從根節點到葉子節點逐級查詢,
只需一次雜湊演算法即可立刻定位到相應的位置,速度非常快。
hash 索引結構的特殊性,
其檢索效率非常高,
索引的檢索可以一次定位,
不像B-Tree 索引需要從根節點到枝節點,
最後才能訪問到頁節點這樣多次的IO訪問,
所以 Hash 索引的查詢效率要遠高於 B-Tree 索引。
哪些情況需要建立索引
主鍵自動建立唯一索引
頻繁作為查詢條件的欄位應該建立索引
查詢中與其他表關聯的欄位,
外來鍵關係建立索引
頻繁更新的欄位不適合建立索引,
因為每次更新不單單是
更新了記錄還會更新索引
WHERE條件裡用不到的欄位不建立索引
查詢中排序的欄位,
排序的欄位若通過索引
去訪問將大大提高排序速度
查詢中統計或者分組欄位
哪些情況不需要建立索引
表記錄太少
經常增刪改的表
如果某個資料列包含許多重複的內容
為它建立索引就沒有太大的實際效果
如果你想要獲取Xmind思維導圖源件加群:869866610,進群可以獲取以上技術的學習視訊。