
python pandas.map apply applymap 三種方法小結
pandas包的apply方法表示對DataFrame中的每一列元素應用函式。比如:
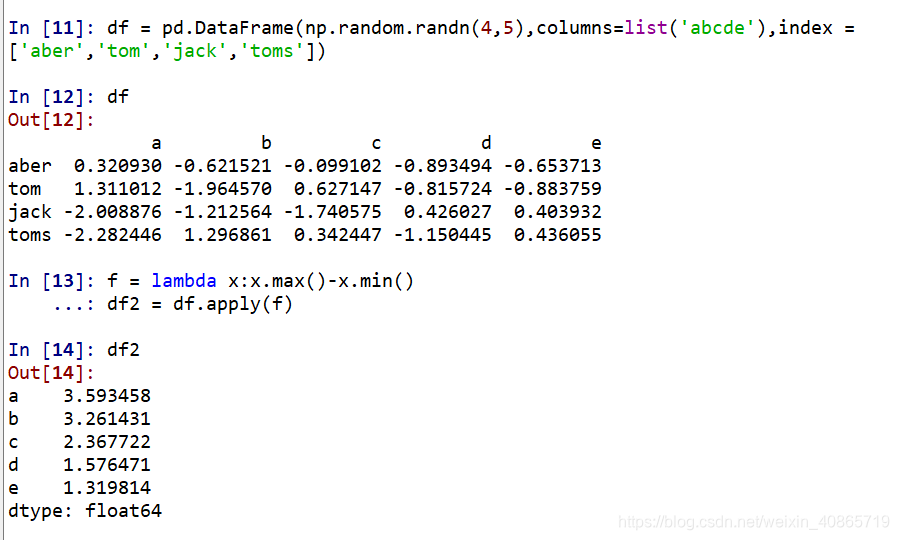
同時也可以在行方向做運算:

map方法:這裡的map方法有點像mapreduce中的map()方法,具體的過程是將資料集中的每一個元素進行函式處理,如下:
|
df['a'] Out[17]: aber 0.320930 tom 1.311012 jack -2.008876 toms -2.282446 Name: a, dtype: float64 add = lambda x:x+1 df['a'].map(add) Out[19]: aber 1.320930 tom 2.311012 jack -1.008876 toms -1.282446 Name: a, dtype: float64 |
既然有map() 我們不妨看一看有沒有reduce(),他的效果又是怎樣的:reduce:
|
reduceData = df['a'].reduce(add) 報錯:'Series' object has no attribute 'reduce' 再次嘗試: df['a'] Out[17]: aber 0.320930 tom 1.311012 jack -2.008876 toms -2.282446 Name: a, dtype: float64 f = lambda x,y:x+y reduceData = functools.reduce(f,df['a']) reduceData Out[28]: -2.659379404636298 可以得到,reduce在pandas中沒有,在functools包中,主要的操作過程是: X Y 1 2 3 3 6 4 10 5 這樣計算的,上面的過程是 f = lambdas x,y :x+y 的過程 |
最後一個applymap的用法:
format = lambda x:'%.2f'%x
df.applymap(format) Out[32]: a b c d e aber 0.32 -0.62 -0.10 -0.89 -0.65 tom 1.31 -1.96 0.63 -0.82 -0.88 jack -2.01 -1.21 -1.74 0.43 0.40 toms -2.28 1.30 0.34 -1.15 0.44
可以得出:map是以行或者列為單位,series的角度下進行操作,或加或減等等隻影響一部分資料
apply是以行或者列為單位在dataframe的角度下對行或列的範圍裡進行操作,預設為列,
applymap是對整個dataframe不論行或者列進行操作。
reduce是在functools包中的一個簡單的聚合函式
最後有一個小實驗:
已知:f = lambda x:x.max()-x.min()
add = lambda x:x+1
f = lambda x,y:x+y
format = lambda x:'%.2f'%x
df.applymap(add) 正常,為資料框的值加1,
df.apply(add) 正常,為資料框的值加1,
apply(format) 不正常,程式報錯
df.applymap(f) 不正常
到底是為什麼,留下來再試