
elasticsearch分詞器
在全文搜尋(Fulltext Search)中,詞(Term)是一個搜尋單元,表示文字中的一個詞,標記(Token)表示在文字欄位中出現的詞,由詞的文字、在原始文字中的開始和結束偏移量、以及資料型別等組成。ElasticSearch 把文件資料寫到倒排索引(Inverted Index)的結構中,倒排索引建立詞(Term)和文件之間的對映,索引中的資料是面向詞,而不是面向文件的。分析器(Analyzer)的作用就是分析(Analyse),用於把傳入Lucene的文件資料轉化為倒排索引,把文字處理成可被搜尋的詞。分析器由一個分詞器(Tokenizer)和零個或多個標記過濾器(TokenFilter)組成,也可以包含零個或多個字元過濾器(Character Filter)。
在ElasticSearch引擎中,分析器的任務是分析(Analyze)文字資料,分析是分詞,規範化文字的意思,其工作流程是:
- 首先,字元過濾器對分析(analyzed)文字進行過濾和處理,例如從原始文字中移除HTML標記,根據字元對映替換文字等,
- 過濾之後的文字被分詞器接收,分詞器把文字分割成標記流,也就是一個接一個的標記,
- 然後,標記過濾器對標記流進行過濾處理,例如,移除停用詞,把詞轉換成其詞幹形式,把詞轉換成其同義詞等,
- 最終,過濾之後的標記流被儲存在倒排索引中;
- ElasticSearch引擎在收到使用者的查詢請求時,會使用分析器對查詢條件進行分析,根據分析的結構,重新構造查詢,以搜尋倒排索引,完成全文搜尋請求,
可見,分析器扮演的是處理索引資料和查詢條件的重要角色。在2.4版本中,ElasticSearch 預定義了7個分析器,並且支援使用者根據預定義的字元過濾器,分詞器和標記過濾器建立自定義的分析器,以滿足使用者多樣性的文字分析需求。
使用者在建立索引時配置索引的分析,通過向ElasticSearch傳送請求,在請求body的settings 配置節中設定索引的分析器,例如,為索引配置預設的分析器:

"settings":{
"index":{
"analysis":{
"analyzer":{
"default":{
"type":"standard"
,"stopwords":"_english_"
}
}
}
}
}
一,字元過濾器(Char Filter)
字元過濾器對未經分析的文字起作用,作用於被分析的文字欄位(該欄位的index屬性為analyzed),字元過濾器在分詞器之前工作,用於從文件的原始文字去除HTML標記(markup),或者把字元“&”轉換為單詞“and”。ElasticSearch 2.4版本內建3個字元過濾器,分別是:對映字元過濾器(Mapping Char Filter)、HTML標記字元過濾器(HTML Strip Char Filter)和模式替換字元過濾器(Pattern Replace Char Filter)。
1,對映字元過濾器
對映字元過濾器,型別是mapping,需要建立一個查詢字元和替換字元的對映(Mapping),過濾器根據對映把文字中的字元替換成指定的字元。

{
"index" : {
"analysis" : {
"char_filter" : {
"my_mapping" : {
"type" : "mapping",
"mappings" : [
"ph => f",
"qu => k"
]
}
},
"analyzer" : {
"custom_with_char_filter" : {
"tokenizer" : "standard",
"char_filter" : ["my_mapping"]
}
}
}
}
}
2,HTML標記字元過濾器
HTML標記字元過濾器,型別是html_strip,用於從原始文字中去除HTML標記。
3,模式替換字元過濾器
模式替換字元過濾器,型別是pattern_replace,它使用正則表示式(Regular Expression)匹配字元,把匹配到的字元替換為指定的替換字串。
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}
}
}
}
pattern引數:指定Java正則表示式;
replacement引數:指定替換字串,把正則表示式匹配的字串替換為replacement引數指定的字串;
二,分詞器(Tokenizer)
分詞器在字元過濾器之後工作,用於把文字分割成多個標記(Token),一個標記基本上是詞加上一些額外資訊,分詞器的處理結果是標記流,它是一個接一個的標記,準備被過濾器處理。ElasticSearch 2.4版本內建很多分詞器,本節簡單介紹常用的分詞器。
1,標準分詞器(Standard Tokenizer)
標準分詞器型別是standard,用於大多數歐洲語言,使用Unicode文字分割演算法對文件進行分詞。
2,字母分詞器(Letter Tokenizer)
字元分詞器型別是letter,在非字母位置上分割文字,這就是說,根據相鄰的詞之間是否存在非字母(例如空格,逗號等)的字元,對文字進行分詞,對大多數歐洲語言非常有用。
3,空格分詞器(Whitespace Tokenizer)
空格分詞型別是whitespace,在空格處分割文字
4,小寫分詞器(Lowercase Tokenizer)
小寫分詞器型別是lowercase,在非字母位置上分割文字,並把分詞轉換為小寫形式,功能上是Letter Tokenizer和 Lower Case Token Filter的結合(Combination),但是效能更高,一次性完成兩個任務。
5,經典分詞器(Classic Tokenizer)
經典分詞器型別是classic,基於語法規則對文字進行分詞,對英語文件分詞非常有用,在處理首字母縮寫,公司名稱,郵件地址和Internet主機名上效果非常好。
三,標記過濾器(Token Filter)
分析器包含零個或多個標記過濾器,標記過濾器在分詞器之後工作,用來處理標記流中的標記。標記過濾從分詞器中接收標記流,能夠刪除標記,轉換標記,或新增標記。ElasticSearch 2.4版本內建很多標記過濾器,本節簡單介紹常用的過濾器。
1,小寫標記過濾器(Lowercase)
型別是lowercase,用於把標記轉換為小寫形式,通過language引數指定語言,小寫標記過濾器支援的語言有:Greek, Irish, and Turkish
index :
analysis :
analyzer :
myAnalyzer2 :
type : custom
tokenizer : myTokenizer1
filter : [myTokenFilter1, myGreekLowerCaseFilter]
char_filter : [my_html]
tokenizer :
myTokenizer1 :
type : standard
max_token_length : 900
filter :
myTokenFilter1 :
type : stop
stopwords : [stop1, stop2, stop3, stop4]
myGreekLowerCaseFilter :
type : lowercase
language : greek
char_filter :
my_html :
type : html_strip
escaped_tags : [xxx, yyy]
read_ahead : 1024
2,停用詞標記過濾器(Stopwords)
型別是stop,用於從標記流中移除停用詞。引數stopwords用於指定停用詞,ElasticSearch 2.4版本提供的預定義的停用詞列表:預定義的英語停用詞是_english_,使用預定義的英語停用詞列表是 “stopwords” :"_english_"
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"my_stop": {
"type": "stop",
"stopwords": ["and", "is", "the"]
}
}
}
}
}
3,詞幹過濾器(Stemmer)
型別是stemmer,用於把詞轉換為其詞根形式儲存在倒排索引,能夠減少標記。
{
"index" : {
"analysis" : {
"analyzer" : {
"my_analyzer" : {
"tokenizer" : "standard",
"filter" : ["standard", "lowercase", "my_stemmer"]
}
},
"filter" : {
"my_stemmer" : {
"type" : "stemmer",
"name" : "english"
}
}
}
}
}
4,同義詞過濾器(Synonym)
型別是synonym,在分析階段,基於同義詞規則,把詞轉換為其同義詞儲存在倒排索引中
{
"index" : {
"analysis" : {
"analyzer" : {
"synonym" : {
"tokenizer" : "whitespace",
"filter" : ["synonym"]
}
},
"filter" : {
"synonym" : {
"type" : "synonym",
"synonyms_path" : "analysis/synonym.txt"
}
}
}
}
}
同義詞檔案的格式示例:
# Blank lines and lines starting with pound are comments. # Explicit mappings match any token sequence on the LHS of "=>" # and replace with all alternatives on the RHS. These types of mappings # ignore the expand parameter in the schema. # Examples: i-pod, i pod => ipod, sea biscuit, sea biscit => seabiscuit # Equivalent synonyms may be separated with commas and give # no explicit mapping. In this case the mapping behavior will # be taken from the expand parameter in the schema. This allows # the same synonym file to be used in different synonym handling strategies. # Examples: ipod, i-pod, i pod foozball , foosball universe , cosmos # If expand==true, "ipod, i-pod, i pod" is equivalent # to the explicit mapping: ipod, i-pod, i pod => ipod, i-pod, i pod # If expand==false, "ipod, i-pod, i pod" is equivalent # to the explicit mapping: ipod, i-pod, i pod => ipod # Multiple synonym mapping entries are merged. foo => foo bar foo => baz # is equivalent to foo => foo bar, baz
四,系統預定義的分析器
在建立索引對映時引用分析器,如果沒有定義分析器,那麼ElasticSearch將使用預設的分析器,使用者可以通過API設定預設的分析器。
default 邏輯名稱用於配置在索引和搜尋時使用的分析器,default_search 邏輯名稱用於配置在搜尋時使用的分析器。
index :
analysis :
analyzer :
default :
tokenizer : keyword
1,標準分析器(Standard)
分析器型別是standard,由標準分詞器(Standard Tokenizer),標準標記過濾器(Standard Token Filter),小寫標記過濾器(Lower Case Token Filter)和停用詞標記過濾器(Stopwords Token Filter)組成。引數stopwords用於初始化停用詞列表,預設是空的。
2,簡單分析器(Simple)
分析器型別是simple,實際上是小寫標記分詞器(Lower Case Tokenizer),在非字母位置上分割文字,並把分詞轉換為小寫形式,功能上是Letter Tokenizer和 Lower Case Token Filter的結合(Combination),但是效能更高,一次性完成兩個任務。
3,空格分析器(Whitespace)
分析器型別是whitespace,實際上是空格分詞器(Whitespace Tokenizer)。
4,停用詞分析器(Stopwords)
分析器型別是stop,由小寫分詞器(Lower Case Tokenizer)和停用詞標記過濾器(Stop Token Filter)構成,配置引數stopwords 或 stopwords_path指定停用詞列表。
5,雪球分析器(Snowball)
分析器型別是snowball,由標準分詞器(Standard Tokenizer),標準過濾器(Standard Filter),小寫過濾器(Lowercase Filter),停用詞過濾器(Stop Filter)和雪球過濾器(Snowball Filter)構成。引數language用於指定語言。
 View Code
View Code
6,自定義分析器
分析器型別是custom,允許使用者定製分析器。引數tokenizer 用於指定分詞器,filter用於指定過濾器,char_filter用於指定字元過濾器。
View Code
五,查詢分析
在分析(_ayalyze)端點上執行分析查詢,用於對查詢引數進行分析,並返回分析的結果
1,使用預設的分析器執行查詢分析
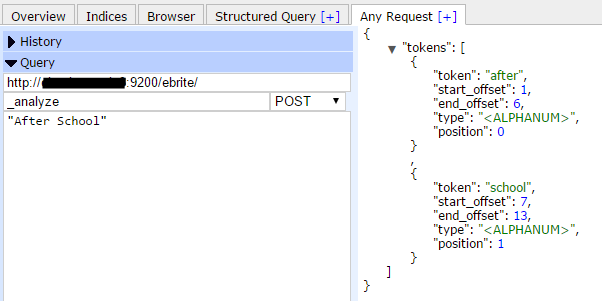
例如,在索引ebrite上執行分析查詢,分析字元“After School”,從返回的結果中,可以看到兩個標記(Token):“after”和“school”,型別(type)是字元數字型別(<ALPHANUM>),偏移量(offset)從1開始計數,位置(position)從0開始計數。
POST myindex/_analyze -d "After School"
2,指定分析器
POST myindex/_analyze?analyzer=standard -d "After School"

3,指定分詞器和過濾器
POST myindex/_analyze?tokenizer=standard&filters=lowercase -d "After School"
4,在特定的欄位上執行分析查詢
POST myindex/_analyze?field=doc_field&tokenizer=standard&filters=lowercase -d "After School"
附,在建立索引時,指定預設的分析器
示例程式碼,使用PUT動詞,在建立索引時指定預設的分析器,ElasticSearch引擎在索引文件時,使用預設的分析器對index屬性為analyzed的文字欄位執行分析操作,而非分析欄位,將不會應用分析操作。
View Code
參考文件:
作者:悅光陰
本文版權歸作者和部落格園所有,歡迎轉載,但未經作者同意,必須保留此段宣告,且在文章頁面醒目位置顯示原文連線,否則保留追究法律責任的權利。