
論文筆記《Very Deep Convolutional Networks for Large-Scale Image Recognition》
VGGNet在2014年的ILSVRC競賽上,獲得了top-1 error的冠軍和top-5 error的第二名,錯誤率分別為24.7%和7.3%,top-5 error的第一名是GoogLeNet 6.7%。在圖片定位任務中,也獲得了冠軍。網路層數由之前的AlexNet 的8層提高到了最高19層(網路E)。其突出貢獻在於,證明使用很小的卷積(3*3),增加網路深度,可以有效提升模型的效果。並且VGGNet對其他資料集具有很好的泛化能力。
VGGNet的一部分卷積層後面跟著池化層。總的結構是,在一系列卷積層(中間有池化層)後,是三個全連線層,前兩個全連線層均有4096個通道,第三個由1000個通道,用來分類。所有網路全連線層配置相同。所有隱藏層都使用了ReLU,但不使用LRN。
具體網路配置:
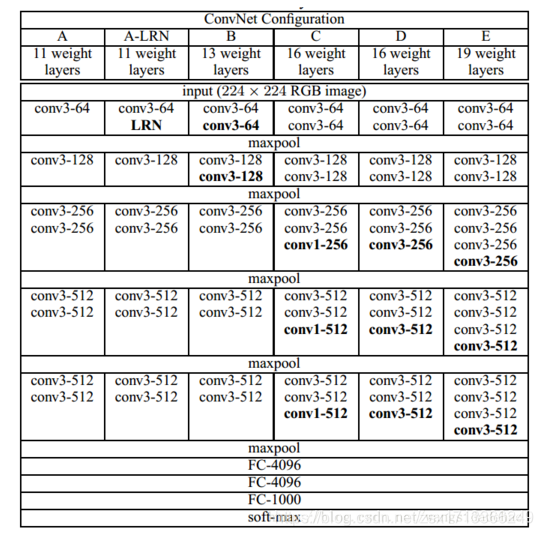
A網路是8個卷積層,3個全連線層,共11層。到E網路時是16個卷積層,3個全連線層。卷積層寬度(通道數)從64到512,每經過一次池化操作擴大一倍。
訓練:
1,通過使用帶有動量的小批量梯度下降法(batch size=256)來優化目標函式
2, 通過權重衰減(L2正則化)和對前兩個全連線進行droupout來實現正則化
3,使用尺寸抖動(scale jittering)方法:對原始圖片的裁剪尺寸,隨機從[256,512]的確定範圍內進行抽樣,這樣原始圖片尺寸不一,有利於訓練,比採用單一尺寸裁剪影象效果要好。增強了訓練集(另外也使用了影象翻轉來增強訓練集)。
作者在最後還將多個卷積網路進行融合,效能也有所提高。
最後,文中還介紹了VGGNet在定位任務中網路的訓練和測試過程,對之前的分類任務的網路模型做了一些修改就取得了第一名。之後將VGG網路應用於其他的資料集中,也取得了很不錯的成績。說明VGGNet 具有很好的泛化能力。
小結:
- 使用比較小的卷積核(3*3)比使用較大的卷積核(5*5、7*7、11*11等)的效果要好很多,不僅降低了錯誤率,而且還減少了需要訓練的引數。(用3x3的卷積核是因為這是能捕捉到各個方向的最小尺寸了。由於第一層中往往有大量的高頻和低頻資訊,卻沒有覆蓋到中間的頻率資訊,且步長過大,容易引起大量的混疊,因此卷積核尺寸和步長要儘量小)
- AlexNet中使用過的LRN(區域性響應歸一化)方法並不能降低錯誤率,相反還造成了記憶體損耗,增加了計算量
- 可以使用1*1的卷積核,能在不影響卷積層接受域的情況下增加決策函式的非線性,提升網路的表達能力,只增加很小的計算量。
(另外,1*1卷積核還有降維的作用,此處作者沒有提到)