
MySQL之索引原理和慢查詢優化
1. 索引介紹
需求:
一般的應用系統,讀寫比例在10:1左右,而且插入操作和一般的更新操作很少出現效能問題,在生產環境中,我們遇到最多的,也是最容易出問題的,還是一些複雜的查詢操作,因此對查詢語句的優化顯然是重中之重。
說起加速查詢,就不得不提到索引了。索引:
簡單的說,相當於圖書的目錄,可以幫助使用者快速的找到需要的內容.
在MySQL中也叫做“鍵”,是儲存引擎用於快速找到記錄的一種資料結構。能夠大大提高查詢效率。特別是當資料量非常大,查詢涉及多個表時,使用索引往往能使查詢速度加快成千上萬倍.
本質:
索引本質:通過不斷地縮小想要獲取資料的範圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件,也就是說,有了這種索引機制,我們可以總是用同一種查詢方式來鎖定資料。
2.索引方法
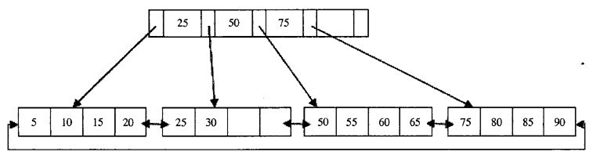
1. B+TREE 索引
B+樹是一種經典的資料結構,由平衡樹和二叉查詢樹結合產生,它是為磁碟或其它直接存取輔助裝置而設計的一種平衡查詢樹,在B+樹中,所有的記錄節點都是按鍵值大小順序存放在同一層的葉節點中,葉節點間用指標相連,構成雙向迴圈連結串列,非葉節點(根節點、枝節點)只存放鍵值,不存放實際資料。下面看一個2層B+樹的例子:
注意:通常其高度都在2~3層,查詢時可以有效減少IO次數。
系統從磁碟讀取資料到記憶體時是以磁碟塊(block)為基本單位的,位於同一磁碟塊中的資料會被一次性讀取出來,而不是按需讀取。InnoDB 儲存引擎使用頁作為資料讀取單位,頁是其磁碟管理的最小單位,預設 page 大小是 16kB
。b+樹的查詢過程
如圖所示,如果要查詢資料項30,那麼首先會把磁碟塊1由磁碟載入到記憶體,此時發生一次IO,在記憶體中用二分查詢確定30在28和65之間,鎖定磁碟塊1的P2指標,記憶體時間因為非常短(相比磁碟的IO)可以忽略不計,通過磁碟塊1的P2指標的磁碟地址把磁碟塊由磁碟載入到記憶體,發生第二次IO,30在28和35之間,鎖定當前磁碟塊的P1指標,通過指標載入磁碟塊到記憶體,發生第三次IO,同時記憶體中做二分查詢找到30,結束查詢,總計三次IO。真實的情況是,3層的b+樹可以表示上百萬的資料,如果上百萬的資料查詢只需要三次IO,效能提高將是巨大的,如果沒有索引,每個資料項都要發生一次IO,那麼總共需要百萬次的IO,顯然成本非常非常高。
強烈注意: 索引欄位要儘量的小,磁碟塊可以儲存更多的索引.
2. HASH 索引
hash就是一種(key=>value)形式的鍵值對,允許多個key對應相同的value,但不允許一個key對應多個value,為某一列或幾列建立hash索引,就會利用這一列或幾列的值通過一定的演算法計算出一個hash值,對應一行或幾行資料. hash索引可以一次定位,不需要像樹形索引那樣逐層查詢,因此具有極高的效率.
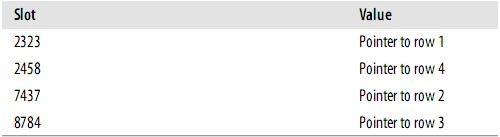
假設索引使用hash函式f( ),如下:
1 2 3 4 f('Arjen') = 2323f('Baron') = 7437f('Peter') = 8784f('Vadim') = 2458此時,索引的結構大概如下:
3.HASH與BTREE比較:

hash型別的索引:查詢單條快,範圍查詢慢 btree型別的索引:b+樹,層數越多,資料量越大,範圍查詢和隨機查詢快(innodb預設索引型別) 不同的儲存引擎支援的索引型別也不一樣 InnoDB 支援事務,支援行級別鎖定,支援 Btree、Hash 等索引,不支援Full-text 索引; MyISAM 不支援事務,支援表級別鎖定,支援 Btree、Full-text 等索引,不支援 Hash 索引; Memory 不支援事務,支援表級別鎖定,支援 Btree、Hash 等索引,不支援 Full-text 索引; NDB 支援事務,支援行級別鎖定,支援 Hash 索引,不支援 Btree、Full-text 等索引; Archive 不支援事務,支援表級別鎖定,不支援 Btree、Hash、Full-text 等索引;
三、索引型別
MySQL中常見的索引有:普通索引、唯一索引、主鍵索引、組合索引。
1.普通索引
普通索引僅有一個功能:加速查詢
建立普通索引的方式:
1.在建立表的同時新增某個欄位為普通索引
語法:create table 表名(id int not null auto_increment primary key,name char(50) ,
index 索引名(要設定索引的欄位) );
備註:一般索引名的格式為idx_+欄位名
2.單獨為表指定普通索引
語法:create index 索引名 on 表名(欄位名);
刪除索引的語法:drop index 索引名 on 表名;
查看錶中的索引:show index from 表名;

1、Table 表的名稱。 2、 Non_unique 如果索引為唯一索引,則為0,如果可以則為1。 3、 Key_name 索引的名稱 4、 Seq_in_index 索引中的列序列號,從1開始。 5、 Column_name 列名稱。 6、 Collation 列以什麼方式儲存在索引中。在MySQL中,有值‘A’(升序)或NULL(無分類)。 7、Cardinality 索引中唯一值的數目的估計值。 8、Sub_part 如果列只是被部分地編入索引,則為被編入索引的字元的數目。如果整列被編入索引,則為NULL。 9、 Packed 指示關鍵字如何被壓縮。如果沒有被壓縮,則為NULL。 10、 Null 如果列含有NULL,則含有YES。如果沒有,則該列含有NO。 11、 Index_type 用過的索引方法(BTREE, FULLTEXT, HASH, RTREE)。 12、 Comment 多種評註查看錶中的索引時各列的介紹
2、唯一索引
唯一索引有兩個功能:加速查詢和唯一約束(不能重複,但是可以為空,只能包含一個null值)
建立唯一索引的方式:
建立表的同時建立唯一索引:
語法:create table 表名(id int not null auto_increment primary key,name char(50),
age tinyint not null , unique index idx_age(age))
直接建立唯一索引:
語法:create unique index 索引名 on 表名(欄位)
3.主鍵索引
主鍵有兩個功能:加速查詢 和 唯一約束(不可含null)
注意:一個表中最多隻能有一個主鍵索引
#方式一: create table tb3( id int not null auto_increment primary key, name varchar(50) not null, age int default 0 ); #方式二: create table tb3( id int not null auto_increment, name varchar(50) not null, age int default 0 , primary key(id) );建立主鍵

alter table tb3 add primary key(id);
#方式一
alter table tb3 drop primary key;
#方式二:
#如果當前主鍵為自增主鍵,則不能直接刪除.需要先修改自增屬性,再刪除
alter table tb3 modify id int ,drop primary key;
4.組合索引
組合索引是將n個列組合成一個索引
其應用場景為:頻繁的同時使用n列來進行查詢,如:where n1 = 'alex' and n2 = 666。
create table tb4(
id int not null , name varchar(50) not null, age int not null, index idx_name_age (name,age) )
create index idx_name_age on tb4(name,age);
4.聚合索引和輔助索引
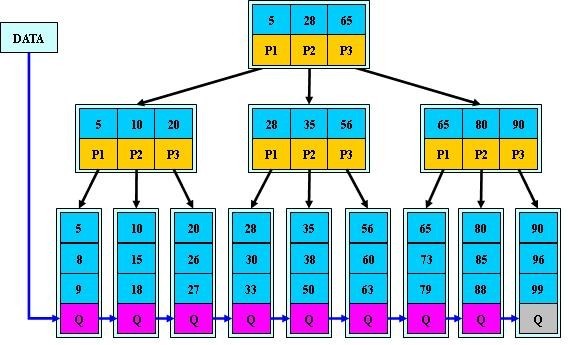
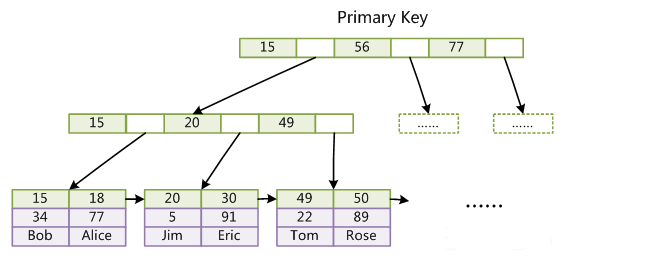
資料庫中的B+樹索引可以分為聚集索引和輔助索引.
聚集索引:InnoDB表 索引組織表,即表中資料按主鍵B+樹存放,葉子節點直接存放整條資料,每張表只能有一個聚集索引。
如圖:
1.當你定義一個主鍵時,InnnodDB儲存引擎則把它當做聚集索引
2.如果你沒有定義一個主鍵,則InnoDB定位到第一個唯一索引,且該索引的所有列值均飛空的,則將其當做聚集索引。
3如果表沒有主鍵或合適的唯一索引INNODB會產生一個隱藏的行ID值6位元組的行ID聚集索引,
補充:由於實際的資料頁只能按照一顆B+樹進行排序,因此每張表只能有一個聚集索引,聚集索引對於主鍵的排序和範圍查詢非常有利.
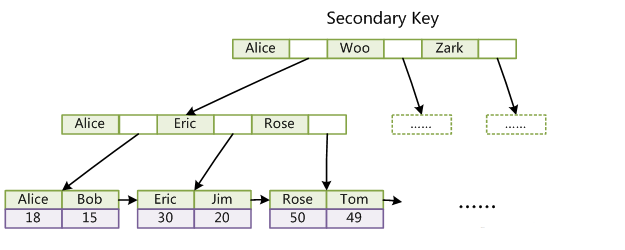
輔助索引:(也稱非聚集索引)是指葉節點不包含行的全部資料,葉節點除了包含鍵值之外,還包含一個書籤連線,通過該書籤再去找相應的行資料。下圖顯示了
InnoDB儲存引擎輔助索引獲得資料的查詢方式:
從上圖中可以看出,輔助索引葉節點存放的是主鍵值,獲得主鍵值後,再從聚集索引中查詢整行資料。舉個例子,如果在一顆高度為3的輔助索引中查詢資料,首先從輔助索引中獲得主鍵值(3次IO),接著從高度為3的聚集索引中查詢以獲得整行資料(3次IO),總共需6次IO。一個表上可以存在多個輔助索引。
總結二者區別:
相同的是:不管是聚集索引還是輔助索引,其內部都是B+樹的形式,即高度是平衡的,葉子結點存放著所有的資料。
不同的是:聚集索引葉子結點存放的是一整行的資訊,而輔助索引葉子結點存放的是單個索引列資訊.
何時使用聚集索引或非聚集索引
下面的表總結了何時使用聚集索引或非聚集索引(很重要):
動作描述
使用聚集索引
使用非聚集索引
列經常被分組排序
應
應
返回某範圍內的資料
應
不應
一個或極少不同值
不應
不應
頻繁更新的列
不應
應
外來鍵列
應
應
主鍵列
應
應
頻繁修改索引列
不應
應
5.測試索引
1.建立資料
-- 1.建立表 CREATE TABLE userInfo( id int NOT NULL, name VARCHAR(16) DEFAULT NULL, age int, sex char(1) not null, email varchar(64) default null )ENGINE=MYISAM DEFAULT CHARSET=utf8;建立表
注意:MYISAM儲存引擎 不產生引擎事務,資料插入速度極快,為方便快速插入測試資料,等我們插完資料,再把儲存型別修改為InnoDB
2.建立儲存過程,插入資料
-- 2.建立儲存過程 delimiter$$ CREATE PROCEDURE insert_user_info(IN num INT) BEGIN DECLARE val INT DEFAULT 0; DECLARE n INT DEFAULT 1; -- 迴圈進行資料插入 WHILE n <= num DO set val = rand()*50; INSERT INTO userInfo(id,name,age,sex,email)values(n,concat('alex',val),rand()*50,if(val%2=0,'女','男'),concat('alex',n,'@qq.com')); set n=n+1; end while; END $$ delimiter;3.呼叫儲存過程,插入500萬條資料
1 call insert_user_info(5000000);
4.此步驟可以忽略。修改引擎為INNODB
1 ALTERTABLEuserinfo ENGINE=INNODB;
5.測試索引
1. 在沒有索引的前提下測試查詢速度
1 SELECT*FROMuserinfoWHEREid = 4567890;
注意:無索引情況,mysql根本就不知道id等於4567890的記錄在哪裡,只能把資料表從頭到尾掃描一遍,此時有多少個磁碟塊就需要進行多少IO操作,所以查詢速度很慢.2.在表中已經存在大量資料的前提下,為某個欄位段建立索引,建立速度會很慢
1 CREATEINDEXidx_idonuserinfo(id);
3.在索引建立完畢後,以該欄位為查詢條件時,查詢速度提升明顯
1 select*fromuserinfowhereid = 4567890;
注意:
1. mysql先去索引表裡根據b+樹的搜尋原理很快搜索到id為4567890的資料,IO大大降低,因而速度明顯提升
2. 我們可以去mysql的data目錄下找到該表,可以看到新增索引後該表佔用的硬碟空間多了
3.如果使用沒有新增索引的欄位進行條件查詢,速度依舊會很慢(如圖:)

6.正確使用索引
資料庫表中新增索引後確實會讓查詢速度起飛,但前提必須是正確的使用索引來查詢,如果以錯誤的方式使用,則即使建立索引也會不奏效。
即使建立索引,索引也不會生效,例如:#1. 範圍查詢(>、>=、<、<=、!= 、between...and) #1. = 等號 select count(*) from userinfo where id = 1000 -- 執行索引,索引效率高 #2. > >= < <= between...and 區間查詢 select count(*) from userinfo where id <100; -- 執行索引,區間範圍越小,索引效率越高 select count(*) from userinfo where id >100; -- 執行索引,區間範圍越大,索引效率越低 select count(*) from userinfo where id between 10 and 500000; -- 執行索引,區間範圍越大,索引效率越低 #3. != 不等於 select count(*) from userinfo where id != 1000; -- 索引範圍大,索引效率低 #2.like '%xx%' #為 name 欄位新增索引 create index idx_name on userinfo(name); select count(*) from userinfo where name like '%xxxx%'; -- 全模糊查詢,索引效率低 select count(*) from userinfo where name like '%xxxx'; -- 以什麼結尾模糊查詢,索引效率低 #例外: 當like使用以什麼開頭會索引使用率高 select * from userinfo where name like 'xxxx%'; #3. or select count(*) from userinfo where id = 12334 or email ='xxxx'; -- email不是索引欄位,索引此查詢全表掃描 #例外:當or條件中有未建立索引的列才失效,以下會走索引 select count(*) from userinfo where id = 12334 or name = 'alex3'; -- id 和 name 都為索引欄位時, or條件也會執行索引 #4.使用函式 select count(*) from userinfo where reverse(name) = '5xela'; -- name索引欄位,使用函式時,索引失效 #例外:索引欄位對應的值可以使用函式,我們可以改為一下形式 select count(*) from userinfo where name = reverse('5xela'); #5.型別不一致 #如果列是字串型別,傳入條件是必須用引號引起來,不然... select count(*) from userinfo where name = 454; #型別一致 select count(*) from userinfo where name = '454'; #6.order by #排序條件為索引,則select欄位必須也是索引欄位,否則無法命中 select email from userinfo ORDER BY name DESC; -- 無法命中索引 select name from userinfo ORDER BY name DESC; -- 命中索引 #特別的:如果對主鍵排序,則還是速度很快: select id from userinfo order by id desc;
7.組合索引
組合索引: 是指對錶上的多個列組合起來做一個索引.
組合索引好處:簡單的說有兩個主要原因:
- "一個頂三個"。建了一個(a,b,c)的組合索引,那麼實際等於建了(a),(a,b),(a,b,c)三個索引,因為每多一個索引,都會增加寫操作的開銷和磁碟空間的開銷。對於大量資料的表,這可是不小的開銷!
- 索引列越多,通過索引篩選出的資料越少。有1000W條資料的表,有如下sql:select * from table where a = 1 and b =2 and c = 3,假設假設每個條件可以篩選出10%的資料,如果只有單值索引,那麼通過該索引能篩選出1000W*10%=100w 條資料,然後再回表從100w條資料中找到符合b=2 and c= 3的資料,然後再排序,再分頁;如果是組合索引,通過索引篩選出1000w *10% *10% *10%=1w,然後再排序、分頁,哪個更高效,一眼便知
最左匹配原則: 從左往右依次使用生效,如果中間某個索引沒有使用,那麼斷點前面的索引部分起作用,斷點後面的索引沒有起作用;select * from mytable where a=3 and b=5 and c=4; #abc三個索引都在where條件裡面用到了,而且都發揮了作用
select * from mytable where c=4 and b=6 and a=3; #這條語句列出來只想說明 mysql沒有那麼笨,where裡面的條件順序在查詢之前會被mysql自動優化,效果跟上一句一樣
select * from mytable where a=3 and c=7; #a用到索引,b沒有用,所以c是沒有用到索引效果的
select * from mytable where a=3 and b>7 and c=3; #a用到了,b也用到了,c沒有用到,這個地方b是範圍值,也算斷點,只不過自身用到了索引
select * from mytable where b=3 and c=4; #因為a索引沒有使用,所以這裡 bc都沒有用上索引效果
select * from mytable where a>4 and b=7 and c=9; #a用到了 b沒有使用,c沒有使用
select * from mytable where a=3 order by b; #a用到了索引,b在結果排序中也用到了索引的效果
select * from mytable where a=3 order by c; #a用到了索引,但是這個地方c沒有發揮排序效果,因為中間斷點了
select * from mytable where b=3 order by a; #b沒有用到索引,排序中a也沒有發揮索引效果
8.注意事項
1 2 3 4 5 6 7 8 9 10 1. 避免使用select*2. 其他資料庫中使用count(1)或count(列) 代替count(*),而mysql資料庫中count(*)經過優化後,效率與前兩種基本一樣.3. 建立表時儘量時char代替varchar4. 表的欄位順序固定長度的欄位優先5. 組合索引代替多個單列索引(經常使用多個條件查詢時)6. 使用連線(JOIN)來代替子查詢(Sub-Queries)7. 不要有超過4個以上的表連線(JOIN)8. 優先執行那些能夠大量減少結果的連線。9. 連表時注意條件型別需一致10.索引雜湊值不適合建索引,例:性別不適合
9.查詢計劃
explain + 查詢SQL - 用於顯示SQL執行資訊引數,根據參考資訊可以進行SQL優化
1 explainselectcount(*)fromuserinfowhereid = 1;
執行計劃:讓mysql預估執行操作(一般正確) type : 查詢計劃的連線型別, 有多個引數,先從最佳型別到最差型別介紹
效能: null > system/const > eq_ref > ref > ref_or_null > index_merge > range > index > all 慢: explain select * from userinfo where email='alex'; type: ALL(全表掃描) 特別的: select * from userinfo limit 1; 快: explain select * from userinfo where name='alex'; type: ref(走索引)EXPLAIN 引數詳解: http://www.cnblogs.com/wangfengming/articles/8275448.html

10.慢日誌查詢
慢查詢日誌
將mysql伺服器中影響資料庫效能的相關SQL語句記錄到日誌檔案,通過對這些特殊的SQL語句分析,改進以達到提高資料庫效能的目的。
慢查詢日誌引數:
1 2 3 4 5 long_query_time : 設定慢查詢的閥值,超出設定值的SQL即被記錄到慢查詢日誌,預設值為10sslow_query_log : 指定是否開啟慢查詢日誌log_slow_queries : 指定是否開啟慢查詢日誌(該引數已經被slow_query_log取代,做相容性保留)slow_query_log_file : 指定慢日誌檔案存放位置,可以為空,系統會給一個預設的檔案host_name-slow.loglog_queries_not_using_indexes: 如果值設定為ON,則會記錄所有沒有利用索引的查詢.檢視 MySQL慢日誌資訊
1 2 3 4 #.查詢慢日誌配置資訊 :show variableslike'%query%';#.修改配置資訊setglobalslow_query_log =on;檢視不使用索引引數狀態:
1 2 3 4 # 顯示引數show variableslike'%log_queries_not_using_indexes';# 開啟狀態setgloballog_queries_not_using_indexes =on;檢視慢日誌顯示的方式
1 2 3 4 5 #檢視慢日誌記錄的方式show variableslike'%log_output%';#設定慢日誌在檔案和表中同時記錄setgloballog_output='FILE,TABLE';測試慢查詢日誌
1 2 3 4 5 #查詢時間超過10秒就會記錄到慢查詢日誌中selectsleep(3)FROMuser;#查看錶中的日誌select*frommysql.slow_log;
11.大資料量分頁優化
執行此段程式碼:
1 select*fromuserinfo limit 3000000,10;優化方案:
一. 簡單粗暴,就是不允許檢視這麼靠後的資料,比如百度就是這樣的
最多翻到72頁就不讓你翻了,這種方式就是從業務上解決;
二.在查詢下一頁時把上一頁的行id作為引數傳遞給客戶端程式,然後sql就改成了
1 select*fromuserinfowhereid>3000000 limit 10;這條語句執行也是在毫秒級完成的,id>300w其實就是讓mysql直接跳到這裡了,不用依次在掃描全面所有的行
如果你的table的主鍵id是自增的,並且中間沒有刪除和斷點,那麼還有一種方式,比如100頁的10條資料
1 select*fromuserinfowhereid>100*10 limit 10;
三.最後第三種方法:延遲關聯
我們在來分析一下這條語句為什麼慢,慢在哪裡。
1 select*fromuserinfo limit 3000000,10;玄機就處在這個 * 裡面,這個表除了id主鍵肯定還有其他欄位 比如 name age 之類的,因為select * 所以mysql在沿著id主鍵走的時候要回行拿資料,走一下拿一下資料;
如果把語句改成
1 selectidfromuserinfo limit 3000000,10;你會發現時間縮短了一半;然後我們在拿id分別去取10條資料就行了;
語句就改成這樣了:
1 selecttable.*fromuserinfoinnerjoin(selectidfromuserinfo limit 3000000,10 )astmpontmp.id=userinfo.id;這三種方法最先考慮第一種 其次第二種,第三種是別無選擇
