hbase協處理器與二級索引
一、協處理器—Coprocessor
1、 起源
Hbase 作為列族資料庫最經常被人詬病的特性包括:無法輕易建立“二級索引”,難以執 行求和、計數、排序等操作。比如,在舊版本的(<0.92)Hbase 中,統計資料表的總行數,需 要使用 Counter 方法,執行一次 MapReduce Job 才能得到。雖然 HBase 在資料儲存層中整合 了 MapReduce,能夠有效用於資料表的分散式計算。然而在很多情況下,做一些簡單的相 加或者聚合計算的時候, 如果直接將計算過程放置在 server 端,能夠減少通訊開銷,從而獲 得很好的效能提升。於是, HBase 在 0.92 之後引入了協處理器(coprocessors),實現一些激動 人心的新特性:能夠輕易建立二次索引、複雜過濾器(謂詞下推)以及訪問控制等。
2、協處理器有兩種: observer 和 endpoint
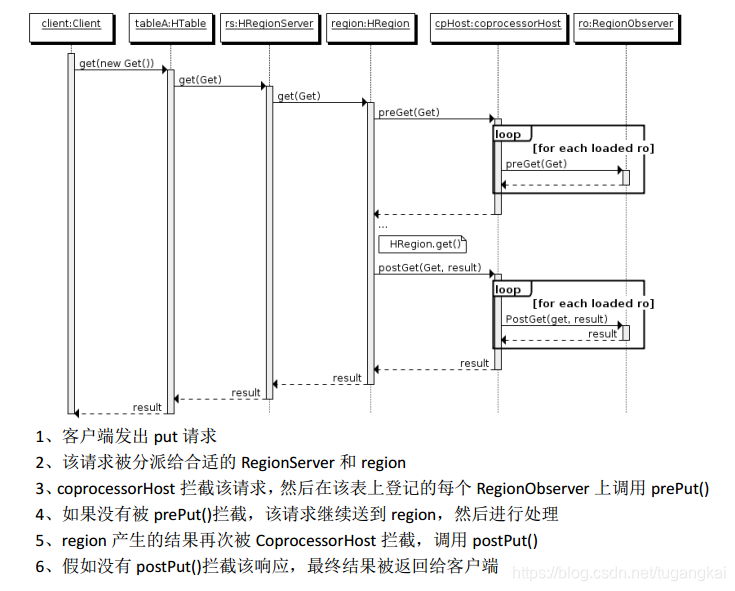
(1) Observer 類似於傳統資料庫中的觸發器,當發生某些事件的時候這類協處理器會被 Server 端呼叫。Observer Coprocessor 就是一些散佈在 HBase Server 端程式碼中的 hook 鉤子, 在固定的事件發生時被呼叫。比如: put 操作之前有鉤子函式 prePut,該函式在 put 操作 執行前會被 Region Server 呼叫;在 put 操作之後則有 postPut 鉤子函式
以 HBase0.92 版本為例,它提供了三種觀察者介面: ● RegionObserver:提供客戶端的資料操縱事件鉤子: Get、 Put、 Delete、 Scan 等。 ● WALObserver:提供 WAL 相關操作鉤子。 ● MasterObserver:提供 DDL-型別的操作鉤子。如建立、刪除、修改資料表等。 到 0.96 版本又新增一個 RegionServerObserver
下圖是以 RegionObserver 為例子講解 Observer 這種協處理器的原理:
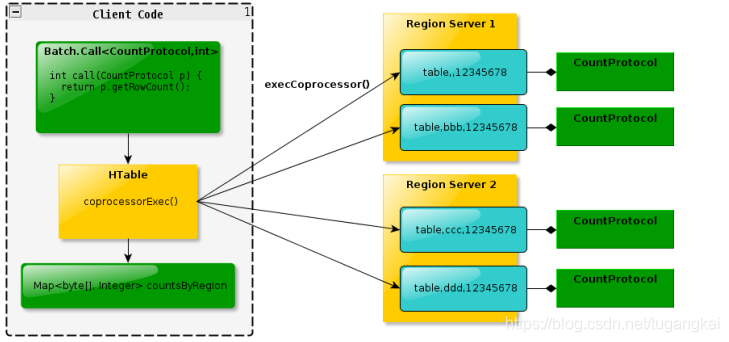
max 聚合操作,就必須進行全表掃描,在客戶端程式碼內遍歷掃描結果,並執行求最大值的 操作。這樣的方法無法利用底層叢集的併發能力,而將所有計算都集中到 Client 端統一執 行,勢必效率低下。利用 Coprocessor,使用者可以將求最大值的程式碼部署到 HBase Server 端,
HBase 將利用底層 cluster 的多個節點併發執行求最大值的操作。即在每個 Region 範圍內 執行求最大值的程式碼,將每個 Region 的最大值在 Region Server 端計算出,僅僅將該 max 值返回給客戶端。在客戶端進一步將多個 Region 的最大值進一步處理而找到其中的最大值。
這樣整體的執行效率就會提高很多
下圖是 EndPoint 的工作原理:
Observer 允許叢集在正常的客戶端操作過程中可以有不同的行為表現 Endpoint 允許擴充套件叢集的能力,對客戶端應用開放新的運算命令 observer 類似於 RDBMS 中的觸發器,主要在服務端工作 endpoint 類似於 RDBMS 中的儲存過程,主要在 client 端工作 observer 可以實現許可權管理、優先順序設定、監控、 ddl 控制、 二級索引等功能 endpoint 可以實現 min、 max、 avg、 sum、 distinct、 group by 等功能
二、協處理器載入方式
協處理器的載入方式有兩種,我們稱之為靜態載入方式( Static Load) 和動態載入方式 ( Dynamic Load)。 靜態載入的協處理器稱之為 System Coprocessor,動態載入的協處理器稱 之為 Table Coprocessor
1、靜態載入
通過修改 hbase-site.xml 這個檔案來實現, 啟動全域性 aggregation,能過操縱所有的表上 的資料。只需要新增如下程式碼:
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>
為所有 table 載入了一個 cp class,可以用” ,”分割載入多個 class
2、動態載入
啟用表 aggregation,只對特定的表生效。通過 HBase Shell 來實現。 disable 指定表。 hbase> disable ‘mytable’ 新增 aggregation hbase> alter ‘mytable’, METHOD => ‘table_att’,‘coprocessor’=> ‘|org.apache.Hadoop.hbase.coprocessor.AggregateImplementation||’ 重啟指定表 hbase> enable ‘mytable’
3、協處理器解除安裝

row key 在 HBase 中是以 B+ tree 結構化有序儲存的,所以 scan 起來會比較效率。單表以 row key 儲存索引, column value 儲存 id 值或其他資料 ,這就是 Hbase 索引表的結構。
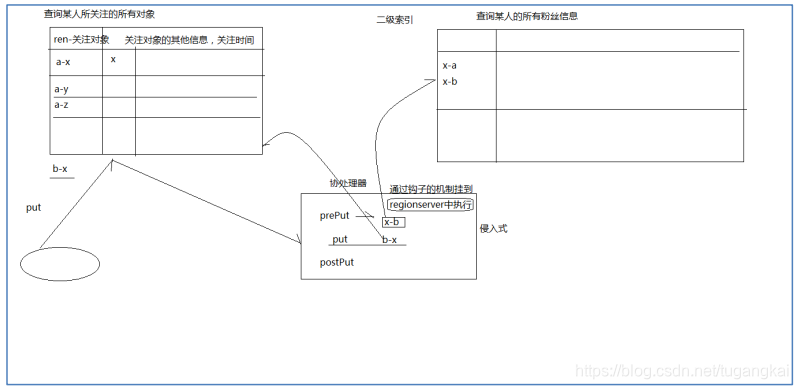
由於 HBase 本身沒有二級索引( Secondary Index)機制,基於索引檢索資料只能單純地依靠 RowKey,為了能支援多條件查詢,開發者需要將所有可能作為查詢條件的欄位一一拼接到 RowKey 中,這是 HBase 開發中極為常見的做法
在社交類應用中,經常需要快速檢索各使用者的關注列表 guanzhu,同時,又需要反向檢索各 種戶的粉絲列表 fensi,為了實現這個需求,最佳實踐是建立兩張互為反向的表:

實現步驟: (1)程式碼:`
package com.ghgj.hbase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
public class TestCoprocessor extends BaseRegionObserver {
static Configuration config = HBaseConfiguration.create();
static HTable table = null;
static{
config.set("hbase.zookeeper.quorum",
"hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181");
try {
table = new HTable(config, "guanzhu");
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void prePut(ObserverContext<RegionCoprocessorEnvironment> e,
Put put, WALEdit edit, Durability durability) throws IOException {
// super.prePut(e, put, edit, durability);
byte[] row = put.getRow();
Cell cell = put.get("f1".getBytes(), "from".getBytes()).get(0);
Put putIndex = new
Put(cell.getValueArray(),cell.getValueOffset(),cell.getValueLength());
putIndex.addColumn("f1".getBytes(), "from".getBytes(), row);
table.put(putIndex);
table.close();
}
}
(2)打成 jar 包( cppp.jar),上傳到 hdfs 中的 hbasecp 目錄下
hadoop fs -put cppp.jar /hbasecp
(3)建hbase表,按以下順序操作

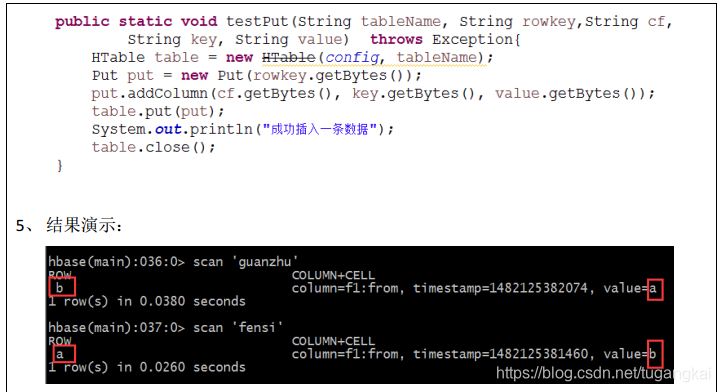
(4)現在插入資料進行驗證,命令列和程式碼都可以
testput("fensi","c","f1","from","b");