
動態網頁資訊爬取
第一篇部落格,以爬蟲開頭,雖然以前也學過爬蟲,但是時間比較久,現在又重新撿起,今天談談動態網頁資訊的爬取。 首先介紹一下爬取網頁資訊的基本思路:1.使用爬蟲請求網頁,獲取網頁的原始碼 2.解析原始碼,在原始碼中找到自己想要的資訊;3.若還有url地址,再次請求,重複1和2兩個步驟。 找到我們所要資訊的url,而有些url並不是我們所要資訊的真實url,檢視原始碼時不能找到所要的資料,這是因為這部分資訊是通過動態獲取的,下面以遊民星空的今日推薦為例,獲取資訊分類,資訊標題,資訊簡介,釋出時間,閱讀數量,評論數量,圖片路徑等路徑。url='https://www.gamersky.com/news/’
單頁資訊獲取
網頁如下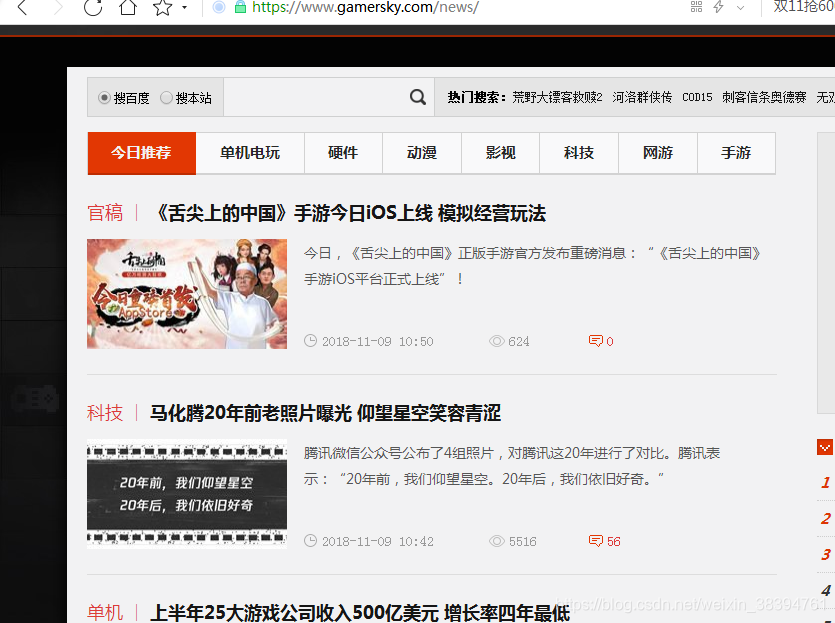
檢視網頁的原始碼,在原始碼中找到所要的所有資訊:
發現所要的資訊都在該程式碼塊中,而評論數那裡卻沒有值,說明評論數是通過動態獲取的,找到評論數真實的url.
在network中檢視網頁的情況,獲取評論數的真實連線的
js程式碼為 其中的joincount就是要獲取的評論數,id也就是連線https://cm.gamersky.com/commentapi/count?callback=jQuery18305533735619951856_1541733561188&topic_source_id=1120987%2C1120919%2C1120764%2C1120676%2C1120483%2C1120737%2C1120383%2C1120344%2C1120301%2C1120184%2C1118361%2C1100332%2C1054392&_=1541733562165中的id,因此,每一個評論數真實的url='
其中的joincount就是要獲取的評論數,id也就是連線https://cm.gamersky.com/commentapi/count?callback=jQuery18305533735619951856_1541733561188&topic_source_id=1120987%2C1120919%2C1120764%2C1120676%2C1120483%2C1120737%2C1120383%2C1120344%2C1120301%2C1120184%2C1118361%2C1100332%2C1054392&_=1541733562165中的id,因此,每一個評論數真實的url='
現在的目的就是獲取id,而id從原始碼中的data-sid屬性中便可以獲得。 找到所要獲取的資訊後,便是請求網頁,解析程式碼了,下面使用lxml解析,其程式碼如下:
from lxml import etree import requests #獲取單頁的資訊 def one_page_info(): url='https://www.gamersky.com/news/' headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} r=requests.get(url,headers=headers) r_text=r.content.decode('utf-8') html=etree.HTML(r_text) #解析原始碼 #所有資訊都在div,屬性為Mid2L_con block的li標籤中,獲取所有li標籤 all_li=html.xpath('//div[@class="Mid2L_con block"]/ul[@class="pictxt contentpaging"]/li') all_inf=[] #遍歷li標籤,獲取每一個li標籤中的資訊 for one_li in all_li: one_type=one_li.xpath('./div[1]/a[1]/text()')[0]#資訊型別 one_name=one_li.xpath('./div[1]/a[2]/text()')[0]#資訊名 one_info=one_li.xpath('string(./div[3]/div[1]/text())') one_info=str(one_info).replace('\n','')#資訊資訊,其中有些資訊換行了,將換行符替換 one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]#釋出時間 one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]#閱讀數量 one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]#獲取id comment_url='https://cm.gamersky.com/commentapi/count?callback=jQuery183006329225718227227_1541342483946&topic_source_id='+one_id #獲取評論數 r_comment=requests.get(comment_url,headers=headers) r_text=r_comment.text one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount'] one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0] all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img}) return all_inf #儲存檔案 def save_to_file(all_info): with open("D:/gamersky.txt",'a',encoding='utf-8') as file: for o in all_info: file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
執行程式碼後,獲得的資訊如下:
 下面爬取多頁的資訊
下面爬取多頁的資訊
翻頁資訊獲取
步驟還是跟單頁一樣,當我們翻頁的時候,發現網址並沒有改變
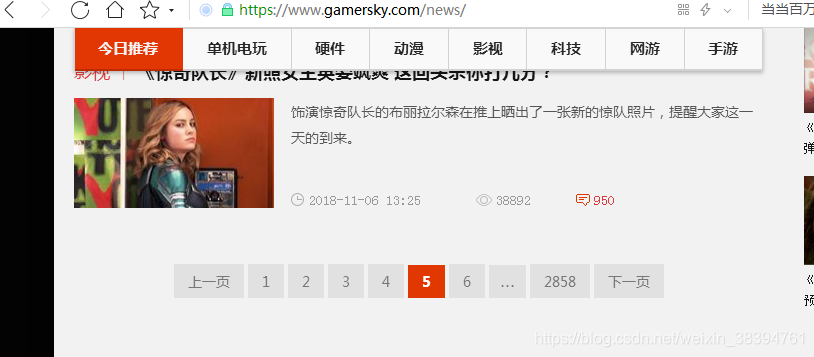
而檢視原始碼發現還是第一頁的資訊,因此多頁的時候也是通過動態獲取的,檢視network找到資訊的真正連結。

接下來就是請求各頁的網頁,得到各頁的li標籤,然後與單頁獲取方式一樣。 程式碼:
#爬取多頁動態網頁,找出url之間的規則,傳遞所要爬取的頁
def more_page_info(page):
now_time=str(time.time()).replace('.','')[0:13]
#每頁想要獲取資訊的url
page_url="https://db2.gamersky.com/LabelJsonpAjax.aspx?callback=jQuery18308577910192677702_1541300651736&jsondata=%7B%22type%22%3A%22updatenodelabel%22%2C%22isCache%22%3Atrue%2C%22cacheTime%22%3A60%2C%22nodeId%22%3A%2211007%22%2C%22isNodeId%22%3A%22true%22%2C%22page%22%3A"+str(page)+"%7D&_="+now_time
headers={
"referer": "https://www.gamersky.com/news/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
r=requests.get(page_url,headers=headers)
html=json.loads(r.text[41:-2])['body']#將json字串轉換為字典
r_text=etree.HTML(html)
all_li=r_text.xpath('//li')#獲取所有的li標籤
all_inf=[]
for one_li in all_li:
one_type=one_li.xpath('./div[1]/a[1]/text()')[0]
one_name=one_li.xpath('./div[1]/a[2]/text()')[0]
one_info=one_li.xpath('string(./div[3]/div[1]/text())')
one_info=str(one_info).replace('\n','')
one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]
one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]
one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]
comment_url='https://cm.gamersky.com/commentapi/count?callback=jQuery183006329225718227227_1541342483946&topic_source_id='+one_id
#獲取評論數
r_comment=requests.get(comment_url,headers=headers)
r_text=r_comment.text
one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount']
one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0]
all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img})
return all_inf
def save_to_file(all_info):
with open("D:/gamersky.txt",'a',encoding='utf-8') as file:
for o in all_info:
file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
獲取前3頁資訊
for page in range(1,4):
info=more_page_info(page)
save_to_file(info)
print('第%d頁下載完成'%page)
總結,要看需要的資訊是靜態載入還是動態載入的,判斷是否是動態網頁的簡單方式是看在原始碼中能否找到想獲取的資訊。動態網頁關鍵是找到想要資訊的真實url,對比每頁的url,找出其中的規律並傳遞引數,若引數是其他動態url獲取的,那就要再找引數資訊的url,然後按單個資訊獲取。