
selenium在scrapy中的應用
阿新 • • 發佈:2018-12-19
引入
在通過scrapy框架進行某些網站資料爬取的時候,往往會碰到頁面動態資料載入的情況發生,如果直接使用scrapy對其url發請求,是絕對獲取不到那部分動態加載出來的資料值。但是通過觀察我們會發現,通過瀏覽器進行url請求傳送則會加載出對應的動態加載出的資料。那麼如果我們想要在scrapy也獲取動態加載出的資料,則必須使用selenium建立瀏覽器物件,然後通過該瀏覽器物件進行請求傳送,獲取動態載入的資料值。
1.案例分析:
- 需求:爬取網易新聞的國內板塊下的新聞資料
- 需求分析:當點選國內超鏈進入國內對應的頁面時,會發現當前頁面展示的新聞資料是被動態加載出來的,如果直接通過程式對url進行請求,是獲取不到動態加載出的新聞資料的。則就需要我們使用selenium例項化一個瀏覽器物件,在該物件中進行url的請求,獲取動態載入的新聞資料。
2.selenium在scrapy中使用的原理分析:
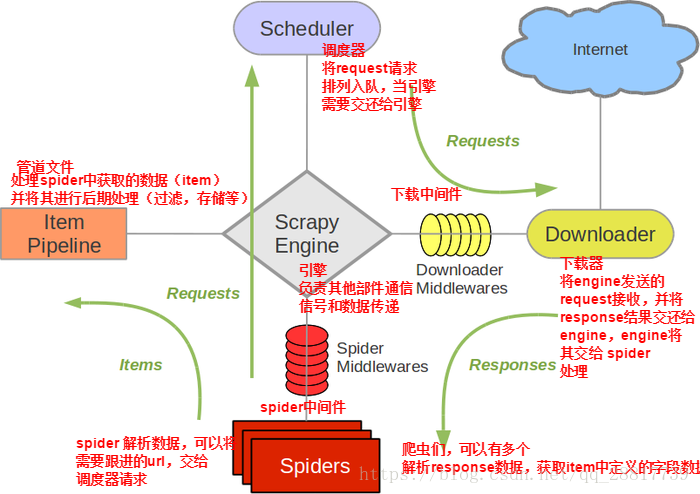
當引擎將國內板塊url對應的請求提交給下載器後,下載器進行網頁資料的下載,然後將下載到的頁面資料,封裝到response中,提交給引擎,引擎將response在轉交給Spiders。Spiders接受到的response物件中儲存的頁面資料裡是沒有動態載入的新聞資料的。要想獲取動態載入的新聞資料,則需要在下載中介軟體中對下載器提交給引擎的response響應物件進行攔截,切對其內部儲存的頁面資料進行篡改,修改成攜帶了動態加載出的新聞資料,然後將被篡改的response物件最終交給Spiders進行解析操作。
3.selenium在scrapy中的使用流程:
- 重寫爬蟲檔案的構造方法,在該方法中使用selenium例項化一個瀏覽器物件(因為瀏覽器物件只需要被例項化一次)
- 重寫爬蟲檔案的closed(self,spider)方法,在其內部關閉瀏覽器物件。該方法是在爬蟲結束時被呼叫
- 重寫下載中介軟體的process_response方法,讓該方法對響應物件進行攔截,並篡改response中儲存的頁面資料
- 在配置檔案中開啟下載中介軟體
4.程式碼展示:
- 爬蟲檔案:
class WangyiSpider(RedisSpider):
name = 'wangyi'
#allowed_domains = ['www.xxxx.com']
start_urls = ['https://news.163.com']
def __init__(self):
#例項化一個瀏覽器物件(例項化一次)
self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver')
#必須在整個爬蟲結束後,關閉瀏覽器
def closed(self,spider):
print('爬蟲結束')
self.bro.quit()
- 中介軟體檔案:
from scrapy.http import HtmlResponse
#引數介紹:
#攔截到響應物件(下載器傳遞給Spider的響應物件)
#request:響應物件對應的請求物件
#response:攔截到的響應物件
#spider:爬蟲檔案中對應的爬蟲類的例項
def process_response(self, request, response, spider):
#響應物件中儲存頁面資料的篡改
if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(2) #一定要給與瀏覽器一定的緩衝載入資料的時間
#頁面資料就是包含了動態加載出來的新聞資料對應的頁面資料
page_text = spider.bro.page_source
#篡改響應物件
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
else:
return response
- 配置檔案:
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}