
在plsql , sql語句中帶有中文的查詢條件查詢不到資料
PLSQL Developer中文顯示亂碼是因為Oracle資料庫所用的編碼和PLSQL Developer所用的編碼不同所導致的。
解決方法:
- 1. 先查詢Oracle所用的編碼
select userenv('language') from dual;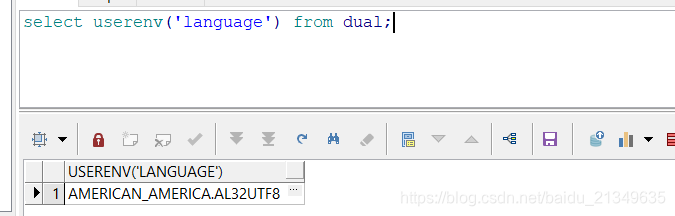
***- 2.環境變數中填加 NLS_LANG ***
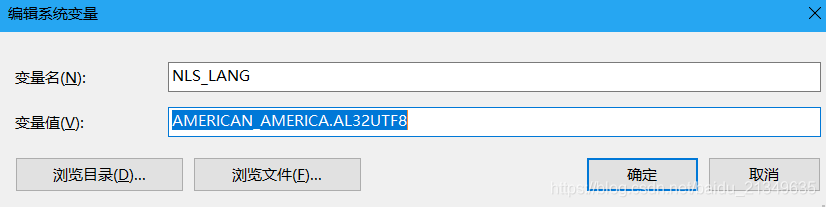
注意: 不用加到path中
參考地址:
https://blog.csdn.net/rensheng_ruxi/article/details/79907260
https://blog.csdn.net/vivienne_shar/article/details/73011718
相關推薦
在plsql , sql語句中帶有中文的查詢條件查詢不到資料
PLSQL Developer中文顯示亂碼是因為Oracle資料庫所用的編碼和PLSQL Developer所用的編碼不同所導致的。 解決方法: - 1. 先查詢Oracle所用的編碼 select userenv('language') from dual; **
sql語句中的 行轉列 查詢
有時候多行資料需要一行顯示, 這就需要行轉列的sql啦. 首先 ,要知道 行轉列當然是要以某個欄位進行分組的,然後再根據表中 一個欄位的值做轉列後的欄位名, 這個值所對應的另一個欄位作為 值 示例: 表名: XX班 班級 學生 身高
hibernate+mysql中文查詢不出結果,其他查詢正常,SQL語句也正常
做一個專案hibernate+MySQL資料庫,Java後臺全部正常,檢視Java想資料庫傳送的語句也是正常的,但是中文就是查詢不出結果,中文在Java中沒有亂碼,用new String(or_n
Mybatis中sql語句中的in查詢,一定要判斷null的情況
不嚴謹的寫法,可能會報錯:in (),這種情況不符合mysql的語法。 select from loanwhere LOAN_ID in <foreach item="item" index
封裝sql語句中in限制查詢個數的方法
sel rim () each tar blog and style months /* * 此方法用於每天淩晨取前一天的回滾用戶賬號 */ public function getRollBackAccount($startTime
sql語句中避免使用mysql函數,提升mysql處理能力。
語句 效率 eat mysql內置函數 服務 時間差 span 統一 ins 如下sql中不要用mysql內置函數now()等,這樣第一可以提高sql執行效率,第二統一程序層處理sql中時間參數,避免因服務器時間差導致問題產生。 使用PDO預處理,第一可以提高sql效率,
SQL語句中,為什麼where子句不能使用列別名,而order by卻可以?
當select的表示式很長時,我們經常會用as子句為該表示式指定別名,然而卻發現無法在Where條件中直接使用該別名作為判斷條件. 例如下面的SQL語句: select id, (c1 + c2) as s from t1 where s > 100 執行會
SQL語句中,子句不能使用列別名問題
轉一篇關於sql語句書寫規則的,給自己備忘,也分享出來,轉自此文章 當select的表示式很長時,我們經常會用as子句為該表示式指定別名,然而卻發現無法在Where條件中直接使用該別名作為判斷條件. 例如下面的SQL語句: select id, (c1 + c2) as s
pageHelper的使用步驟,省略sql語句中的limit
1.引架包。注意版本問題 <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper</artifactI
Oracle sql語句中(+)作用,就是匹配表
轉:https://www.cnblogs.com/ahudyan-forever/p/5703982.html Oracle sql語句中(+)作用 select * from operator_info o, group_info g where o.group_id = g
提交訂單效能優化系列之013-測試SQL語句中少查詢幾個欄位(包括大欄位)
概括總結 這一版本寫了兩個測試類,一個測試類中查詢全部欄位,另一個測試類中只查詢必要的欄位,然後對比效能。結論是:根據是減少的欄位的長度不同,效能會不同。具體請檢視下面的測試結果。 013版本更新說
機房收費系統之收取金額查詢(TPicker控制元件時間段取值、SQL語句中單引號與雙引號區別)
收取金額查詢窗體較組合查詢而言就是小菜一碟,但即便是內容較少也有其精華之處,現在分享一下我的學習過程吧^_^ 一、收取金額查詢窗體的流程圖: 二、問題集 這是什麼錯誤呢,為什麼會出現這個型別的錯誤? 產生此問題的程式碼部分是什麼樣子的呢? 以
5、【資料庫技術】SQL語句中truncate,delete以及drop的區別
一、相同點 1、truncate和不帶where子句的delete、以及drop都會刪除表內的資料。 2、drop、truncate都是DDL語句(資料定義語言),執行後會自動提交。 二、不同點 1、 truncate 和 delete 只刪除資料不刪
SQL聯合查詢及SQL語句中日期格式的轉換
SQL 三表聯合查詢用法 及 如何將日期資料的格式進行轉換 SQL三表聯合查詢 如下三張表 表1–TableName1 NAME AGE amy 18 表B—Ta
客戶端提交資料給伺服器端,如果資料中帶有中文的話,有可能會出現亂碼情況
request: 如果是GET方式 程式碼轉碼 String username = request.getParameter("username"); String password = request.getParameter("password"); String use
SQL語句中count(1),count(*)和count(field)區別
最近使用count函式比較多,當要統計的數量比較大時,發現count(*)花費的時間比較多,相對來說count(1)花費的時間比較少。 查了一些文件有以下的說法: 如果你的資料表沒有主鍵,那麼count(1)比count(*)快 如果有主鍵的話,那主鍵(聯
sql語句中的子查詢
一、子查詢分類: 1.獨立子查詢:子查詢語句可以獨立查詢 2.相關子查詢: 獨立子查詢:子查詢可以獨立執行。 相關子查詢: 子查詢中引用了父查詢的結果,不可以獨立執行。 所有查詢都可以用
sql語句中有insert然後有個[email protected]@identity,該怎麼執行
@@identity是表示的是最近一次向具有identity屬性(即自增列)的表插入資料時對應的自增列的值,是系統定義的全域性變數。 一般系統定義的全域性變數都是以@@開頭,使用者自定義變數以@開頭。select @@identity,在access或sqlserver中
Python----使用正則re查詢文字中特定中文字串,去除重複的資料,取有某個特定字串的前幾位與後幾位數據(適應web回包查詢)
Python----使用正則re查詢文字中特定中文字串例子1:指令碼檔案[email protected]:~/python/dinpay# cat t.py #coding:utf-8 import re source = "s2f程式設計師雜誌一2d3程式
SQL語句中模糊查詢的下劃線的問題
因為在SQL中下劃線也當作了單個的萬用字元,所以返回的結果是: select * from T_MQlog where F_Type like 'Ticket[_]%' select * from T_MQlog where F_Type like 'Ticket/_%'