
Repulsion Loss: Detecting Pedestrians in a Crowd詳解(遮擋下的行人檢測)
最近做新人檢測Re-ID的工作,剛好記錄一下對論文的閱讀和個人理解。文章中部分內容為引用別人的,我在文章最後也給出了引用的文章連結。如有侵權,請聯絡我刪除。
一、綜述
行人檢測中遮擋分為兩種型別,一種是由於非目標造成的遮擋,文中作者稱為Reasonable-occlusion,另外一種是由於也是需要檢測的目標造成的遮擋,作者稱為Reasonable-crowd。對於前一種型別遮擋,很難有針對性的辦法去解決,最好的辦法也就是使用更多的資料和更強的feature。但是對於後一種型別的遮擋,現在的pipeline其實並沒有很好充分利用資訊,例如下面示意的這個情況,兩個黑色的框代表的是兩個Ground Truth,紅色和綠色分別是被assign到1號的GT上的anchor或者proposal。

作者作者還在CityPersons資料集上分別做了定量統計,可以看到在不同的誤檢率下,從圖中可以發現遮擋佔據了近60%的席位(藍色+橙色),而在這60%席位中,自遮擋又佔據了近60%。

二、Repulsion Loss
作者提出Repulsion loss函式定義如下:
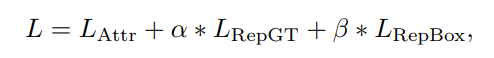 其中第一個子模組是使得預測框和匹配上的目標框儘可能接近,即:smooth L1損失,目的是使迴歸目標與GT接近;第二個子模組是使得預測框和周圍的目標框儘可能遠離,即:目標是使proposal和要儘量遠離和它overlap的第二大的GT;第三個子模組是使得預測框和周圍的其他預測框儘可能遠離,即:使assign到不同GT的proposal之間儘量遠離。通過第二個和第三個loss,不僅僅使得proposal可以向正確的目標靠近,也可以使其遠離錯誤的目標,從而減少NMS時候的誤檢。
其中第一個子模組是使得預測框和匹配上的目標框儘可能接近,即:smooth L1損失,目的是使迴歸目標與GT接近;第二個子模組是使得預測框和周圍的目標框儘可能遠離,即:目標是使proposal和要儘量遠離和它overlap的第二大的GT;第三個子模組是使得預測框和周圍的其他預測框儘可能遠離,即:使assign到不同GT的proposal之間儘量遠離。通過第二個和第三個loss,不僅僅使得proposal可以向正確的目標靠近,也可以使其遠離錯誤的目標,從而減少NMS時候的誤檢。
Attraction Term()
因為是使得預測框Pi和周圍的其他預測框Pj儘可能遠離,Pi和Pj分別匹配上不同的目標框,它們之間的距離採用的是IoU,則RepBox loss定義為:
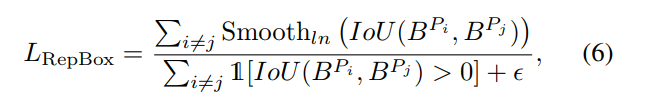 從式(4)中可以發現當預測框Pi和周圍的其他預測框Pj的IoU越大,則產生的loss也會越大,因此可以有效防止兩個預測框因為靠的太近而被NMS過濾掉,進而減少漏檢。
從式(4)中可以發現當預測框Pi和周圍的其他預測框Pj的IoU越大,則產生的loss也會越大,因此可以有效防止兩個預測框因為靠的太近而被NMS過濾掉,進而減少漏檢。
Repulsion Term ()
因為是使得預測框P和周圍的目標框G儘可能遠離,這裡的周圍的目標框是除了匹配上的目標框以外的IoU最大的目標框,也即和它overlap的第二大GT:
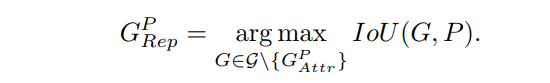 作者使用了Intersection over GT(IoG)而不是傳統的IoU,原因在於GT無法改變,仔細思考一下,如果是IoU的話,那麼只要預測框足夠大就一定能夠使得RepGT loss減小,而這和我們的預期目標是不一致的,也就是說如果使用IoU則網路可以通過放大proposal的方式來降低loss,但是這並不是我們所期望的。如果直接使用IoG,分母是GT的面積無法改變,從而規避了這樣的問題。
作者使用了Intersection over GT(IoG)而不是傳統的IoU,原因在於GT無法改變,仔細思考一下,如果是IoU的話,那麼只要預測框足夠大就一定能夠使得RepGT loss減小,而這和我們的預期目標是不一致的,也就是說如果使用IoU則網路可以通過放大proposal的方式來降低loss,但是這並不是我們所期望的。如果直接使用IoG,分母是GT的面積無法改變,從而規避了這樣的問題。
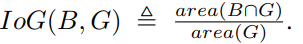 所以RepGT損失定義為:
所以RepGT損失定義為:
 Note:P ∈ ,即為GT
即為預測的box
P = (lP , tP , wP , hP ) 表示proposal bounding box
G = (lG, tG, wG, hG) 表示groundtruth bounding box
P+ = {P} is the set of all positive proposals (those who have a high IoU (e.g., IoU ≥ 0.5) with at least one ground-truth box are regarded as positive samples, while negative samples otherwise).
G = {G} is the set of all ground-truth boxes in one image.
從(4)我們可以看出:當預測框P和周圍的目標框G的IoG越大,則產生的loss也會越大,因此可以有效防止預測框偏移到周圍的目標框上。此外,式(5)中的sigma是一個調整LRepGT敏感程度的超引數。
其中這個Smooth_ln是針對0到1的輸入變數設計的一個robust function,具體形狀如下所示:
Note:P ∈ ,即為GT
即為預測的box
P = (lP , tP , wP , hP ) 表示proposal bounding box
G = (lG, tG, wG, hG) 表示groundtruth bounding box
P+ = {P} is the set of all positive proposals (those who have a high IoU (e.g., IoU ≥ 0.5) with at least one ground-truth box are regarded as positive samples, while negative samples otherwise).
G = {G} is the set of all ground-truth boxes in one image.
從(4)我們可以看出:當預測框P和周圍的目標框G的IoG越大,則產生的loss也會越大,因此可以有效防止預測框偏移到周圍的目標框上。此外,式(5)中的sigma是一個調整LRepGT敏感程度的超引數。
其中這個Smooth_ln是針對0到1的輸入變數設計的一個robust function,具體形狀如下所示:
 可以看到,正如Smooth_l1不會對特別大的偏差給予過大的penalty,Smooth_ln對於很小接近於1的輸入也不會像原始的ln函式一樣給予負無窮那麼大的loss,從而可以穩定訓練過程,而且對抗一些outlier。
可以看到,正如Smooth_l1不會對特別大的偏差給予過大的penalty,Smooth_ln對於很小接近於1的輸入也不會像原始的ln函式一樣給予負無窮那麼大的loss,從而可以穩定訓練過程,而且對抗一些outlier。
暫時還沒看到作者給出原始碼,近期我會做復現,之後我會放出復現的程式碼。