
Python學習【第8篇】:Python之常用模組一(主要是正則以及collections模組) python--------------常用模組之正則
一、認識模組
什麼是模組:一個模組就是一個包含了python定義和宣告的檔案,檔名就是加上.py的字尾,但其實import載入的模組分為四個通用類別 :
1.使用python編寫的程式碼(.py檔案)
2.已被編譯為共享庫二和DLL的C或C++擴充套件
3.包好一組模組的包
4.使用C編寫並連線到python直譯器的內建模組
為何要使用莫模組?
如果你想退出python直譯器然後重新進入,那麼你之前定義的函式或變數都將丟失,因此我們通常將程式寫到檔案中以便永久儲存下來,需要時,就通過python test.py 方式去執行,此時test.py被稱為指令碼script。
隨著程式的發展,功能越來越多,為了方便管理,我們通常將檔案分成一個個的檔案,這樣做程式的結構更清晰,方便管理。這時我們不僅僅可以吧這些檔案當做指令碼去執行,還可以把它們當做模組來匯入到其他模組中,實現了功能的重複利用。
二、常見模組分類
常用模組一、
collocations 模組
時間模組
random模組
os模組
sys模組
序列化模組
re模組
常用模組二:這些模組和麵向物件有關
hashlib模組
configparse模組
logging模組
三、正則表示式
像我們平常見的那些註冊頁面啥的,都需要我們輸入手機號碼吧,你想我們的電話號碼也是有限定的吧(手機號碼一共11位,並且只以13,14,15,17,18開頭的數字這些特點)如果你的輸入有誤就會提示,那麼實現這個程式的話你覺得用While迴圈so easy嘛,那麼我們來看看實現的結果。


1 while True:
2 phone_number=input('請輸入你的電話號碼:')
3 if len(phone_number)==11 and phone_number.isdigit()\
4 and (phone_number.startswith('13')\
5 or phone_number.startswith('14') \
6 or phone_number.startswith('15') \ 7 or phone_number.startswith('17') \ 8 or phone_number.startswith('18')): 9 print('是合法的手機號碼') 10 else: 11 print('不是合法的手機號碼')
看到這個程式碼,雖說理解很容易,但是我還有更簡單的方法。那我們一起來看看吧。
1 import re
2 phone_number=input('請輸入你的電話號碼:')
3 if re.match('^(13|14|15|17|18)[0-9]{9}$',phone_number):
4 '''^這個符號表示的是判斷是不是以13|14|15|17|18開頭的,
5 [0-9]: []表示一個字元組,可以表示0-9的任意字元
6 {9}:表示後面的數字重複九次
7 $:表示結束符
8 '''
9 print('是合法的手機號碼')
10 else:
11 print('不是合法的手機號碼')
大家可能都覺的第一種方法更簡單吧,但是如果我讓你從整個檔案中匹配出所有的手機號碼,你能用python寫出來嗎?但是匯入re模組和利用正則表示式就可以解決這一個問題了。
那麼什麼是正則呢?
首先你要知道的是,談到正則,就只和字串相關了。線上測試工具 http://tool.chinaz.com/regex/
比如你要用‘1’去匹配‘1’,或者用‘2’去匹配‘2’,直接就可以匹配上。
字元組:[字元組]
在同一位置可能出現的各種字元組成了一個字元組,在正則表示式中用[]表示
字元分為很多類,比如數字,字母,標點等登。
假如你現在要求一個位置‘只能出現一個數字’,那麼這個位置上的字元只能是0、1、2、3.......9這是個數之一。
字元組:

字元:

量詞:
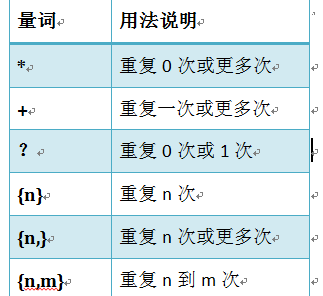
.^$

*+?{}

注意:前面的*,+,?等都是貪婪匹配,也就是儘可能多的匹配,後面加?就變成了非貪婪匹配,也就是惰性匹配。
貪婪匹配:

幾個常用的配貪婪匹配
?| 1 2 3 4 5 |
*
?;重複任意次,但儘可能少重複
+
?:重複一次或更多次,但儘可能少重複
??:重複
0
次或
1
次,但儘可能少重複
{n,m}:重複n到m次,但儘可能少重複
{n,}: 重複n次以上,但儘可能少重複
|
.*?的用法:
?| 1 2 3 4 5 6 |
.是任意字元
*
是取
0
到無限長度
?是非貪婪模式
和在一起就是取儘量少的任意字元,一般不會這麼單獨寫,大多用在:
.
*
?x
意思就是取前面任意長度的字元,直到一個x出現
|
字符集:
分組()與或|[^]:
?| 1 2 3 4 5 6 7 8 9 10 |
(
1
)^[
1
-
9
]\d{
13
,
16
}[
0
-
9x
]$
#^以數字0-9開始,
\d{
13
,
16
}重複
13
次到
16
次
$結束標誌
上面的表示式可以匹配一個正確的身份證號碼
(
2
)^[
1
-
9
]\d{
14
}(\d{
2
}[
0
-
9x
])?$
#?重複0次或者1次,當是0次的時候是15位,是1的時候是18位
(
3
)^([
1
-
9
]\d{
16
}[
0
-
9x
]|[
1
-
9
]\d{
14
})$
#表示先匹配[1-9]\d{16}[0-9x]如果沒有匹配上就匹配[1-9]\d{14}
|
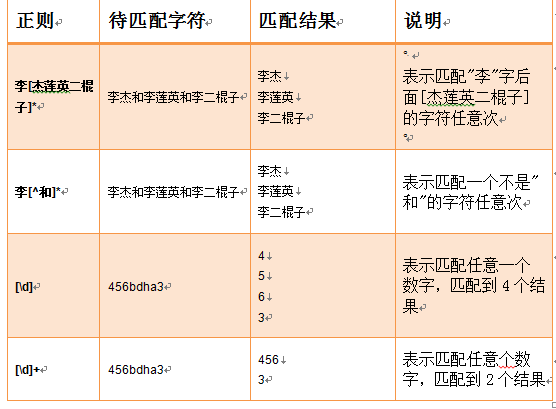
1 舉個例子,比如html原始碼中有<title>xxx</title>標籤,用以前的知識,我們只能確定原始碼中的<title>和</title>是固定不變的。因此,如果想獲取頁面標題(xxx),充其量只能寫一個類似於這樣的表示式:<title>.*</title>,而這樣寫匹配出來的是完整的<title>xxx</title>標籤,並不是單純的頁面標題xxx。
2
3 想解決以上問題,就要用到斷言知識。
4
5 在講斷言之前,讀者應該先了解分組,這有助於理解斷言。
6
7 分組在正則中用()表示,根據小菜理解,分組的作用有兩個:
8
9
10
11 n 將某些規律看成是一組,然後進行組級別的重複,可以得到意想不到的效果。
12
13 n 分組之後,可以通過後向引用簡化表示式。 14 15 16 17 18 19 先來看第一個作用,對於IP地址的匹配,簡單的可以寫為如下形式: 20 21 \d{1,3}.\d{1,3}.\d{1,3}.\d{1,3} 22 23 但仔細觀察,我們可以發現一定的規律,可以把.\d{1,3}看成一個整體,也就是把他們看成一組,再把這個組重複3次即可。表示式如下: 24 25 \d{1,3}(.\d{1,3}){3} 26 27 這樣一看,就比較簡潔了。 28 29 30 31 再來看第二個作用,就拿匹配<title>xxx</title>標籤來說,簡單的正則可以這樣寫: 32 33 <title>.*</title> 34 35 可以看出,上邊表示式中有兩個title,完全一樣,其實可以通過分組簡寫。表示式如下: 36 37 <(title)>.*</\1> 38 39 這個例子實際上就是反向引用的實際應用。對於分組而言,整個表示式永遠算作第0組,在本例中,第0組是<(title)>.*</\1>,然後從左到右,依次為分組編號,因此,(title)是第1組。 40 41 用\1這種語法,可以引用某組的文字內容,\1當然就是引用第1組的文字內容了,這樣一來,就可以簡化正則表示式,只寫一次title,把它放在組裡,然後在後邊引用即可。 42 43 以此為啟發,我們可不可以簡化剛剛的IP地址正則表示式呢?原來的表示式為\d{1,3}(.\d{1,3}){3},裡邊的\d{1,3}重複了兩次,如果利用後向引用簡化,表示式如下: 44 45 (\d{1,3})(.\1){3} 46 47 簡單的解釋下,把\d{1,3}放在一組裡,表示為(\d{1,3}),它是第1組,(.\1)是第2組,在第2組裡通過\1語法,後向引用了第1組的文字內容。 48 49 經過實際測試,會發現這樣寫是錯誤的,為什麼呢? 50 51 小菜一直在強調,後向引用,引用的僅僅是文字內容,而不是正則表示式! 52 53 也就是說,組中的內容一旦匹配成功,後向引用,引用的就是匹配成功後的內容,引用的是結果,而不是表示式。 54 55 因此,(\d{1,3})(.\1){3}這個表示式實際上匹配的是四個數都相同的IP地址,比如:123.123.123.123。 56 57 58 59 至此,讀者已經掌握了傳說中的後向引用,就這麼簡單。
分組命名:語法(?p<name>)注意先命名,後正則
import re
import re
ret=re.search('<(\w+)>\w+<(/\w+)>','<h1>hello</h1>')
print(ret.group())
# 給分組起個名字。就用下面的分組命名,上面的方法和下面的分組命名是一樣的,只不過就是給命了個名字
ret=re.search('<(?P<tag_name>\w+)>\w+</(?P=tag_name)>','<h1>hello</h1>')
#(?P=tag_name)就代表的是(\w+)
print(ret.group()) # 瞭解(和上面的是一樣的,是上面方式的那種簡寫)
ret=re.search(r'<(\w+)>\w+</\1>','<h1>hello</h1>')
print(ret.group(1))
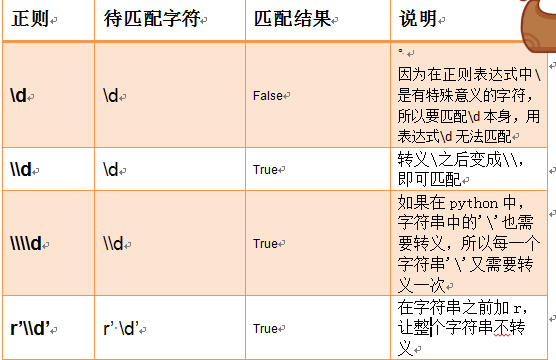
轉義符:
四、re模組
1 # 1.re模組下的常用方法
2 # 1.findall方法
3 import re
4 ret = re.findall('a','eva ang egons')
5 # #返回所有滿足匹配條件的結果,放在列表裡
6 print(ret)
7
8 # 2.search方法
9 # 函式會在字串中查詢模式匹配,只會找到第一個匹配然後返回
10 # 一個包含匹配資訊的物件,該物件通過呼叫group()方法得到匹配的
11 # 字串,如果字串沒有匹配,則報錯
12 ret = re.search('s','eva ang egons')#找第一個
13 print(ret.group())
14
15
16 # 3.match方法
17 print(re.match('a','abc').group())
18 #同search,只從字串開始匹配,並且guoup才能找到
19
20
21 # 4.split方法
22 print(re.split('[ab]','abcd')) 23 #先按'a'分割得到''和'bcd',在對''和'bcd'分別按'b'分割 24 25 26 # 5.sub方法 27 print(re.sub('\d','H','eva3sdf4ahi4asd45',1)) 28 # 將數字替換成'H',引數1表示只替換一個 29 30 31 # 6.subn方法 32 print(re.subn('\d','H','eva3sdf4ahi4asd45')) 33 #將數字替換成’H‘,返回元組(替換的結果,替換了多少次) 34 35 36 # 7.compile方法 37 obj = re.compile('\d{3}')#將正則表示式編譯成一個正則表示式物件,規則要匹配的是三個數字 38 print(obj) 39 ret = obj.search('abc12345eeeee')#正則表示式物件呼叫search,引數為待匹配的字串 40 print(ret.group()) #.group一下就顯示出結果了 41 42 # 8.finditer方法 43 ret = re.finditer('\d','dsf546sfsc')#finditer返回的是一個存放匹配結果的迭代器 44 # print(ret)#<callable_iterator object at 0x00000000021E9E80> 45 print(next(ret).group())#檢視第一個結果 46 print(next(ret).group())#檢視第二個結果 47 print([i.group() for i in ret] )#檢視剩餘的左右結果
1 import re
2 ret = re.findall('www.(baidu|oldboy).com','www.oldboy.com')
3 print(ret) #結果是['oldboy']這是因為findall會優先把匹配結果組裡內容返回,如果想要匹配結果,取消許可權即可
4
5 ret = re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
6 print(ret) #['www.oldboy.com']
1 ret = re.split('\d+','eva123dasda9dg')#按數字分割開了
2 print(ret) #輸出結果:['eva', 'dasda', 'dg']
3
4 ret = re.split('(\d+)','eva123dasda9dg')
5 print(ret) #輸出結果:['eva', '123', 'dasda', '9', 'dg']
6 #
7 # 在匹配部分加上()之後和不加括號切出的結果是不同的,
8 # 沒有括號的沒有保留所匹配的項,但是有括號的卻能夠保留了
9 # 匹配的項,這個在某些需要保留匹配部分的使用過程是非常重要的
五、re模組和正則表示式的關係
re模組和正則表示式沒有一點毛線關係。re模組和正則表示式的關係類似於time模組和時間的關係,你沒有學習python之前,也不知道有一個time模組,但是你已經認識時間了呀,12:30就表示中午十二點半。時間有自己的格式,年月日時分秒,已成為一種規則。你早就牢記於心了,time模組只不過是python提供給我們的可以方便我們操作時間的一個工具而已。
六、collections模組
在內建資料型別(dict,list,set,tuple)的基礎上,collections 模組還提供了幾個額外的資料型別:
1.namedtuple:生成可以使用名字來訪問元素內容的tuple
2.deque:雙向佇列(兩頭都可進可出,但是不能取中間的值),可以快速的從另外一側追加和推出物件
3.Counter:計數器,主要用來計數
4.OrderedDict:有序字典
5.defaultdict:帶有預設值的字典
namedtuple:
我們知道tuple可以表示不變集合,例如,一個點的二維座標就可以表示成:p=(1,2)
但是,看到(1,2),很難看出這個tuple是用來表示座標的。
那麼,我們的namedtuple就能用上了。
namedtuple('名稱',‘屬性list’)
?| 1 2 3 4 |
from
collections
import
namedtuple
point
=
namedtuple(
'point'
,[
'x'
,
'y'
])
p
=
point(
1
,
2
)
print
(p.x,p.y)、<br><br><br>
|
Circle = namedtuple('Circle', ['x', 'y', 'r'])#用座標和半徑表示一個圓
deque
?| 1 2 3 4 5 6 7 8 9 10 |
單向佇列<br>
# import queue #佇列模組
# q = queue.Queue()
# q.put(10)
# q.put(20)
# q.put(30)
# # 10 20 30
# print(q.get())
# print(q.get())
# print(q.get())
# print(q.get())
|
deque是為了高效實現插入和刪除操作的雙向佇列,適用於佇列和棧
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
from
collections
import
deque
q
=
deque([
'a'
,
'b'
,
'c'
])
q.append(
'ee'
)
#新增元素
q.append(
'ff'
)
q.append(
'qq'
)
print
(q)
q.appendleft(
'www'
)
#從左邊新增
print
(q)
q.pop()
#刪除元素
q.popleft()
#從左邊刪除元素
print
(q)
|
OrderedDict
使用字典時,key是無序的。在對字典做迭代時,我們無法確定key的順序。如果要保持key的順序,可以用OrderedDict
?| 1 |
from
collections
import
OrderedDict
|
d = {'z':'qww','x':'asd','y':'asd','name':'alex'}
print(d.keys()) #key是無序的
?
| 1 |
od
=
OrderedDict([(
'a'
,
1
), (
'b'
,
2
), (
'c'
,
3
)])
print
(od)
# OrderedDict的Key是有序的 <br>OrderedDict([('a', 1), ('b', 2), ('c', 3)])<br><br><br>
|
OrderedDict的Key會按照插入的順序排列,不是Key本身排序:
od = OderedDict ()
od['z']=1
od['y']=2
od['x']=3
print(od.keys()) #按照插入額key的順序返回
defaultdict
1 d = {'z':'qww','x':'asd','y':'asd','name':'alex'}
2 print(d.keys())
3 from collections import defaultdict
4 values = [11,22,33,44,55,66,77,88,99]
5 my_dict = defaultdict(list)
6 for v in values: 7 if v>66: 8 my_dict['k1'].append(v) 9 else: 10 my_dict['k2'].append(v) 11 print(my_dict)
1 from collections import defaultdict
2 dd = defaultdict(lambda: 'N/A')
3 dd['key1'] = 'abc'
4 print(dd['key1']) # key1存在
5
6 print(dd['key2']) # key2不存在,返回預設值
Counter
Counter類的目的是用來跟蹤值出現的次數。它是一個無序的容器型別,以字典的鍵值對形式儲存,其中元素作為key,其計數作為value。計數值可以是任意的Interger(包括0和負數)。Counter類和其他語言的bags或multisets很相似。
from collections import Counter
c = Counter('abcdeabcdabcaba')
print(c)
# 輸出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
其他詳細內容 http://www.cnblogs.com/Eva-J/articles/7291842.html
一、認識模組
什麼是模組:一個模組就是一個包含了python定義和宣告的檔案,檔名就是加上.py的字尾,但其實import載入的模組分為四個通用類別 :
1.使用python編寫的程式碼(.py檔案)
2.已被編譯為共享庫二和DLL的C或C++擴充套件
3.包好一組模組的包
4.使用C編寫並連線到python直譯器的內建模組
為何要使用莫模組?
如果你想退出python直譯器然後重新進入,那麼你之前定義的函式或變數都將丟失,因此我們通常將程式寫到檔案中以便永久儲存下來,需要時,就通過python test.py 方式去執行,此時test.py被稱為指令碼script。
隨著程式的發展,功能越來越多,為了方便管理,我們通常將檔案分成一個個的檔案,這樣做程式的結構更清晰,方便管理。這時我們不僅僅可以吧這些檔案當做指令碼去執行,還可以把它們當做模組來匯入到其他模組中,實現了功能的重複利用。
二、常見模組分類
常用模組一、
collocations 模組
時間模組
random模組
os模組
sys模組
序列化模組
re模組
常用模組二:這些模組和麵向物件有關
hashlib模組
configparse模組
logging模組
三、正則表示式
像我們平常見的那些註冊頁面啥的,都需要我們輸入手機號碼吧,你想我們的電話號碼也是有限定的吧(手機號碼一共11位,並且只以13,14,15,17,18開頭的數字這些特點)如果你的輸入有誤就會提示,那麼實現這個程式的話你覺得用While迴圈so easy嘛,那麼我們來看看實現的結果。
1 while True:
2 phone_number=input('請輸入你的電話號碼:')
3 if len(phone_number)==11 and phone_number.isdigit()\
4 and (phone_number.startswith('13')\
5 or phone_number.startswith('14') \
6 or phone_number.startswith('15') \ 7 or phone_number.startswith('17') \ 8 or phone_number.startswith('18')): 9 print('是合法的手機號碼') 10 else: 11 print('不是合法的手機號碼')
看到這個程式碼,雖說理解很容易,但是我還有更簡單的方法。那我們一起來看看吧。
1 import re
2 phone_number=input('請輸入你的電話號碼:')
3 if re.match('^(13|14|15|17|18)[0-9]{9}$',phone_number):
4 '''^這個符號表示的是判斷是不是以13|14|15|17|18開頭的,
5 [0-9]: []表示一個字元組,可以表示0-9的任意字元
6 {9}:表示後面的數字重複九次
7 $:表示結束符
8 '''
9 print('是合法的手機號碼')
10 else:
11 print('不是合法的手機號碼')
大家可能都覺的第一種方法更簡單吧,但是如果我讓你從整個檔案中匹配出所有的手機號碼,你能用python寫出來嗎?但是匯入re模組和利用正則表示式就可以解決這一個問題了。
那麼什麼是正則呢?
首先你要知道的是,談到正則,就只和字串相關了。線上測試工具 http://tool.chinaz.com/regex/
比如你要用‘1’去匹配‘1’,或者用‘2’去匹配‘2’,直接就可以匹配上。
字元組:[字元組]
在同一位置可能出現的各種字元組成了一個字元組,在正則表示式中用[]表示
字元分為很多類,比如數字,字母,標點等登。
假如你現在要求一個位置‘只能出現一個數字’,那麼這個位置上的字元只能是0、1、2、3.......9這是個數之一。
字元組:
字元:
量詞:
.^$
*+?{}
注意:前面的*,+,?等都是貪婪匹配,也就是儘可能多的匹配,後面加?就變成了非貪婪匹配,也就是惰性匹配。
貪婪匹配:
幾個常用的配貪婪匹配
?| 1 2 3 4 5 |
*
?;重複任意次,但儘可能少重複
+
?:重複一次或更多次,但儘可能少重複
??:重複
0
次或
1
次,但儘可能少重複
{n,m}:重複n到m次,但儘可能少重複
{n,}: 重複n次以上,但儘可能少重複
|
.*?的用法:
?| 1 2 3 4 5 6 |
.是任意字元
*
是取
0
到無限長度
?是非貪婪模式
和在一起就是取儘量少的任意字元,一般不會這麼單獨寫,大多用在:
.
*
?x
意思就是取前面任意長度的字元,直到一個x出現
|
字符集:
分組()與或|[^]:
?| 1 2 3 4 5 6 7 8 9 10 |
(
1
)^[
1
-
9
]\d{
13
,
16
}[
0
-
9x
]$
#^以數字0-9開始,
\d{
13
,
16
}重複
13
次到
16
次
$結束標誌
上面的表示式可以匹配一個正確的身份證號碼
(
2
)^[
1
-
9
]\d{
14
}(\d{
2
}[
0
-
9x
])?$
#?重複0次或者1次,當是0次的時候是15位,是1的時候是18位
(
3
)^([
1
-
9
]\d{
16
}[
0
-
9x
]|[
1
-
9
]\d{
14
})$
#表示先匹配[1-9]\d{16}[0-9x]如果沒有匹配上就匹配[1-9]\d{14}
|
1 舉個例子,比如html原始碼中有<title>xxx</title>標籤,用以前的知識,我們只能確定原始碼中的<title>和</title>是固定不變的。因此,如果想獲取頁面標題(xxx),充其量只能寫一個類似於這樣的表示式:<title>.*</title>,而這樣寫匹配出來的是完整的<title>xxx</title>標籤,並不是單純的頁面標題xxx。
2
3