
當我們在談論Flink的時候,我們到底在談論些什麼
前言
目前每當我們聊到當下熱門的計算引擎的時候,無一例外地會聊到Apache Flink:當下非常火熱的流處理計算框架。更是有人拿它和Spark做對比,到底哪個才是現今最好的計算引擎。當然這個已經不是本文所要闡述的主題啦。老實話,筆者本人做的比較多的還是儲存領域,對計算領域的知識不敢說是內行。最近也是抽空學習了下Flink的一些概念體系,來分享分享筆者的一個學習心得吧。
Apache Flink到底是什麼
Apache Flink是一個計算框架,更準確地來說,它是一個處理有界/無界資料流的計算處理框架。類似於Apache Spark框架,它的計算處理過程也是在記憶體中做加速計算的。
有界、無界資料流
在Flink的流處理過程中,我們會經常提到有界,無界的資料流概念。那麼什麼叫做有界/無界的資料流呢?
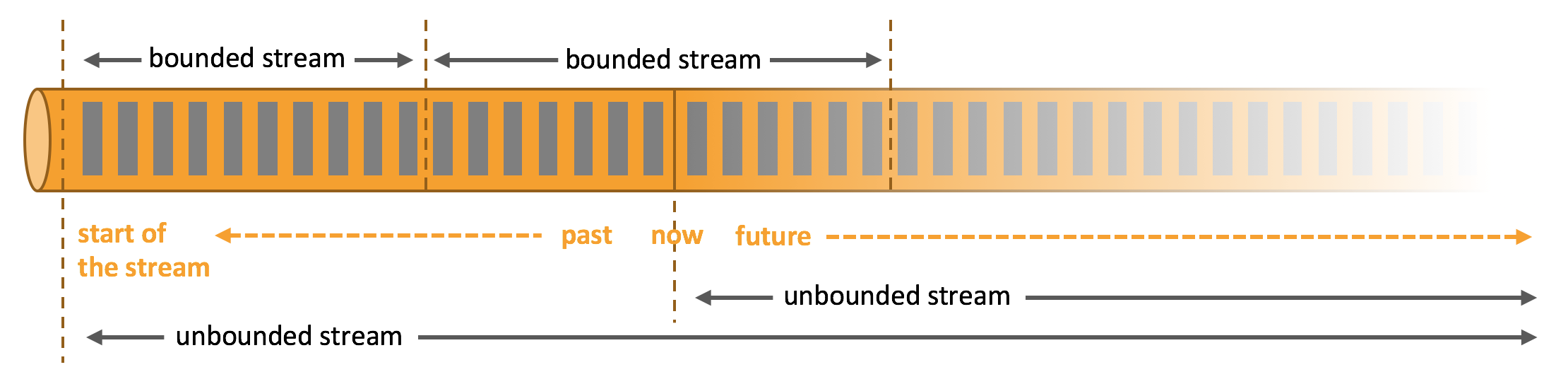
無界資料流(Bounded Stream):一個數據流,擁有開始而沒有結尾的定義,我們稱這種資料流為無界資料流。這種資料流一旦產生,就不會停止,而且需要被連續不斷地被處理。
有界資料流(Unbounded Stream):一個“有頭有尾”的資料流。在有界資料流中,有序並不是一個必須的要求。因為當我們接受到一批資料後,還是可以對其做排序的。作為一個有頭有尾的資料流,我們可以把它理解為一段有固定大小的資料集合,那麼對於有界資料流的處理來說,它完全可以類似於我們平常所說的批處理。
在一段流資料中,有界和無界資料流的概念如下圖所示:
Flink記憶體加速處理優化
和Spark類似,Flink同樣利用記憶體來進行計算過程的加速,進一步地保證資料計算的低延時性。另外,為了保證Flink錯誤恢復的一致性,Flink將一些狀態資料進行了持久化外部儲存的操作(定期checkpoint操作),如下圖所示。
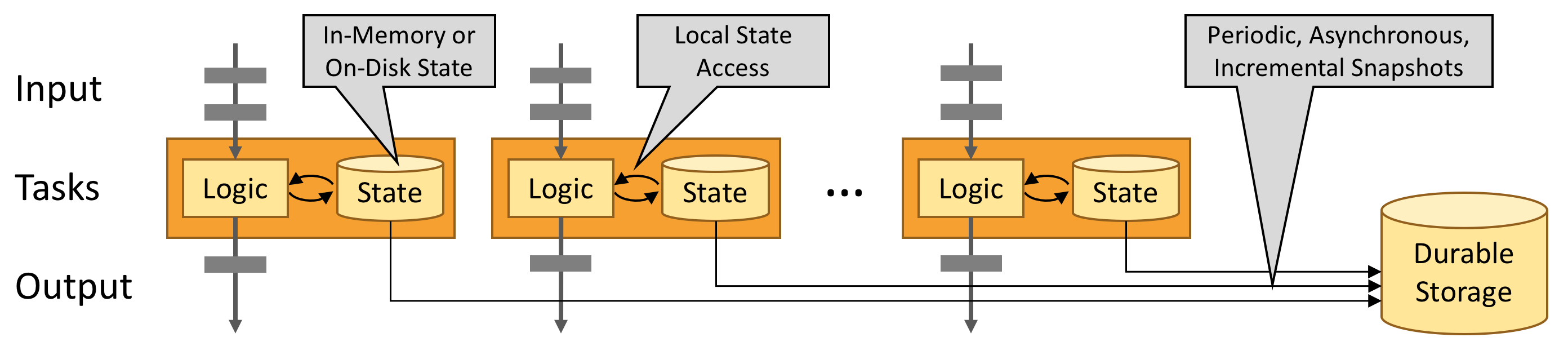
Flink的狀態處理
為了保證流計算任務的失敗恢復,Flink內部對這塊做了很多的工作,包括可插拔的狀態後端儲存,Exactly-Once語義保證的checkpoint恢復,支援大規模量級的狀態儲存。
Flink的資料流模型
下面我們來深入Flink框架內部,對內部的資料流模型做進一步地瞭解。
在資料處理的抽象層面,Flink內部實現了4個層級的抽象,供使用者使用選擇,如下圖所示:
不同層級對應的使用方法的操作抽象程度各為不同,比如越低層級的操作方法,使用粒度可以做到做精細,但是使用起來不是很方面,學習成本相應也會較高。由比如說最高級別的SQL級別,使用者使用起來就會很簡單,通過標準的SQL標準語句,也能輕鬆構建出Flink任務了。
Flink的流處理過程
在Flink的普通任務過程中,一般 分為3個模組:
- 資料來源頭,Source源。
- 資料處理,ProcessFunction,也可以理解為此為計算轉換過程。
- 資料結果輸出,Sink端。
圖示結果如下:

Window在Flink流處理過程中的應用
在流處理的場景中,我們經常會碰到分段彙總統計的需求,比如說分小時的pv/uv統計。Flink提供了Window視窗的概念來做這樣的處理。對於分時段的統計來說,我們可以用時間視窗來做這樣的資料處理,當然還有一種是基於記錄數的視窗。每當當前視窗過去,此視窗的計算結果值被記錄了下來,然後程式開始進行下一個視窗結果的計算。通過Flink內部設計的視窗來做這樣的運算後,就無須使用者來做時間分段的複雜邏輯控制了。至於視窗的具體實現原理,可以閱讀Flink官網對此的介紹。Flink的視窗處理效果如下所示,上面是基於時間的視窗劃分,下面是基於fixed-size的視窗,整體是自左向右的不間斷的流資料。
Flink的適用場景
相比於傳統的資料分析應用來說,採用的方式往往式批處理的,週期性的執行分析任務。而對於Flink來說,它的實時資料流的處理,能夠做到更低的延時和高的吞吐量,再加上它的checkpoint的容錯恢復機制。Flink方式的任務具有很好的穩定性。
一個典型的資料分析的使用場景,傳統方式和以Flink的計算處理方式
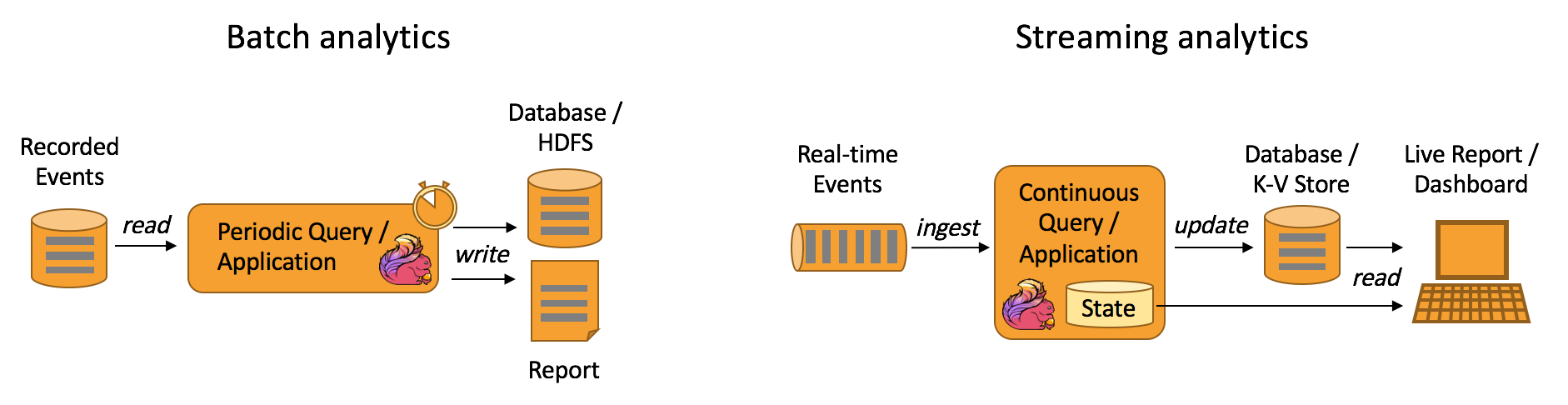
又或者,我們可以利用Flink框架低延時,高吞吐量的特點,來做一些ETL(資料抽取轉換)任務。Flink在新版本中已經能夠多型別Source源的connect,這樣的話,我們完全也利用Flink來做這樣的工作。下面是傳統方式ETL和Flink方式下的比較。
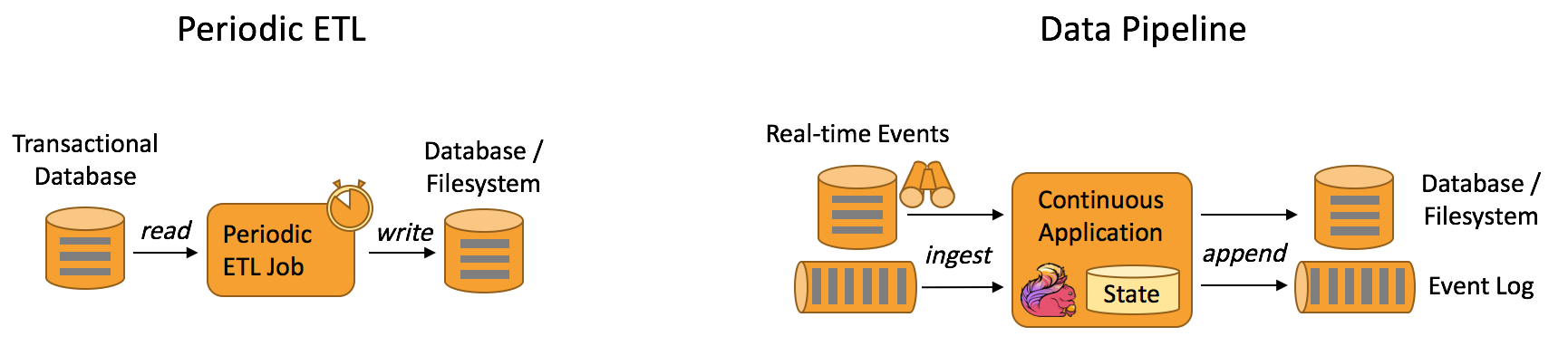
說了這麼多,筆者並不是鼓吹說Flink都是萬能的,傳統批處理任務也有它自己的合適使用的地方。只是說,Flink的出現,將會使得我們能夠更加靈活地進行技術的選型,來匹配實際的生產環境。
引用
[1].https://flink.apache.org/flink-architecture.html
[2].https://flink.apache.org/usecases.html
[3].https://ci.apache.org/projects/flink/flink-docs-release-1.7/concepts/programming-model.html