
深入理解JVM之JIT編譯器(二)
上篇是分析了一下前段編譯器,主要過程完成從java程式碼到位元組碼的轉變,它的改進頂多是提高程式的編碼速度和效率。本篇嘗試探索JIT編譯器,它能夠完成從位元組碼到本地機器碼的轉變,從而真正的影響程式的執行效率。
概念
部分商用虛擬機器,程式最初是通過直譯器(Interpreter)進行解釋執行,當發現某個部分程式碼頻繁執行的時候,就會將這些程式碼認定為「熱點程式碼」(即 Hot Spot Code)。為了提高熱點程式碼的執行效率,在執行時,虛擬機器會把這些程式碼編譯成與本地平臺相關的機器碼,並進行各種優化,完成這個任務的編譯器成為即時編譯器(Just In Time Compiler,簡稱JIT編譯器)。
- 它並不是VM必需的部分,java虛擬機器規範並沒有規定它必須存在,所以也沒限定如何去實現。
- 即時編譯器編譯效能的好壞、程式碼優化程度高低是衡量商用虛擬機器優秀與否最關鍵指標之一。
Hotspot VM的JIT編譯器
直譯器和編譯器
不是所有Java虛擬機器均採用二者並存的架構,但是一些主流商用虛擬機器如Hotspot、J9都會同時包含二者。關於二者的優勢如下:
- 程式剛啟動和執行的時候,直譯器可以首先發揮作用,省去編譯的時間,立即執行位元組碼。
- 程式執行之後,經過一段時間,編譯器可以逐漸發揮作用,把更多的程式碼編譯為本地機器碼,獲得更高的執行效率。
在整個虛擬機器執行架構中,直譯器和編譯器經常配合工作,如下圖所示: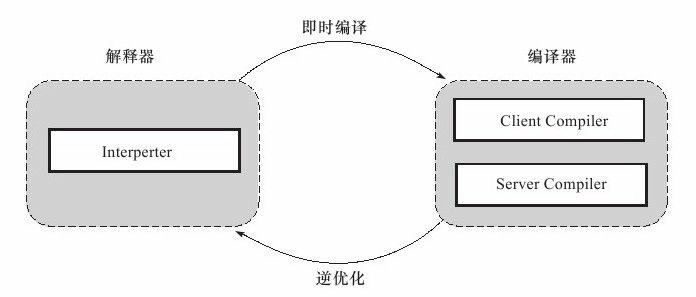
 瞭解完直譯器和編譯器之後,我們想知道那些程式碼會被編譯?在什麼情況下會觸發編譯?基於這兩個問題,來了解編譯物件和觸發條件。
瞭解完直譯器和編譯器之後,我們想知道那些程式碼會被編譯?在什麼情況下會觸發編譯?基於這兩個問題,來了解編譯物件和觸發條件。
編譯物件
在執行過程中會被即時編譯器編譯的「熱點程式碼」有兩類,如下:
- 被多次呼叫的方法
- 被多次執行的迴圈體
關於這兩種情況,有兩點解釋:對於第一種情況,是由方法呼叫觸發的編譯,理所當然的會以整個方法體作為編譯物件,這種編譯是虛擬機器中標準的JIT編譯。對於第二種情況,編譯動作由迴圈體觸發,但是編譯器仍舊會以整個方法作為編譯物件,由於這種方法發生在方法執行過程中,所以稱為棧上替換(On Stack Replacement,簡稱OSR編譯,因為方法棧幀還在棧上)。
觸發條件
正如上面所說的“多次”並不夠嚴謹和具體,那麼如何才算是“多次”呢?以及怎麼樣去統計一個方法和一段程式碼被執行多少次呢?回答了這兩個問題就是回答了觸發條件。判斷一段程式碼是不是熱點程式碼,是不是需要觸發即時編譯,這樣的行為叫「熱點探測」。關於熱點探測有兩種方式,如下:
- 基於取樣的熱點探測 虛擬機器會週期性檢查各個執行緒的棧頂,如果發現某些方法長期佔據棧頂,那麼會被認為是「熱點程式碼」。簡單、高效,但是不夠精確,因為某些方法會因為執行緒阻塞或其他原因擾亂熱點探測。
- 基於計數器的熱點探測(Hotspot VM採用) 虛擬機器為每個方法或者程式碼塊建立計數器,統計執行次數,超過一定閥值會被認為是「熱點程式碼」。
Hotspot VM使用第二種,並且為每個方法準備了兩種計數器:方法呼叫計數器和回邊計數器(在位元組碼中遇到控制流向後跳轉的指令稱為“回邊 ”)。在確定虛擬執行引數的情況下,這兩個計數器都有一個確定的閥值,超過這個閥值就會觸發JIT編譯。方法呼叫計數器觸發即時編譯的互動過程如下圖: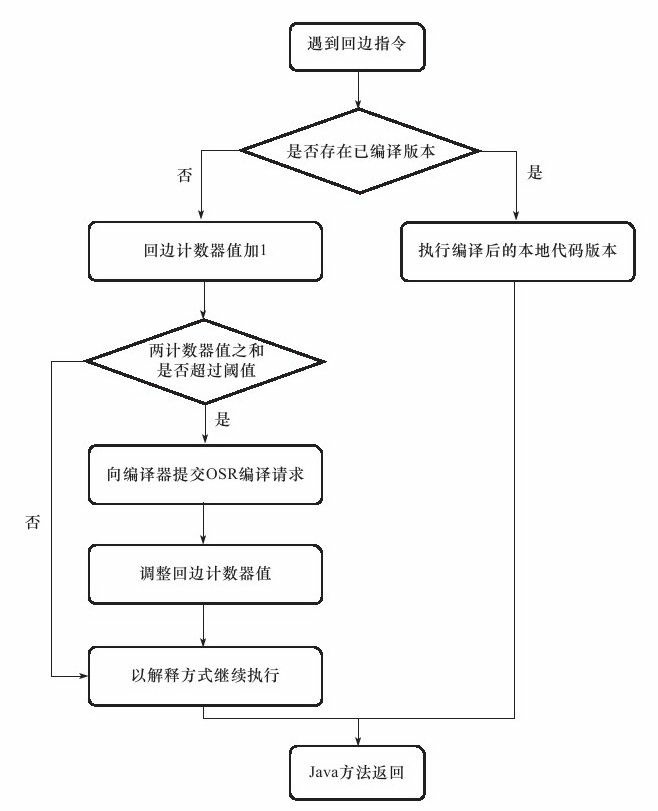
編譯過程
在預設設定下,無論是方法呼叫產生的即時編譯請求,還是OSR編譯請求,虛擬機器在程式碼編譯還未完成之前,都仍然按照解釋方式執行,而編譯動作則在後臺編譯執行緒中進行。至於在後臺如何執行編譯過程,Client Compiler和Server Compiler的編譯過程是不同的。二者大致區別如下:
- Client Compiler:主要關注點在區域性優化,而放棄了耗時較長的全域性優化手段。
- Server Compiler:是專門面向伺服器端的典型應用併為服務端的效能配置特別調整過。
從即時編譯的角度看,Server Compiler是比較慢,但其編譯速度又遠遠超過「靜態優化編譯器」,而且比Client Compiler輸出的程式碼質量高,可以減少原生代碼執行時間,從而抵消額外的編譯時間。
編譯優化技術
之所以有編譯方式執行原生代碼比解釋方式更快這樣的共識,原因很簡單,是因為虛擬機器設計團隊幾乎把對程式碼所有的優化措施集中在了即時編譯器之中,因此一般來說,即時編譯器產生的原生代碼會比Javac產生的位元組碼更優秀。常用優化技術如下:
公共子表示式消除
語言無關,比如像:b乘c、c乘b這樣的表示式值都是一樣的可以直接替換。
陣列範圍消除
語言相關,主要思路就是儘可能把執行期檢查提任務前到編譯器進行,以至於在迴圈遍歷的時候不需要每次都要判斷變數大小是否超過陣列範圍,帶來隱式開銷,只要在編譯期根據資料流獲得陣列的length,並且判斷下標沒有越界,執行的時候就無需判斷了。
方法內聯
為了消除方法呼叫的成本,同時為其他優化手段建立好的基礎。因為很多方法分開看是有意義的,如果不做方法內聯,即使進行了無用程式碼消除,也無法發現任何“Dead Code”。
逃逸分析
並不是直接的優化手段,而是為其他優化手段提供分析技術。逃逸分析的基本行為就是分析物件的作用域,比如一個物件在一個方法中被定義,可能被外部方法所引用,例如作為方法引數傳遞到其他方法中,這被稱為方法逃逸。甚至可能被其他執行緒訪問,例如賦值給類變數或其他執行緒訪問的例項變數,就是執行緒逃逸。
因此,如果能證明一個不會發生方法或者執行緒逃逸,則可以為這個變數進行一些高效優化。優化措施如下:
- 棧上分配 將確定不會逃逸的物件在在棧幀上進行建立分配記憶體,這樣方法結束時,物件就會隨著棧幀出棧而銷燬,減少堆記憶體垃圾回收的壓力。
- 同步消除 如果確定一個變數不會執行緒逃逸,也就說明該變數不會發生執行緒競爭,從而消除掉該變數的同步措施。
- 標量替換 像java中的原始資料型別如int、long均稱為標量(表示無法分解為更小的資料來表示了),如果一個數據可以繼續分解,則為聚合量,而java中的物件則為典型的聚合量。如果一個物件不會被外部訪問,而這個物件可以被拆散分解,那麼就不去建立這個物件,而是直接建立被使用到的成員變數。而這些成員變數除了被分配在棧上(棧上的資料很容易會被虛擬機器分配到物理高速暫存器)進行讀和寫,還為後續優化創造基礎條件。
本篇主要了解直譯器和編譯器的特點和各自優勢、然後總結了編譯物件和編譯條件,最後介紹了編譯過程以及用到的一些主要的編譯優化技術,算是對即時編譯器有個基本的理解了。