
linux java 線上問題排查
一、Java 服務常見線上問題
所有 Java 服務的線上問題從系統表象來看歸結起來總共有四方面:CPU、記憶體、磁碟、網路。例如 CPU 使用率峰值突然飈高、記憶體溢位 (洩露)、磁碟滿了、網路流量異常、FullGC 等等問題。
基於這些現象我們可以將線上問題分成兩大類: 系統異常、業務服務異常。
1. 系統異常
常見的系統異常現象包括: CPU 佔用率過高、CPU 上下文切換頻率次數較高、磁碟滿了、磁碟 I/O 過於頻繁、網路流量異常 (連線數過多)、系統可用記憶體長期處於較低值 (導致 oom killer) 等等。
這些問題可以通過 top(cpu)、free(記憶體)、df(磁碟)、dstat(網路流量)、pstack、vmstat、strace(底層系統呼叫) 等工具獲取系統異常現象資料。
此外,如果對系統以及應用進行排查後,均未發現異常現象的更笨原因,那麼也有可能是外部基礎設施如 IAAS 平臺本身引發的問題。
例如運營商網路或者雲服務提供商偶爾可能也會發生一些故障問題,你的引用只有某個區域如廣東使用者訪問系統時發生服務不可用現象,那麼極有可能是這些原因導致的。
今天我司部署在阿里雲華東地域的業務系統中午時分突然不能為廣東地區使用者提供正常服務,對系統進行各種排查均為發現任何問題。
最後,通過查詢阿里雲公告得知原因是 “ 廣東地區電信線路訪問華東地區網際網路資源(包含阿里雲華東 1 地域)出現網路丟包或者延遲增大的異常情況“。
2. 業務服務異常
常見的業務服務異常現象包括: PV 量過高、服務呼叫耗時異常、執行緒死鎖、多執行緒併發問題、頻繁進行 Full GC、異常安全攻擊掃描等。
二、問題定位
我們一般會採用排除法,從外部排查到內部排查的方式來定位線上服務問題。
- 首先我們要排除其他程序 (除主程序之外) 可能引起的故障問題;
- 然後排除業務應用可能引起的故障問題;
- 可以考慮是否為運營商或者雲服務提供商所引起的故障
1.定位流程
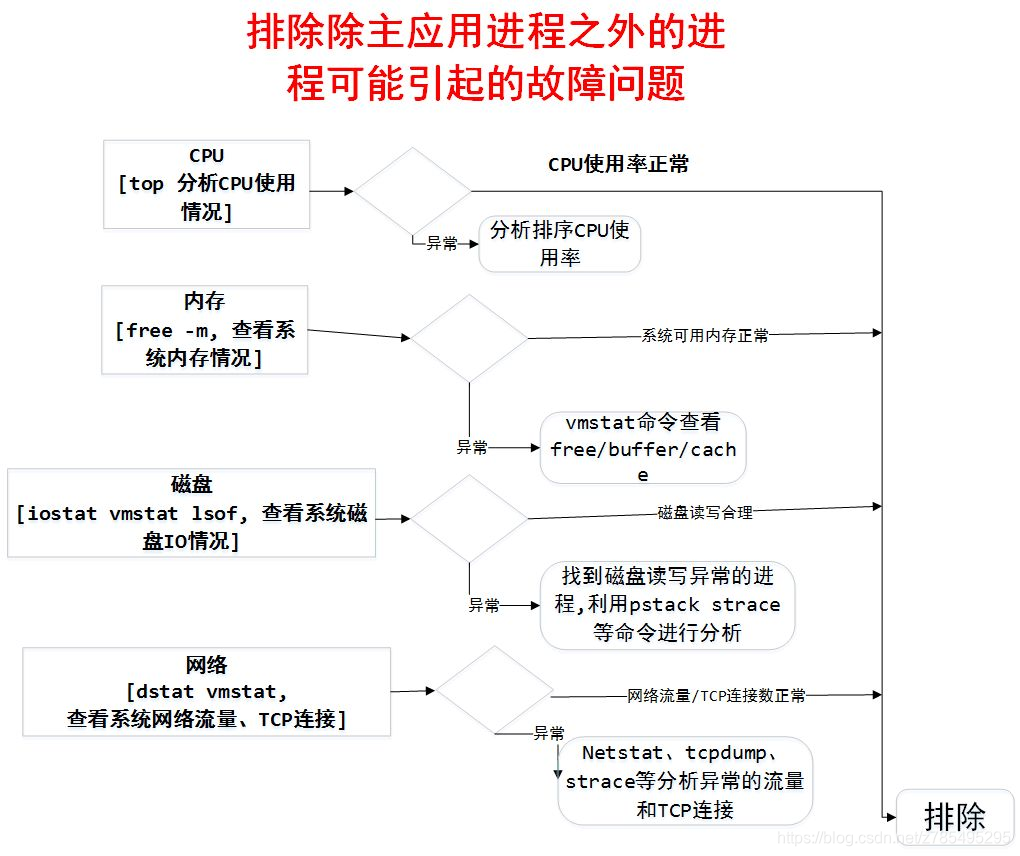
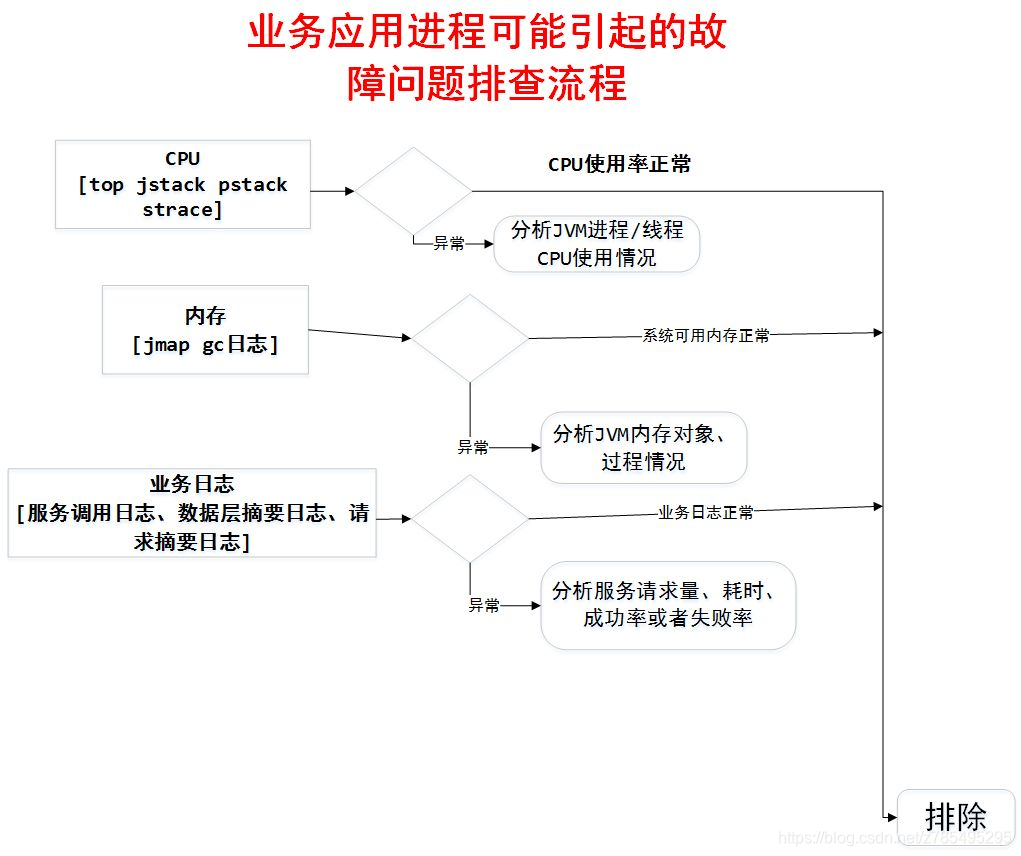
2.Linux 常用的效能分析工具
top命令
檢視cpu佔用率檢視佔用高的程序號
第一步:輸入TOP命令 第二步: 輸入 shift+h ,開啟執行緒模式,檢視目前最耗系統資源的執行緒是哪些
可以再按 1用CPU模式看各個CPU資源的使用情況 按O檢視幫助
pgrep 查詢程序的工具
pgrep 是通過程式的名字來查詢程序的工具,一般是用來判斷程式是否正在執行。在伺服器的配置和管理中,這個工具常被應用,簡單明瞭 用法:
pgrep 引數選項 程式名
eg:
pgrep java#查詢出JAVA程序的程序號 常用引數: -l 列出程式名和程序ID -o 程序起始的ID -n 程序終止的ID
彙總某個程序下所有的執行緒數
方法一
:ls /proc/20967/task/|wc -l: 20967是程序號方法二 :
ps -eLf | grep 20967 |wc -lps:該方法對於排查JAVA各種容器(eg:tomcat)由於建立過多執行緒,導致cpu耗費大量的資源進行上線文切換非常有幫助。
我們可以寫一個指令碼,當執行緒數>閥值,則進行jstack dunp
top+jstack
使用top命令看執行緒資源使用情況後,可以得到這些執行緒的pid,然後把這些執行緒號轉換成16進位制,
printf "%x" pidjstack -l pid |grep xx(pid:java程序號,xx為16進位制執行緒pid) :把java執行緒快照給dump下來.可以用來排查死鎖,以及耗費系統資源執行緒當前的執行情況eg:
jstack -l pid >jstack_dump.log#將當前JVM執行緒快照dump到jstack_dump.log檔案中
grep jstack_dump.log16進位制號 #這樣可以看看當前這些耗費資源的執行緒的記憶體情況
jstack 列印當前執行緒堆疊情況
命令格式: jstack [-option] jvm_pid 引數: -l 列印關於鎖的堆疊資訊(long listing. Prints additional information about locks) -m 混合列印模式,可列印C++和JAVA的堆疊資訊 -h 列印幫助資訊
檢視執行時gc情況命令
$JAVA_HOME/bin/
jstat -gcutil pgrep java1000 10 (後三個引數是PID,掃描間隔時間單位毫秒,掃描次數) $JAVA_HOME/bin/jstat -gcpgrep java1000 10
對於網路問題的定位
可以通過netstat命令來檢視某個時間段的網路重傳率。 通過netstat -l enX -sp tcp 收集傳送的TCP包數和retransmit的包數,間隔一定時間過後 再次收集這兩個數值,分別相減後相除,可得出在此取樣時間內的TCP重傳率
jps 顯示當前所有java程序pid的命令
jps:顯示當前使用者的所有java程序的PID jps -v 3331:顯示虛擬機器引數 jps -m 3331:顯示傳遞給main()函式的引數 jps -l 3331:顯示主類的全路徑
jmap
生成堆轉儲快照(heapdump)
常用指令 jmap -heap 3331:檢視java 堆(heap)使用情況 jmap -histo 3331:檢視堆記憶體(histogram)中的物件數量及大小 jmap -histo:live 3331:JVM會先觸發gc,然後再統計資訊 jmap -dump:format=b,file=heapDump 3331:將記憶體使用的詳細情況輸出到檔案,之後一般使用其他工具進行分析。
jhat
一般與jmap搭配使用,用來分析jmap生成的堆轉儲檔案。 由於有很多視覺化工具(Eclipse Memory Analyzer 、IBM HeapAnalyzer)可以替代,所以很少用。不過在沒有視覺化工具的機器上也是可用的。
常用指令 jmap -dump:format=b,file=heapDump 3331 + jhat heapDump:解析Java堆轉儲檔案,並啟動一個 web server
常見問題定位過程
頻繁GC問題或記憶體溢位問題
一、使用jps檢視執行緒ID
二、使用jstat -gc 3331 250 20 檢視gc情況,一般比較關注PERM區的情況,檢視GC的增長情況。
三、使用jstat -gccause:額外輸出上次GC原因
四、使用jmap -dump:format=b,file=heapDump 3331生成堆轉儲檔案
五、使用jhat或者視覺化工具(Eclipse Memory Analyzer 、IBM HeapAnalyzer)分析堆情況。
六、結合程式碼解決記憶體溢位或洩露問題。
死鎖問題
一、使用jps檢視執行緒ID
二、使用jstack 3331:檢視執行緒情況