
吳恩達 deep learning 第三週 淺層神經網路
阿新 • • 發佈:2018-12-19
文章目錄
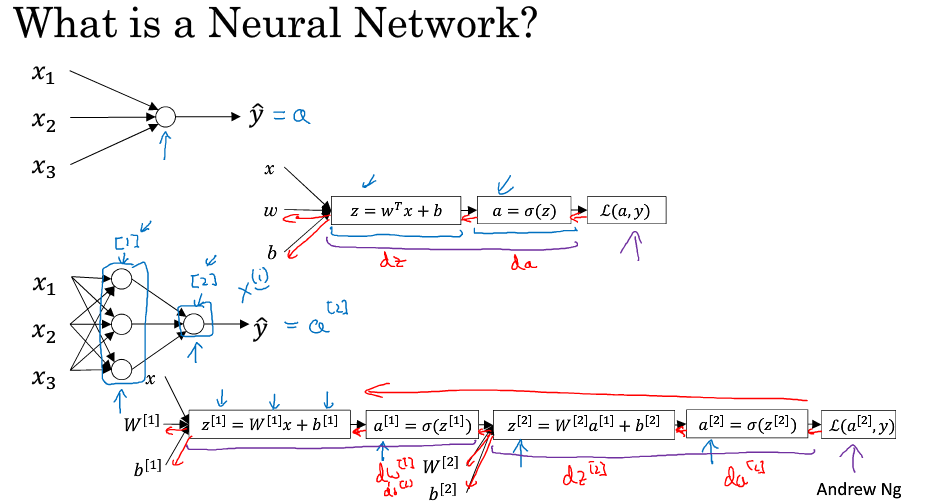
神經網路概覽
[]表示不同的層
表示第i個數據
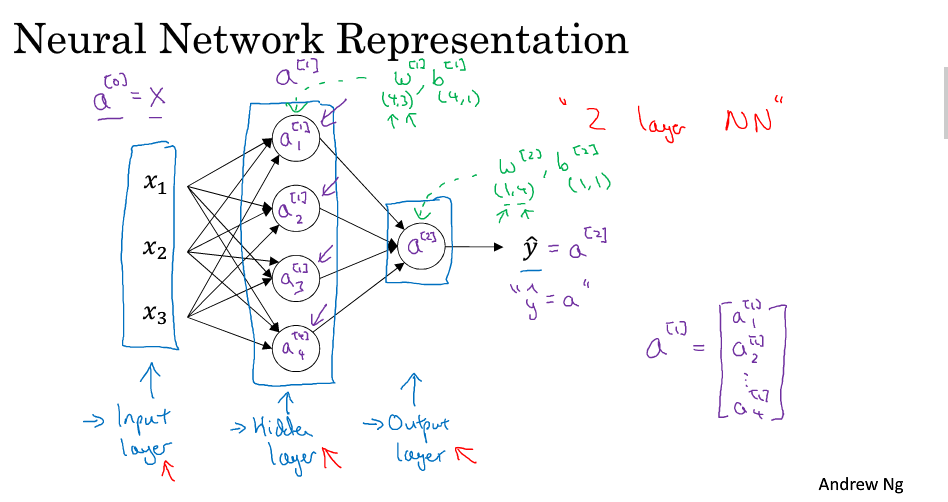
神經網路的表示
簡單的神經網路
表示第i層的啟用值
表示第i層的引數
是4*3的矩陣,4表示4個隱藏單元,3表示3個輸入
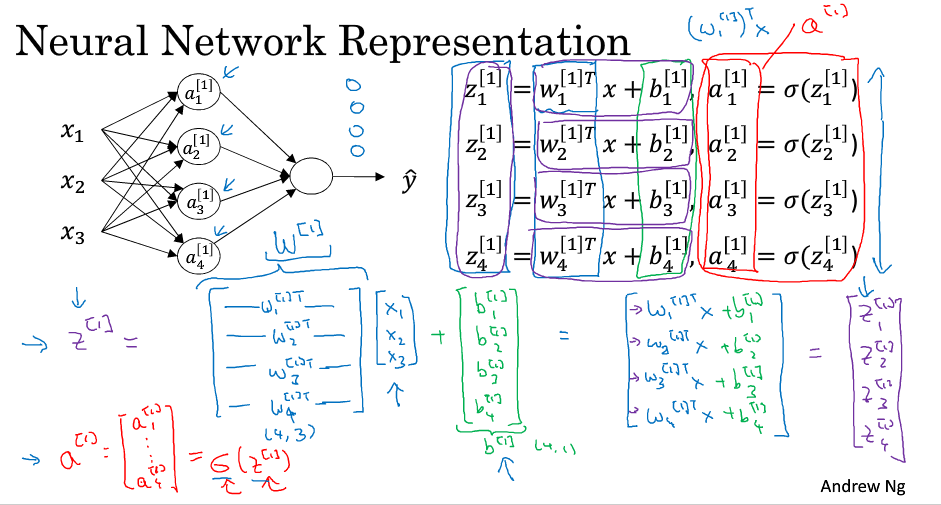
計算神經網路的輸出
神經網路的計算過程
向量化之後的計算過程
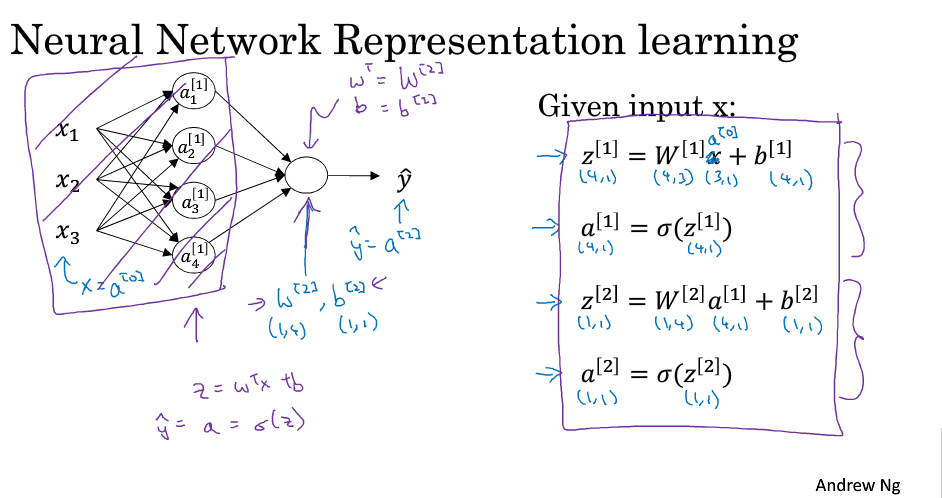
多個例子中的向量化
向量化的實現,通過向量化可以更快的實現神經網路的計算

啟用函式
幾種不同的啟用函式
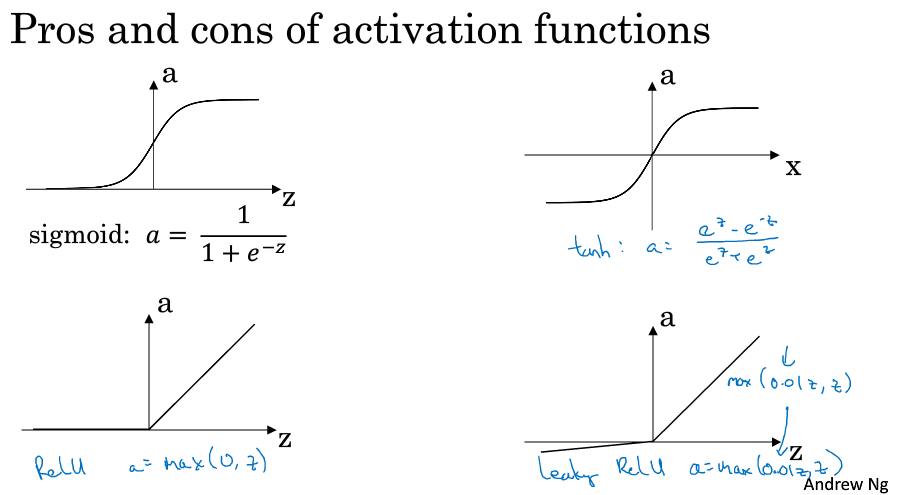
tanh啟用函式幾乎在所有場合由於sigmoid,在做二分類的時候,輸出層使用sigmoid函式
tanh和sigmoid有一個缺點就是如果z很大或者很小,那麼導數的梯度可能就會很小,這就會導致梯度下降很慢
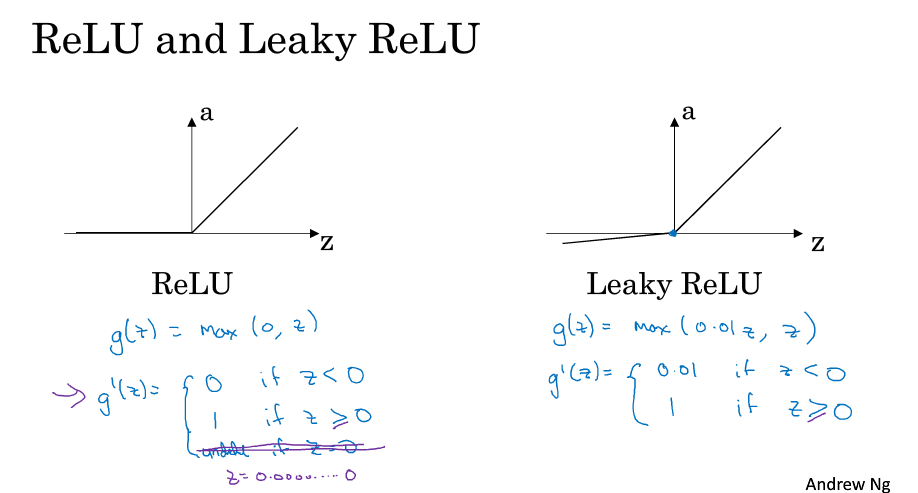
ReLU 修正性單元 缺點是當z為負的時候,導數等於零
Leaky ReLU 解決上述問題 這兩者的優點是啟用函式的斜率和0差得很遠,在實踐中使用ReLU啟用函式,神經網路的訓練會快很多,雖然ReLU有一半的斜率為0,當有足夠多的隱藏單元,令z>0
為什麼需要非線性啟用函式
如果使用線性啟用函式,那麼神經網路只是把輸入線性組合在輸出

啟用函式的導數
Sigmoid函式的導數
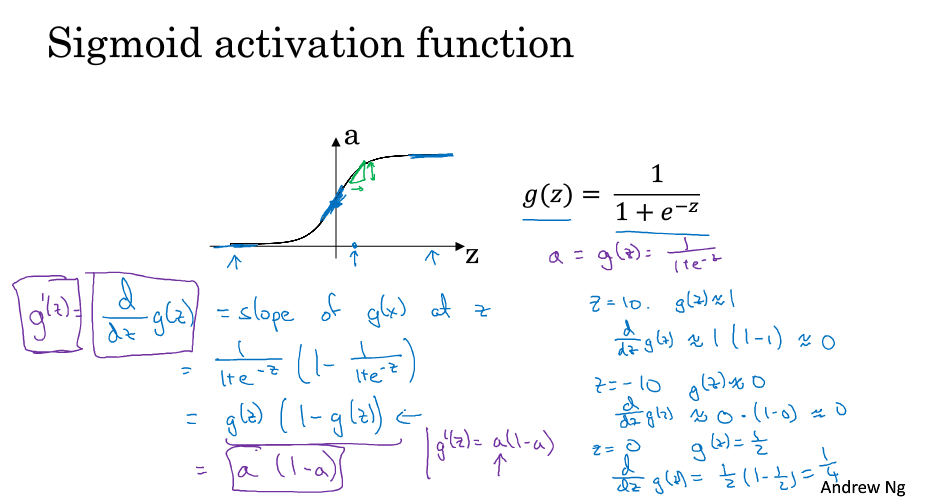
Tanh函式的導數
ReLU和Leaky ReLu導數

神經網路的梯度下降
神經網路梯度下降

正向傳播和反向傳播
keepdims=True 保證輸出的是矩陣


隨機初始化
當隱藏單元的引數設定為0時,通過多次迭代隱藏單元還是對稱的,都在計算完全一樣的函式,這樣多個隱藏單元沒有意義
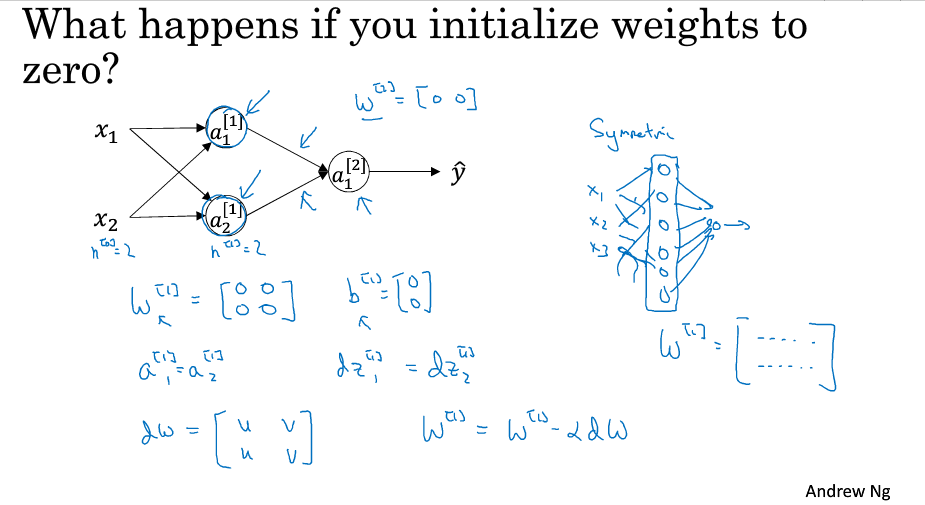
將w*0.01是為了儘可能的是輸出小,使得z的值位於sigmoid和tanh啟用函式的0附近,0附近的梯度較大,可以提高神經網路的速度
