
A Simple Web Server
介紹
在過去20幾年裡,網路已經在各個方面改變了我們的生活,但是它的核心卻幾乎沒有什麼改變。多數的系統依然遵循著Tim Berners-Lee在上個世紀釋出的規則。大多數的web伺服器都在用同樣的方式處理訊息
背景
多數在web上的伺服器都是執行在IP協議標準上。在這協議家族裡面我們關心的成員就是TCP,這個協議使得計算機之間的通訊看起來像是在讀寫檔案。
專案通過套接字來使用IP通訊。每個套接字都是一個點對點的通訊通道,一個套接字包含IP地址,埠來標識具體的機器。IP地址包含4個8Bit的數字,比如174.136.14.108;DNS將這些數字匹配到更加容易識別的名字比如aosabook.org
HTTP是一種可以在IP之上傳輸資料的方式。HTTP非常簡單:客戶端在套接字連線上傳送一個請求指示需要什麼樣的資訊,然後服務端就傳送響應。資料可以是從硬碟上的檔案拷貝過來,程式動態生成,或者是兩者結合

HTTP請求中最重要的就是文字:任何專案都可以創造或者解析一個文字。為了便於理解,文字有圖中所示的部分
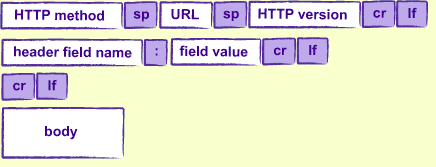
HTTP方法一般採用”GET”(/research/experiments.html,但是這一切都取決於伺服器端如何去做。HTTP版本一般是"HTTP/1.0"或者"HTTP/1.1";我們並不關心這兩者的差別。
HTTP的頭是像下面的成對鍵值:
Accept: text/htmlAccept-Language: en, frIf-Modified-Since: 16-May-2005
和雜湊表中的鍵值不一樣的是,鍵值在HTTP頭中可以出現任意的次數。這就使得請求可以去指定它願意接受的幾種型別。
最後,請求的主體是與請求相關聯的任何額外資料。這些將被用在通過表單提交資料,上傳檔案等等。
在最後一個標頭和主體的開始之間必須有空白行以表示標頭的結束。
一個被稱為Content-length的頭,用來告訴在請求資料中期望讀取多數個位元組。
HTTP響應也和HTTP請求是一樣的格式
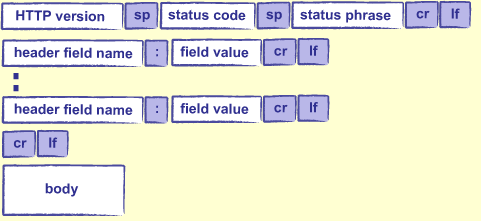
版本,頭資訊和主體都是同樣的格式。狀態碼是一個數字用來指示請求處理時發生了什麼:200意味著正常工作,404意味著沒有找到,其他的碼也有不同的意思。
對於這章節,我們只需要知道HTTP的其他兩件事。
第一個就是無狀態:每個請求都處理自己的,並且伺服器端。伺服器不會記住當前請求和下一個請求之間的內容。如果應用想跟蹤比如使用者身份的資訊,就必須自己處理。
通常採用的方法是用cookie,cookie是伺服器傳送給客戶端的字元流,然後客戶端返回給伺服器。當一個使用者需要實現在不同請求之間保持狀態的時候,伺服器會建立cookie,儲存在資料庫裡,然後傳送給瀏覽器。每次瀏覽器把cookie值傳送回來的時候,伺服器都會用來去查詢資訊來知道使用者在幹什麼。
第二個我們需要了解關於HTTP的就是URL可以通過提供引數來提供更多的資訊。比如,如果我們在使用搜索引擎,我們必須指定搜尋術語。我們可以加入到URL的路徑中,但是我們一般都是加入到URL的引數中。我們在URL中增加?,後面跟隨key=value並且用&符號分割來達到這個目的。比如URLhttp://www.google.ca?q=Python就告訴Google去搜索Python相關的網頁。鍵值是字母q,值是Python。更長的查詢http://www.google.ca/search?q=Python&client=Firefox告訴Google我們正在使用Firefox等等。我們可以傳輸任何我們需要的引數。但是使用哪一個,如何解釋這些引數取決於應用。
當然,如果?和&特殊的字元,那麼必須有一種方法去規避,正如必須有一種方法將雙引號字元放入由雙引號分隔的字串中一樣。URL的編碼標準用%後面跟2個位元組碼的方式來表示特殊字元,用+來代替空格。所以為了在Google上搜索”grade=A+”,我們可以使用的URL為http://www.google.ca/search?q=grade+%3D+A%2B
建立sockets,構建HTTP請求,解析響應是非常枯燥的事情。所以人們更多是使用庫函式來完成大部分的工作。Python附帶了一個urllib2的庫,但是它暴露了很多人根本不關心的管道。Request庫是可以替代urllib2並且更加好使用的庫。下面是一個從AOA網站下載網頁的例子。
import requestsresponse = requests.get('http://aosabook.org/en/500L/web-server/testpage.html')print 'status code:', response.status_codeprint 'content length:', response.headers['content-length']print response.textstatus code: 200content length: 61<html><body><p>Test page.</p></body></html>
requests.get傳送一個HTTP GET請求到伺服器然後返回一個包含響應的物件。物件的status_code成員是響應的狀態碼;content_length成員是響應資料的長度,text是真是的資料(在這個例子中,是HTTP網頁)
你好,web
現在我們準備去寫第一個簡單的web伺服器。
1 等待某人連線到伺服器上並且傳送一個請求
2 解析請求
3 指出要求獲取的東西
4 獲取資料(或者動態的產生)
5 將資料格式化為HTML格式
6 傳送回去
1,2,6步對於各種不同的應用來說都是一樣的,Python標準庫有一個模組稱為BaseHTTPServer為我們做完成這些。我們需要完成的是步驟3到步驟5.這一部分只需要很少的工作
import BaseHTTPServerclass RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):'''Handle HTTP requests by returning a fixed 'page'.'''# Page to send back.Page = '''\<html><body><p>Hello, web!</p></body></html>'''# Handle a GET request.def do_GET(self):self.send_response(200)self.send_header("Content-Type", "text/html")self.send_header("Content-Length", str(len(self.Page)))self.end_headers()self.wfile.write(self.Page)if __name__ == '__main__':serverAddress = ('', 8080)server = BaseHTTPServer.HTTPServer(serverAddress, RequestHandler)server.serve_forever()BaseHTTPRequestHandler庫會解析傳入的HTTP請求然後決定裡面包含的方法。如果方法是GET,類就會呼叫do_GET的函式。我們自己的類RequestHandler重寫了這個方法來動態生成網頁:文字text儲存在類級別的引數page,Page將會在傳送了200響應碼後傳送給客戶端,Content-Type頭告訴客戶端用HTML的方式來解析資料以及網頁的長度(end_headers方法在我們的頭和網頁之間插入空白行)但是RequestHandler並不是整個的工程:我們依然需要最後的三行啟動伺服器。第一行用一個元組的方式來定義伺服器的地址:空字元意味著執行在本機上,8080是埠。然後我們用整個地址和RequestHandler作為引數來建立BaseHTTPServer.HTTPServer例項,然後讓程式永遠執行(在實際中,除非用Control-C停止整個程式)如果我們在命令列中執行整個專案,不會顯示任何東西$ python server.py如果我們在瀏覽器中輸入http://localhost:8080,我們會在瀏覽器中得到如下的顯示Hello, web!在shell中將會看到127.0.0.1 - - [24/Feb/2014 10:26:28] "GET / HTTP/1.1" 200 -127.0.0.1 - - [24/Feb/2014 10:26:28] "GET /favicon.ico HTTP/1.1" 200 -第一行是直截了當的:因為我們並沒有要求獲取具體的檔案,瀏覽器要求獲取”/”(伺服器執行的根目錄)。第二行出現是因為瀏覽器自動傳送第二個請求去獲取圖片檔案/favicon.ico,它將在位址列中顯示為圖示。顯示數值讓我們修改下web伺服器使得可以顯示在HTTP請求中的內容(將來在除錯的過程中我們經常會做這件事,所以我們先練習下)為了保持我們的程式碼乾淨,我們將傳送和建立頁面分開class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):# ...page template...def do_GET(self):page = self.create_page()self.send_page(page)def create_page(self):# ...fill in...def send_page(self, page):# ...fill in...send_page的程式碼和之前的一樣def send_page(self, page):self.send_response(200)self.send_header("Content-type", "text/html")self.send_header("Content-Length", str(len(page)))self.end_headers()self.wfile.write(page)想要顯示的網頁模板是一個字串,其中包含了HTML表格以及一些格式化的佔位符Page = '''\<html><body><table><tr> <td>Header</td> <td>Value</td> </tr><tr> <td>Date and time</td> <td>{date_time}</td> </tr><tr> <td>Client host</td> <td>{client_host}</td> </tr><tr> <td>Client port</td> <td>{client_port}s</td> </tr><tr> <td>Command</td> <td>{command}</td> </tr><tr> <td>Path</td> <td>{path}</td> </tr></table></body></html>'''填充的方法如下:def create_page(self):values = {'date_time' : self.date_time_string(),'client_host' : self.client_address[0],'client_port' : self.client_address[1],'command' : self.command,'path' : self.path}page = self.Page.format(**values)return page程式的主體並沒有改變:和之前一樣,建立了一個HTTPServer類例項,其中包含地址和請求,然後伺服器就永遠工作。如果我們開始執行並且從瀏覽器中傳送請求http://localhost:8080/something.html。我們將得到:Date and time Mon, 24 Feb 2014 17:17:12 GMTClient host 127.0.0.1Client port 54548Command GETPath /something.html即使something.html網頁不在網頁上,我們也沒有發現404異常。這是因為伺服器只是一個程式,當收到請求時,它可以做任何它想做的事:傳送回前一個請求中命名的檔案,提供隨機選擇的維基百科頁面,或者我們對它進行程式設計的任何其他內容。 靜態網頁 下一步就是從硬碟上的網頁開始啟動而不是隨機產生一個。我們可以重寫do_GETdef do_GET(self):try:# Figure out what exactly is being requested.full_path = os.getcwd() + self.path# It doesn't exist...if not os.path.exists(full_path):raise ServerException("'{0}' not found".format(self.path))# ...it's a file...elif os.path.isfile(full_path):self.handle_file(full_path)# ...it's something we don't handle.else:raise ServerException("Unknown object '{0}'".format(self.path))# Handle errors.except Exception as msg:self.handle_error(msg)這個函式假設被允許web伺服器正在執行的目錄或者目錄下的任何檔案(通過os.getcwd來獲取)。程式會將URL中包含的路徑和當前的路徑組裝起來(URL中的路徑放在self.path變數中,初始化的時候都是’/’)來得到使用者需要的檔案路徑 如果路徑不存在,或者不是個檔案,函式將會通過產生並捕獲一個異常來報告錯誤。如果路徑和檔案匹配,則會呼叫handle_file函式來讀取並返回內容。這個函式讀取檔案並且使用send_content來發送給客戶端
def handle_file(self, full_path):
try: with open(full_path, 'rb') as reader: content = reader.read() self.send_content(content) except IOError as msg: msg = "'{0}' cannot be read: {1}".format(self.path, msg) self.handle_error(msg)
注意到我們用二進位制的方式來開啟檔案--’rb’中的’b’. 這樣Python就不會幫我們通過過改變看起來像Windows行結尾的位元組序列。並且在執行的時候,將整個的檔案讀進記憶體是個很糟糕的主意。像視訊檔案有可能是好幾個G的大小。但是處理那樣的情況不在本章節的考慮之內。 為了完成這個類,我們還需要寫一個異常處理方法以及錯誤報告的網頁模板Error_Page = """\<html><body><h1>Error accessing {path}</h1><p>{msg}</p></body></html>"""def handle_error(self, msg):content = self.Error_Page.format(path=self.path, msg=msg)self.send_content(content)這個程式可以工作了,但是我們仔細看會發現問題。問題在與總是返回200的狀態碼,即使被請求的的網頁不存在。是的,在這種情況下,傳送回的頁面包含錯誤資訊,但是瀏覽器不能閱讀英文,所以也不知道request是成功還是失敗。為了讓這種情況更清晰,我們需要修改handle_error和send_content。# Handle unknown objects.def handle_error(self, msg):content = self.Error_Page.format(path=self.path, msg=msg)self.send_content(content, 404)# Send actual content.def send_content(self, content, status=200):self.send_response(status)self.send_header("Content-type", "text/html")self.send_header("Content-Length", str(len(content)))self.end_headers()self.wfile.write(content)在一個檔案沒被找到的時候我們沒有丟擲ServerException異常,而是產生了一個錯誤的頁面。ServerException是為了在我們自己搞錯的時候傳送一個內部錯誤的訊號。handle_error建立的異常網頁,只會在使用者發生錯誤的時候發生。比如傳送URL中的檔案並不存在。顯示目錄下一步,我們將教會伺服器當URL是一個目錄而不是檔案的時候顯示路徑的內容。我們還可以走遠一點在路徑中去尋找index.html檔案並顯示出來,並且在檔案不存在的時候顯示路徑的內容。但是在do_GET中建立這些規則將會是個錯誤,因為所得到的方法將是一長串控制特殊行為的if語句。正確的解決方法是退後並解決一般性問題,那就是指出URL將要發生的動作。下面是對do_GET的重寫。def do_GET(self):try:# Figure out what exactly is being requested.self.full_path = os.getcwd() + self.path# Figure out how to handle it.for case in self.Cases:handler = case()if handler.test(self):handler.act(self)break# Handle errors.except Exception as msg:self.handle_error(msg)第一步都是一樣的:指出請求的全路徑。儘管如此,程式碼還是看起來不一樣,不是一堆的內聯測試,這個版本查詢儲存在列表中的事件集合。每個事件物件都有2個方法:test,用來告訴我們是否可以處理這個請求以及act,用來實際執行動作。一旦我們找到了正確的事件,我們就開始處理請求並且跳出迴圈。下面三個物件事件重新塑造了伺服器的行為:class case_no_file(object):'''File or directory does not exist.'''def test(self, handler):return not os.path.exists(handler.full_path)def act(self, handler):raise ServerException("'{0}' not found".format(handler.path))class case_existing_file(object):'''File exists.'''def test(self, handler):return os.path.isfile(handler.full_path)def act(self, handler):handler.handle_file(handler.full_path)class case_always_fail(object):'''Base case if nothing else worked.'''def test(self, handler):return Truedef act(self, handler):raise ServerException("Unknown object '{0}'".format(handler.path))在RequestHandler類的開始的時候,我們將將建立事件處理列表。class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):'''If the requested path maps to a file, that file is served.If anything goes wrong, an error page is constructed.'''Cases = [case_no_file(),case_existing_file(),case_always_fail()]...everything else as before...現在伺服器程式碼變得越來越複雜:程式碼行數從74變成了99,還有一個額外的間接級別且沒有函式。當我們回到本章開始的任務,並試圖教我們的伺服器在index.html頁面上提供一個目錄(如果有的話)以及目錄列表(如果沒有的話)時,就會得到好處。之前的處理如下:class case_directory_index_file(object):'''Serve index.html page for a directory.'''def index_path(self, handler):return os.path.join(handler.full_path, 'index.html')def test(self, handler):return os.path.isdir(handler.full_path) and \os.path.isfile(self.index_path(handler))def act(self, handler):handler.handle_file(self.index_path(handler))index_path方法構建到index.html的路徑;將其放入case處理程式可以防止主RequestHandler中的混亂,測試檢查路徑是否是包含index.html頁面的目錄,act請求主請求程式去為該網頁提供服務。RequestHandler唯一的變化是在Cases列表中新增case_directory_index_file物件。Cases = [case_no_file(),case_existing_file(),case_directory_index_file(),case_always_fail()]如果路徑中不包含index.html網頁?測試和上面的一樣,僅僅是插入了一個not語句,但是act方法如何處理?它應該做什麼class case_directory_no_index_file(object):'''Serve listing for a directory without an index.html page.'''def index_path(self, handler):return os.path.join(handler.full_path, 'index.html')def test(self, handler):return os.path.isdir(handler.full_path) and \not os.path.isfile(self.index_path(handler))def act(self, handler):???看起來像是我們將自己逼入了牆角。從邏輯上來說,act方法應該建立,返回路徑列表,但是我們的程式碼不允許這樣:RequestHandler.do_GET呼叫act,但是並沒有期望去處理和返回值。現在,讓我們在RequestHandler加一個方法去生成路徑列表,然後從事件的處理器act中去呼叫。class case_directory_no_index_file(object):'''Serve listing for a directory without an index.html page.'''# ...index_path and test as above...def act(self, handler):handler.list_dir(handler.full_path)class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):# ...all the other code...# How to display a directory listing.Listing_Page = '''\<html><body><ul>{0}</ul></body></html>'''def list_dir(self, full_path):try:entries = os.listdir(full_path)bullets = ['<li>{0}</li>'.format(e)for e in entries if not e.startswith('.')]page = self.Listing_Page.format('\n'.join(bullets))self.send_content(page)except OSError as msg:msg = "'{0}' cannot be listed: {1}".format(self.path, msg)self.handle_error(msg)CGI協議當然,多數的人都不想去編輯web伺服器的原始碼來增加新的功能。為了不給開發者增加更多的工作量,伺服器總是支援稱為CGI的機制,這為伺服器提供了一種標準的方法去執行外部程式來滿足需求。比如,加入我們想伺服器能夠在HTML網頁上顯示當地時間。我們可以在程式中增加幾行程式碼from datetime import datetimeprint '''\<html><body><p>Generated {0}</p></body></html>'''.format(datetime.now())為了讓伺服器執行程式,我們增加了事件處理器:class case_cgi_file(object):'''Something runnable.'''def test(self, handler):return os.path.isfile(handler.full_path) and \handler.full_path.endswith('.py')def act(self, handler):handler.run_cgi(handler.full_path)測試樣例:這個路徑是否是以.py結尾?如果是,RequestHandler執行這個程式def run_cgi(self, full_path):cmd = "python " + full_pathchild_stdin, child_stdout = os.popen2(cmd)child_stdin.close()data = child_stdout.read()child_stdout.close()self.send_content(data)<