
[原始碼和文件分享]C語言實現huffman編解碼與壓縮文字
阿新 • • 發佈:2018-12-19
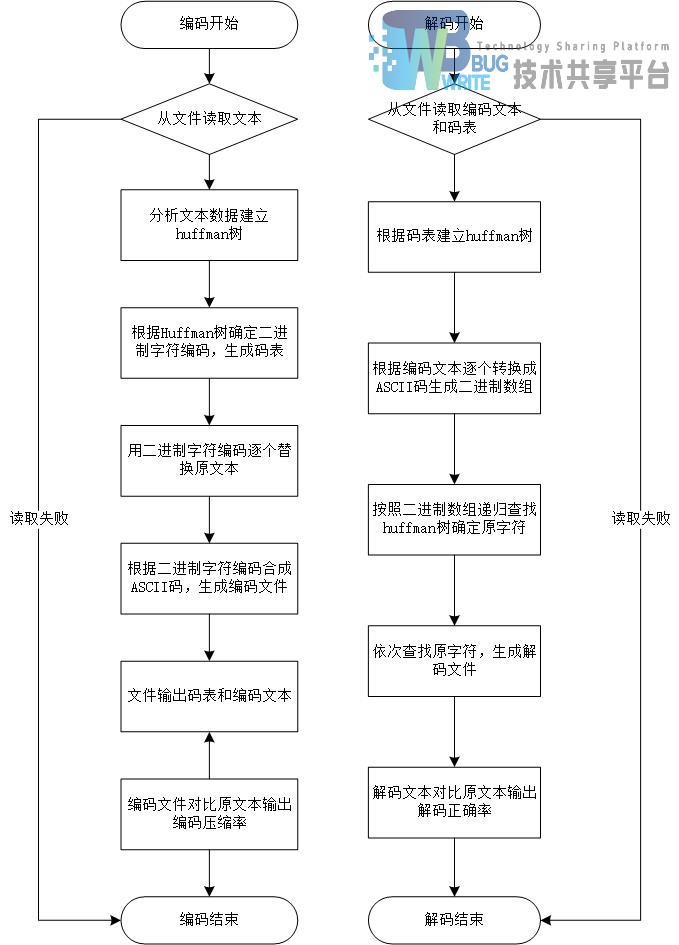
1 原理
哈夫曼編碼(Huffman Coding),又稱霍夫曼編碼,是一種編碼方式,哈夫曼編碼是可變字長編碼(VLC)的一種。Huffman於1952年提出一種編碼方法,該方法完全依據字元出現概率來構造異字頭的平均長度最短的碼字,有時稱之為最佳編碼,一般就叫做Huffman編碼(有時也稱為霍夫曼編碼)。
在計算機資料處理中,霍夫曼編碼使用變長編碼表對源符號(如檔案中的一個字母)進行編碼,其中變長編碼表是通過一種評估來源符號出現機率的方法得到的,出現機率高的字母使用較短的編碼,反之出現機率低的則使用較長的編碼,這便使編碼之後的字串的平均長度、期望值降低,從而達到無失真壓縮資料的目的。
例如,在英文中,e的出現機率最高,而z的出現概率則最低。當利用霍夫曼編碼對一篇英文進行壓縮時,e極有可能用一個位元來表示,而z則可能花去25個位元(不是26)。用普通的表示方法時,每個英文字母均佔用一個位元組(byte),即8個位元。二者相比,e使用了一般編碼的1/8的長度,z則使用了3倍多。倘若我們能實現對於英文中各個字母出現概率的較準確的估算,就可以大幅度提高無失真壓縮的比例。
參考文件和完整的文件和原始碼下載地址:
https://www.write-bug.com/article/1669.html