
你看到的真的是真實的麼?你眼中的 const 和 auto 關鍵字
編譯環境:VS 2013
所謂眼見為實,耳聽為虛,然鵝,你可能也會被事情的表面矇蔽了雙眼,不信你看下面的程式碼:
#include <iostream> #include <cstdlib> int main(void) { const int a = 10; int * pa = (int *)&a; *pa = 100; std::cout << a << std::endl; std::cout << *pa << std::endl; system("pause"); return 0; }
嗯…首先說明一下,這段程式碼編譯沒有問題,那麼會輸出什麼呢?
A: 10 10
B: 10 100
C: 100 10
D: 100 100
好,排列組合了一下,選一個吧!
A? B? C? D?
接下來,就是見證奇蹟的時刻:
 答案是 B 選項,為什麼呢?
答案是 B 選項,為什麼呢?
一、巨集和 const
我們先回顧一下 C 語言中的巨集定義和巨集函式
1. 巨集定義和巨集函式
我們說,如果某個常量在程式碼中多次出現,並且經常修改,那我們可以考慮在程式碼中定義一個巨集,這樣每次更換的時候,只需要更換這個巨集的值,其餘地方就跟著替換了,那這是一個好方法啊,巨集的定義方式如下:
#define DEFINE_NAME DEFINE_VALUE
#define MAX_SIZE 1024
當然對一些常用的簡單函式也是可以把它定義為巨集函式的
例如:#define ADD(left, right) ((left) + (right))
巨集在程式碼預處理階段,進行全文替換,程式碼中凡是有該巨集的地方,全部替換為該巨集的值。
那這樣做的好處:
- 提高了程式碼的複用性
- 提高效能
為什麼說提高了效能呢?我們知道,呼叫一個函式是要壓棧,形成該函式的棧幀結構的,這肯定是要花費時間的,是有開銷的,這也是為什麼遞迴函式執行很慢的原因,而巨集只是在程式碼中進行了替換,就不會有函式呼叫和壓棧開銷了,自然就提高了效能。 但這樣做也有壞處:
- 沒有引數檢驗
- 沒法除錯
- 程式碼膨脹
- 副作用
其他都好理解,這個副作用怎麼理解呢? 我們看看下面一段程式碼:
#include <iostream>
#include <cstdlib>
#define CMP(left, right) (((left) > (right)) ? (left) : (right))
int main(void)
{
int a = 20;
int b = 10;
int c = 0;
c = CMP(++a, b);
std::cout << a << std::endl;
system("pause");
return 0;
}
這段程式碼輸出什麼呢?
10? 20? 21?
我們來看看結果:
 22?如果你大跌眼鏡了,就說明你沒有理解我們剛剛說的巨集替換
其實程式碼已經變成這樣了
22?如果你大跌眼鏡了,就說明你沒有理解我們剛剛說的巨集替換
其實程式碼已經變成這樣了
c = (((++a) > (b)) ? (++a) : (b))
自增運算執行了兩次,自然就是 22 了。
這就是巨集的副作用,加再多括號都避免不了的。
2. C 語言中的 const 關鍵字
我們說,我們不想修改某個變數的值,可以用const 來修飾這個變數,使這個變數具有常屬性。
如 const int a = 10;
這樣我們就無法直接修改變數 a 的值了;
但是我們卻可以通過指標的方式間接修改 a 的值:
int *pa = &a;
*pa = 20;
這樣就把 a 的值修改為 20 了,所以C語言中的 const 關鍵字是個假的。
二、C++ 中的 const 關鍵字和行內函數
1. C++ 中的 const
其實C語言中的巨集是一個非常不錯的想法,加上 C++ 完全相容 C 的特性,於是我們在 C++ 語言中對 const 有了新的含義,那就是負載了巨集的特性,在C++中,const 修飾的變數就是一個常量,並且具有巨集的特性。 我們回頭再看看篇首的程式碼… 其實是程式在編譯期間,把所有出現 a 的地方替換為 10 了,第一個輸出的就是10,我們通過指標的方式,還是間接修改了變數 a 所佔地址空間的內容,也就是說 a 變數地址空間裡存的是 100,而不是 10 了。我們替換的早,a 打印出來是 10,修改地址空間裡的值是在程式執行期間修改的,*pa 打印出來的就是 100 了。
2. 行內函數
建議內聯!建議內聯!!建議內聯!!! 我們說 C 語言在用巨集函式的時候直接替換,不進行引數檢驗,這使得一個非常不錯的想法有了隱患,呼叫者就要考慮副作用了,這無疑會讓人腦殼疼。 於是我們在 C++ 中引入了行內函數的概念:
- 有函式的結構,卻不具備函式的性質
- 不是在呼叫時發生控制轉移 而是在編譯時將函式體嵌入在每一個呼叫處 類似於巨集替換,使函式體替換呼叫處的函式名
- 用關鍵字inline修飾
- 能否形成行內函數,需要## 標題看編譯器對該函式定義的具體處理 所以說,我們只是建議內聯,給編譯器提個建議,建議把這個函式設定為行內函數,所以不是加了 inline 關鍵字的函式都能成為行內函數。
- 內聯擴充套件是用來消除函式呼叫時的時間開銷
- 是一種用空間換時間的做法 所以程式碼很長或者有迴圈/遞迴的函式不適宜作為行內函數
三、C++11 新規定的 auto 關鍵字
1. C++11 標準出來之前
C/C++中 auto 關鍵字的含義是:使用 auto 修飾的變數,是具有自動儲存器的區域性變數,但遺憾的是一直沒有人去使用它,為什麼呢?我們想,區域性變數開闢記憶體是在棧上,函式呼叫結束,棧自動銷燬,那我還要這雞肋的關鍵字幹哈?我又不傻!!
2. C++11 中
標準委員會賦予 auto 全新的含義: auto 宣告的變數必須由編譯器在編譯時期推導而得 什麼意思呢? 就是說定義一個變數,不用給出明確地型別,auto 就像一個“佔位符”一樣,編譯器在編譯階段會根據需要初始化表示式來推導 auto 的實際型別。
#include <iostream>
#include <cstdlib>
int TestAuto()
{
return 0;
}
int main(void)
{
int a = 10;
auto b = 10;
auto c = a;
auto ch = 'c';
auto d = 3.14;
auto ret = TestAuto();
std::cout << "The type of a is "<< typeid(a).name() << std::endl;
std::cout << "The type of b is " << typeid(b).name() << std::endl;
std::cout << "The type of c is " << typeid(c).name() << std::endl;
std::cout << "The type of ch is " << typeid(ch).name() << std::endl;
std::cout << "The type of d is " << typeid(d).name() << std::endl;
std::cout << "The type of ret is " << typeid(ret).name() << std::endl;
system("pause");
return 0;
}
編譯執行:
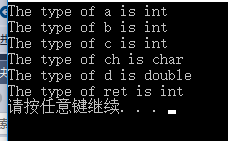 我們通過 typeid().name() 打印出來了變數的型別
看來這個 auto 確實可以推匯出變數的型別
下面我們再來看一下 auto 更多的使用規則:
我們通過 typeid().name() 打印出來了變數的型別
看來這個 auto 確實可以推匯出變數的型別
下面我們再來看一下 auto 更多的使用規則:
3. auto 的使用規則
- auto 與指標和引用結合起來使用 用 auto 宣告指標型別時,用 auto 和 auto* 沒有任何區別 但是!!!用 auto 宣告引用型別時則必須加 &
#include <iostream>
#include <cstdlib>
int main(void)
{
int x = 10;
auto a = &x;
auto *b = &x;
auto &c = x;
std::cout << "The type of a is "<< typeid(a).name() << std::endl;
std::cout << "The type of b is " << typeid(b).name() << std::endl;
std::cout << "The type of c is " << typeid(c).name() << std::endl;
*a = 20;
std::cout << "x = " << x << std::endl;
*b = 30;
std::cout << "x = " << x << std::endl;
c = 40;
std::cout << "x = " << x << std::endl;
system("pause");
return 0;
}
編譯執行:
 三者比較剛好證實了我們的結論!
三者比較剛好證實了我們的結論!
- 在同一行定義多個變數 這些變數必須是同類型的,否則編譯器報錯 編譯器只對第一個型別進行推導,然後用推匯出來的型別定義其他變數。
4. auto 不能推導的場景
- auto 不能作為函式的引數
- auto 不能直接用來宣告陣列
好,我們瞭解了 auto 這個關鍵字,然後發現,它還是個雞肋!!! 要是 auto 只有這麼點功能,標準委員會也不會給他重新賦予新含義了 它的魅力在於:
四、C++11 的基於範圍for迴圈
1. 範圍 for 的語法
for (declaration : expression)
statement
- expression 部分 是一個物件,用於表示一個序列
- declaration 負責定義一個變數,該變數將被用於訪問序列中的基礎元素 這個變數根據自己需要,決定是否定義為引用
- 每次迭代,declaration 部分的變數會被初始化為 expression部分的下一個元素值
例如,遍歷一個數組:
#include <iostream>
#include <cstdlib>
int main(void)
{
int array[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
// 傳統遍歷陣列的方法
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
{
array[i] *= 2;
}
// 或者
for (int *p = array; p < array + sizeof(array) / sizeof(array[0]); ++p)
{
std::cout << *p << " ";
}
std::cout << std::endl;
// C++11 的範圍 for
for (auto e : array)
{
std::cout << e << " ";
}
std::cout << std::endl;
system("pause");
return 0;
}
這樣的 for 迴圈,對於遍歷一個有範圍的集合是不是很方便呢?還不用判斷邊界條件!!!
2. 範圍 for 的使用條件
-
for 迴圈迭代的範圍必須是確定的 對陣列而言,範圍就是陣列中的第一個元素到最後一個元素 對於類而言,這個類必須提供 begin 和 end 方法,begin 和 end 就是 for 迴圈迭代的範圍!
-
迭代的物件要實現 ++ 和 == 的操作
五、C++11 的指標空值 nullptr
1. C++98 中的指標空值
對指標這個東西,我們是一點都不陌生,在定義一個指標的時候,我們常常有這樣的操作:
int *p = NULL;
或者
int *p = 0;
因為使用未經初始化的指標是引發執行時錯誤的一大原因
對於常量 NULL
有的標頭檔案這樣定義: #define NULL 0
有的標頭檔案這樣定義: #define NULL ((void *) 0)
2. C++11中的 nullptr
nullptr 是一種特殊型別的字面值,它可以被轉換為任意其他型別的指標型別。 我們看這樣一段程式碼:
#include <iostream>
#include <cstdlib>
void func(int a)
{
std::cout << "void func(int)" << std::endl;
}
void func(int *p)
{
std::cout << "void func(int *)" << std::endl;
}
int main(void)
{
func(0);
func(NULL);
func(nullptr);
system("pause");
return 0;
}
編譯執行:
 通過這個過載函式我們看到,對 NULL 的處理本應該是引數為指標的 func 函式,卻變成引數為整型的 func 函式,而實參為 nullptr 成功呼叫引數為指標的 func 函式。
在新標準下,現在的 C++ 程式建議使用 nullptr ,同時儘量避免使用 NULL。
通過這個過載函式我們看到,對 NULL 的處理本應該是引數為指標的 func 函式,卻變成引數為整型的 func 函式,而實參為 nullptr 成功呼叫引數為指標的 func 函式。
在新標準下,現在的 C++ 程式建議使用 nullptr ,同時儘量避免使用 NULL。
3. decltype
我們再來看一個 C++11 新標準引入的第二個型別說明符 decltype
,它的作用是選擇並返回運算元的資料型別。
編譯器分析表示式並得到它的型別,卻不實際計算表示式的值。
decltype(f()) sum = x; // sum 的型別就是函式 f 的返回型別
4. nullptr_t
nullptr 是有型別的,其型別為 nullptr_t,僅僅可以被隱式轉換為指標型別。
typedef decltype(nullptr) nullptr_t;