
大資料實時分析架構
flume+kafka+flink+hbase 實時分析架構##
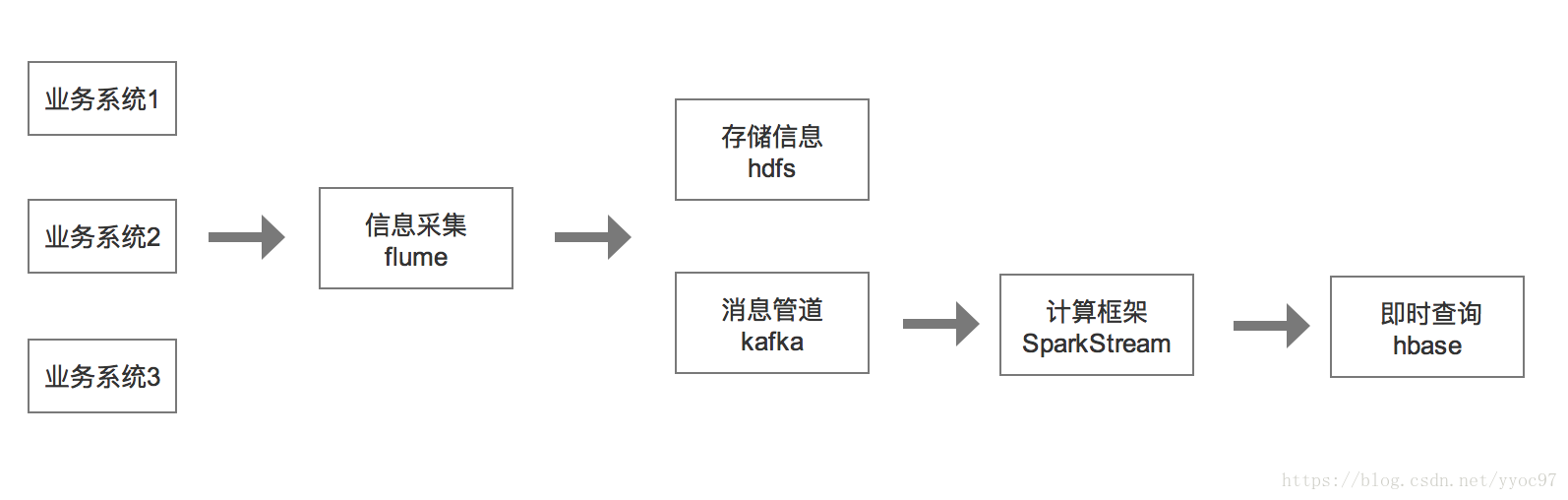
- 整體架構
各個業務系統的訊息源多種多樣,使用 flume 作為訊息的採集端,有一定的擴充套件性,採集的訊息發往hdfs直接儲存和訊息管道進行實時計算。中間傳輸層採用Kakfa,能夠支撐海量資料的資料傳遞。將訊息持久化到磁碟中,並對訊息建立了備份保證了資料的安全。Kafka在保證了較高的處理速度的同時,又能保證資料處理的低延遲和資料的零丟失。計算框架多采用高吞吐的SparkStreaming,還擁有Spark生態圈豐富的元件,最後將處理好的資料寫入Hbase方便即時查詢。
- dome
後續補充
相關推薦
大資料實時分析架構
flume+kafka+flink+hbase 實時分析架構## 整體架構 各個業務系統的訊息源多種多樣,使用 flume 作為訊息的採集端,有一定的擴充套件性,採集的訊息發往hdfs直接儲存和訊息管道進行實時計算。中間傳輸層採用Kakfa,能夠支撐海量資料的資料傳
[大資料專案]-0016-基於Spark2.x新聞網大資料實時分析視覺化系統
2018最新最全大資料技術、專案視訊。整套視訊,非那種淘寶雜七雜八網上能免費找到拼湊的亂八七糟的幾年前的不成體系浪費咱們寶貴時間的垃圾,詳細內容如下,視訊高清不加密,需要的聯絡QQ:3164282908(加Q註明51CTO)。 課程介紹 本專案基於某新聞網使用者日誌分析系統進行講解
比Hive快800倍!大資料實時分析領域黑馬開源ClickHouse
一. 概述 隨著物聯網 IOT 時代的來臨,IOT 裝置感知和報警儲存的資料越來越大,有用的價值資料需要資料分析師去分析。大資料分析成了非常重要的環節。當然近兩年開啟的開源大潮,為大資料分析工程師提供了十分富餘的工具。但這同時也增加了開發者選擇合適的工具的難度,尤其對於新入行的開發者來說。學習成
深度解析 Twitter Heron 大資料實時分析系統
所有的老的生產環境的topology已經執行在Heron上, 每天大概處理幾十T的資料, billions of訊息 為什麼要重新設計Heron: 【題外話】這裡完全引用作者吐槽的問題, 不少問題,其實JStorm已經解決 (1)debug-ability 很差, 出現問題,很難發現 1.1 多個t
使用者訪問session分析的基礎資料結構及大資料的基本架構
使用者訪問session分析模組 使用者訪問session介紹: 使用者在電商網站上,通常會有很多的點選行為: 首先通常都是進入首頁; 然後可能點選首頁上的一些商品; 點選首頁上的一些品類; 隨時在搜尋框裡面搜尋關鍵詞; 將一些
大資料實時階段_Day05_日誌分析
課程名稱: 日誌監控告警系統 課程目標: 1、 掌握Storm程式設計的應用場景及程式設計模型 2、 掌握Storm開發生態圈各知識點 3、 掌握簡訊和郵件告警功能 課程大綱: 1、 背景知識 2、 需求分析 3、 功能分析 4、 架構設計 5、 程式碼開發 點
六大主流大資料採集平臺架構分析
作者:HollyMike 隨著大資料越來越被重視,資料採集的挑戰變的尤為突出。今天為大家介紹幾款資料採集平臺: Apache Flume、 Fluentd、 Logstash、 Chukwa 、Scribe、 Splunk Forwarder 大資料平臺與資料採集 任何完整的
騰訊雲EMR大資料實時OLAP分析案例解析
OLAP(On-Line Analytical Processing),是資料倉庫系統的主要應用形式,幫助分析人員多角度分析資料,挖掘資料價值。本文基於QQ音樂海量大資料實時分析場景,通過QQ音樂與騰訊雲EMR產品深度合作的案例解讀,還原一個不一樣的大資料雲端解決方案。 一、背景介紹 QQ音樂是騰
大資料線上分析處理和常用工具
大資料線上分析處理的特點 . 資料來源源不斷的到來; 資料需要儘快的得到處理,不能產生積壓; 處理之後的資料量依然巨大,仍然後TB級甚至PB級的資料量; 處理的結果能夠儘快的展現; 以上四個特點可以總結為資料的收集->資料的傳輸->資料的處理-&g
大資料文字分析的應用場景有哪些?
https://www.pmcaff.com/discuss/index/480966354177088?from=related&pmc_param%5Bentry_id%5D=1000000000167873 自問自答一發。之前寫過2篇相關的文章: 【資料運營】在運營中,為什麼文字分析遠比數值
從大資料角度分析plustoken
不知不覺,plustoken從5月份上線釋出到現在11月份,已經走過來小半年,但是質疑聲依舊不斷,還沒上車的依舊觀望,已經上車有的半信半疑,只有極少數的人堅定不移,一路向前。相信很多人都有看到,說plus是中國人自己搞的傳銷盤,這裡,樓主不去翻這篇帖子,僅僅從大資料的角度給大家剖析。 在
大資料實時流式處理引擎比較
從流處理的核心概念,到功能的完備性,再到周邊的生態環境,全方位對比了目前比較熱門的流處理框架:Spark,Flink,Storm和 Gearpump。結合不同的框架的設計,為大家進行深入的剖析。與此同時,從吞吐量和延時兩個方面,對各個框架進行效能評估。 主要技術點:流失資料處理,Spark,
大資料推薦系統架構
推薦系統介紹 當下,個性化推薦成了網際網路產品的標配。但是,人們對推薦該如何來做,也就是推薦技術本身,還不甚瞭解。為此,好學的你肯定在收藏著朋友圈裡流傳的相關文章,轉發著微博上的相關討論話題,甚至還會不斷奔走在各種大小行業會議之間,聽著大廠職工們講那些乾貨。我知道,這樣碎片化的吸收,增加了知識的
企業該如何做大資料的分析挖掘?這裡有一份參考指南
現如今已經進入大資料時代,各種系統、應用、活動所產生的資料浩如煙海,資料不再僅僅是企業儲存的資訊,而是成為可以從中獲取巨大商業價值的企業戰略資產。這樣背景下,如何儲存海量複雜的資料、從紛繁錯綜的資料中找到真正有價值的資料,是大資料時代企業面臨的難題。 8月18日的“UCan下午茶”杭州站,來自U
大資料角度給大家解釋一下為什麼大資料AI分析足彩是扯淡
從大資料角度給大家解釋一下為什麼大資料AI分析足彩是扯淡的:如果相同的維度,維度包括球員、場內、場外、教練組、基本面、傷病、陣容等不變,你讓兩個隊踢100萬場,那麼我們確實可以迴歸出來一個勝平負的率,請注意我指的是這些維度都不變,狂踢100萬場。實際情況呢?即使現在通過資料訓練出來了模型,告知你
大資料案例分析
摘自https://www.cnblogs.com/ShaYeBlog/p/5872113.html 一、大資料分析在商業上的應用 1、體育賽事預測 世界盃期間,谷歌、百度、微軟和高盛等公司都推出了比賽結果預測平臺。百度預測結果最為亮眼,預測全程64場比賽,準確率為67%,進入淘汰賽後準確率為94%。現
智慧工廠大資料管控分析系統
智慧工廠的發展是因為製造業是國民經濟基礎,在《中國製造2025》規劃中提出:確立以加快新一代資訊科技與製造業深度融合為主線、促進從“中國製造”向“中國智造”轉型升級,實現製造業由大變強的歷史跨越。 MES系統是一套面向製造企業車間執行層最基礎的生產資訊化管理系統,可以為企業提供包括製造資料管理、計劃排程管理
大資料崗位集合——架構師、基礎研發、平臺研發(高階、資深)上海、北京、蘇州**
我是獵頭聞慄,以下是目前最新大資料類崗位,如果有感興趣的同學歡迎及時聯絡我 電話(微信)15809212974 簡歷傳送郵箱:[email protected] 【職位1】:大資料基礎架構研發工程師 【地點】:蘇州 【公司】:思必馳——專注智慧硬體的語
Storm之——Storm+Kafka+Flume+Zookeeper+MySQL實現資料實時分析(環境搭建篇)
Storm之——Storm+Kafka+Flume+Zookeeper+MySQL實現資料實時分析(環境搭建篇) 2018年03月04日 23:05:29 冰 河 閱讀數:1602更多 所屬專欄: Hadoop生態 版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https:/
EasyScheduler大資料排程系統架構分享
EasyScheduler大資料排程系統架構分享 導語 EasyScheduler是易觀平臺自主研發的大資料分散式排程系統。主要解決資料研發ETL 錯綜複雜的依賴關係,而不能直觀監控任務健康狀態等問題。EasyScheduler以DAG流式的方式將Task組裝起來,可實時監控任務