
leetcode | 87. Scramble String
題目
Given a string s1, we may represent it as a binary tree by partitioning it to two non-empty substrings recursively.
Below is one possible representation of s1 = “great”:
great
/ \
gr eat
/ \ / \
g r e at
/ \
a t
To scramble the string, we may choose any non-leaf node and swap its two children.
For example, if we choose the node “gr” and swap its two children, it produces a scrambled string “rgeat”.
rgeat
/ \
rg eat
/ \ / \
r g e at
/ \
a t
We say that “rgeat” is a scrambled string of “great”.
Similarly, if we continue to swap the children of nodes “eat” and “at”, it produces a scrambled string “rgtae”.
rgtae
/ \
rg tae
/ \ / \
r g ta e
/ \
t a
We say that “rgtae” is a scrambled string of “great”.
Given two strings s1 and s2 of the same length, determine if s2 is a scrambled string of s1.
Example 1:
Input: s1 = "great", s2 = "rgeat"
Output: true
Example 2:
Input: s1 = 思路與解法
這道題目讓我們判斷是否存在從s1轉化為s2的一種可行方法。題目保證輸入資料滿足s1、s2長度相等。
乍一看,感覺是將s1所有組成字元進行重新排列組合然後將獲得的字串與s2作比較。但是實際上這道題目加了隱藏的“限制”。因為Example 2中abcde不能轉化為caebd。
下面,簡單解釋一下,為什麼abcde不能轉化為caebd:由題目可知,我們可以將s1分為兩個字串,然後這兩個字串可以交換順序,也可以不交換從而生成新的s1;同樣,我們可以對兩個字串進行相同的操作。
由此可知,我們從s1進行轉化所能得到的字串是有限的,必須是由上述操作得到的。這是一個十分明顯的遞迴結構,所以我們可以採用遞迴的方法來判斷s1是否可以轉化為s2。
如果s1可以轉化為s2,那麼一定滿足以下兩個條件之一:
- 不交換子串:s1和s2的前i個字元分別組成的子串可以相互轉化,並且s1和s2的後len(s1)-i個字元分別組成的子串可以相互轉化;
- 交換子串:s1的前i個字元組成的子串和s2後i個字元組成的子串可以相互轉化,並且s1的後len(s1)-i個字元組成的子串和s2後len(s2)-i個字元組成的可以相互轉化。
if isScramble(s1[0:i],s2[0:i]) && isScramble(s1[i:], s2[i:])
return true
if isScramble(s1[:i], s2[len(s2)-i:]) && isScramble(s1[i:], s2[:len(s2)-i])
return true
程式碼實現
此演算法我使用go語言實現:
func isScramble(s1 string, s2 string) bool {
// 如果s1==s2直接返回true
if s1 == s2 {
return true
}
// 判斷s1和s2中是否存在不相同的字元,避免後續遞迴的消耗
s1Slice := strings.Split(s1, "")
s2Slice := strings.Split(s2, "")
sort.Strings(s1Slice)
sort.Strings(s2Slice)
if strings.Join(s1Slice, "") != strings.Join(s2Slice, "") {
return false
}
// 遞迴過程,對應於分析過程中的兩種情況
for i:=1; i<len(s1);i++ {
if (isScramble(s1[:i], s2[:i]) && isScramble(s1[i:], s2[i:])) || (isScramble(s1[:i], s2[len(s2)-i:]) && isScramble(s1[i:], s2[:len(s2)-i])) {
return true
}
}
return false
}
遇到的問題
最初並沒有判斷s1和s2中是否存在不相同的字元,結果造成了無用的遞迴,消耗了大量的時間,造成了超時:
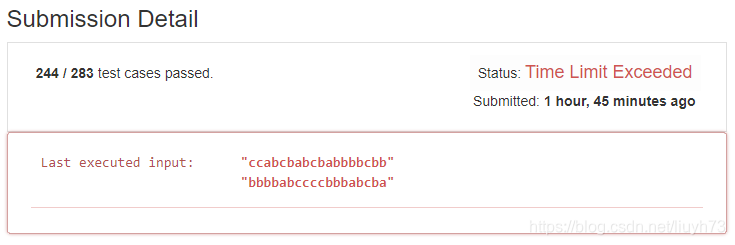 加入判斷之後程式才可以通過,不過排序的時間複雜度為,所以我們採用下面複雜度的判斷方法:
加入判斷之後程式才可以通過,不過排序的時間複雜度為,所以我們採用下面複雜度的判斷方法:
alphabet := make([]int,26)
for i:=0;i<len(s1);i++ {
alphabet[s1[i]-'a']+=1
alphabet[s2[i]-'a']-=1
}
for i:=0;i<26;i++ {
if alphabet[i] != 0 {return false}
}
return true