
從上百幅架構圖中學得半點大型網站建設經驗(上)
從上百幅架構圖中學大型網站建設經驗(上)
引言
近段時間以來,通過接觸有關海量資料處理和搜尋引擎的諸多技術,常常見識到不少精妙絕倫的架構圖。除了每每感嘆於每幅圖表面上的繪製的精細之外,更為架構圖背後所隱藏的設計思想所歎服。個人這兩天一直在蒐集各大型網站的架構設計圖,一為了一飽眼福,領略各類大型網站架構設計的精彩之外,二來也可供閒時反覆琢磨體會,何樂而不為呢?特此,總結整理了諸如國外wikipedia,Facebook,Yahoo!,YouTube,MySpace,Twitter,國內如優酷網等大型網站的技術架構(本文重點分析優酷網的技術架構),以饗讀者。
本文著重凸顯每一幅圖的精彩之處與其背後含義,而圖的說明性文字則從簡從略。ok,好好享受此番架構盛宴吧。當然,若有任何建議或問題,歡迎不吝指正。謝謝。
1、WikiPedia 技術架構
WikiPedia 技術架構圖Copy @Mark Bergsma
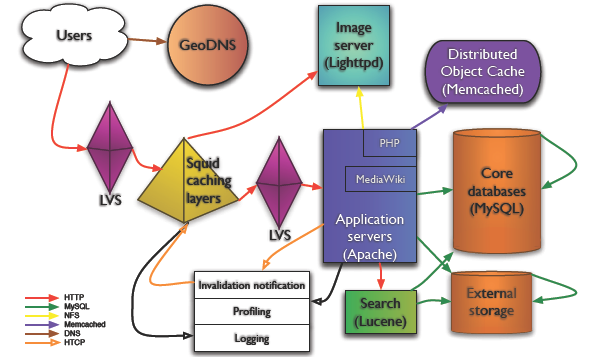
- 來自wikipedia的資料:峰值每秒鐘3萬個 HTTP 請求 每秒鐘 3Gbit 流量, 近乎375MB 350 臺 PC 伺服器。
- GeoDNSA :40-line patch for BIND to add geographical filters support to the existent views in BIND", 把使用者帶到最近的伺服器。GeoDNS 在 WikiPedia 架構中擔當重任當然是由 WikiPedia 的內容性質決定的--面向各個國家,各個地域。
- 負載均衡:LVS,請看下圖:
。
2、Facebook 架構
Facebook 搜尋功能的架構示意圖
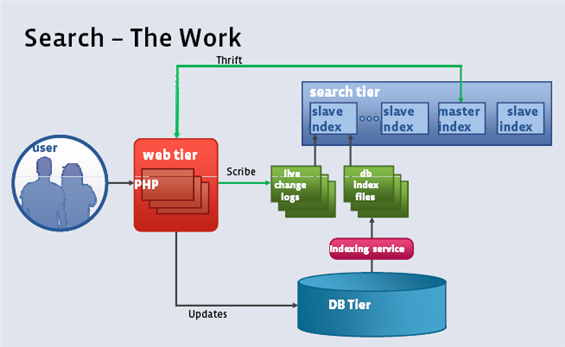
細心的讀者一定能發現,上副架構圖之前出現在此文之中:從幾幅架構圖中偷得半點海里資料處理經驗。本文與前文最大的不同是,前文只有幾幅,此文系列將有上百幅架構圖,任您盡情觀賞。
3、Yahoo! Mail 架構
Yahoo! Mail 架構
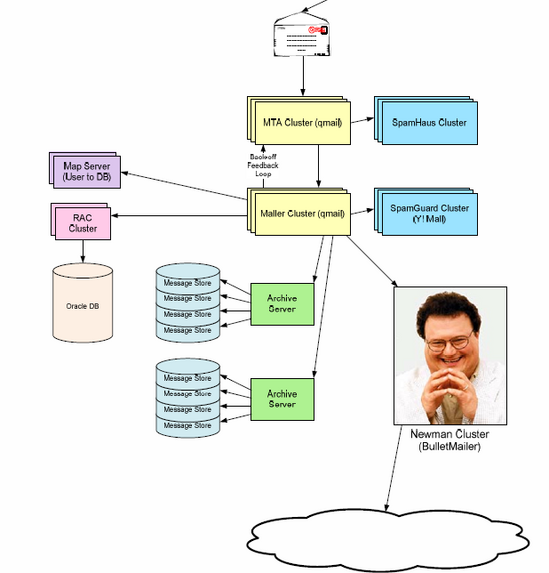
Yahoo! Mail 架構部署了 Oracle RAC,用來儲存 Mail 服務相關的 Meta 資料。
4、twitter技術架構
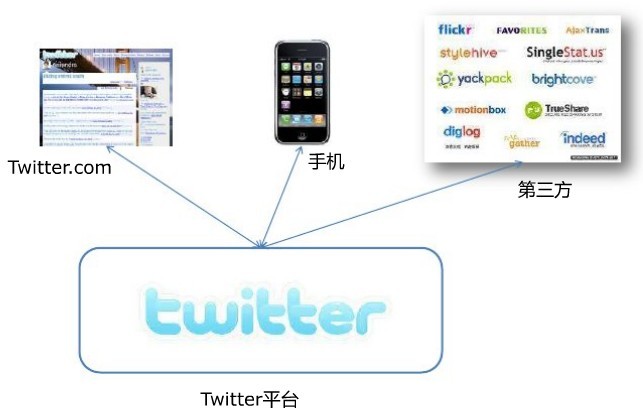
twitter的整體架構設計圖

twitter平臺大致由twitter.com、手機以及第三方應用構成,如下圖所示(其中流量主要以手機和第三方為主要來源):
快取在大型web專案中起到了舉足輕重的作用,畢竟資料越靠近CPU存取速度越快。下圖是twitter的快取架構圖:
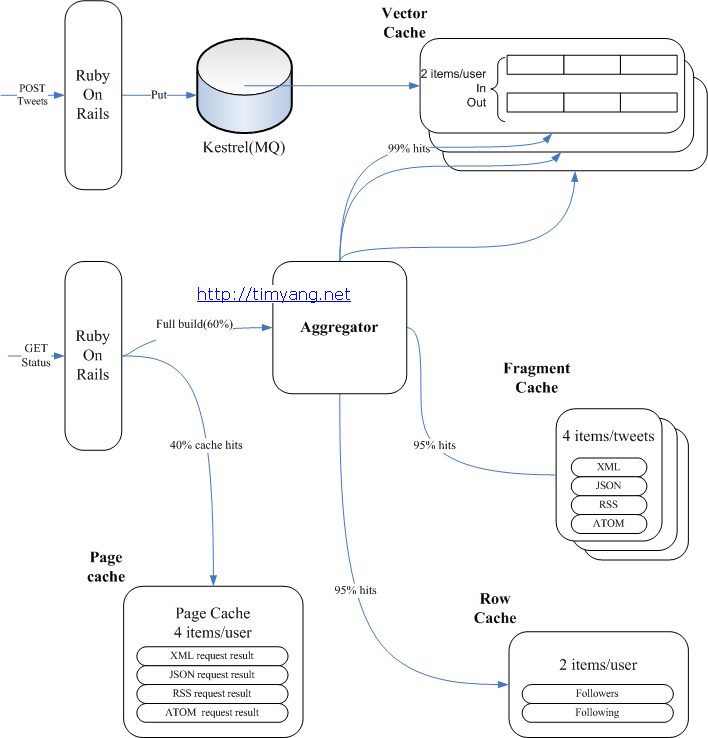
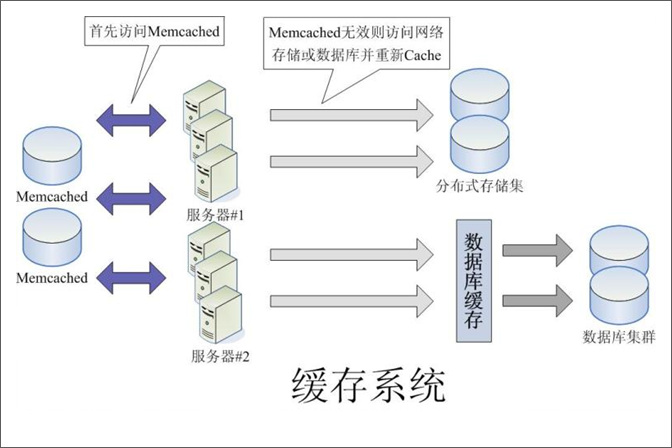
關於快取系統,還可以看看下幅圖:
5、Google App Engine技術架構
GAE的架構圖
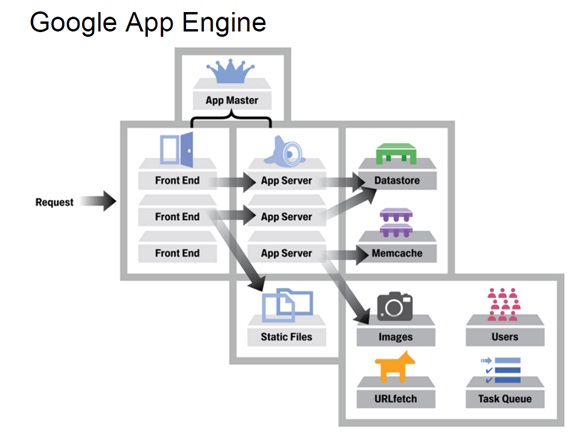
簡單而言,上述GAE的架構分為如圖所示的三個部分:前端,Datastore和服務群。
- 前端包括4個模組:Front End,Static Files,App Server,App Master。
Datastore是基於BigTable技術的分散式資料庫,雖然其也可以被理解成為一個服務,但是由於其是整個App Engine唯一儲存持久化資料的地方,所以其是App Engine中一個非常核心的模組。其具體細節將在下篇和大家討論。
整個服務群包括很多服務供App Server呼叫,比如Memcache,圖形,使用者,URL抓取和任務佇列等。
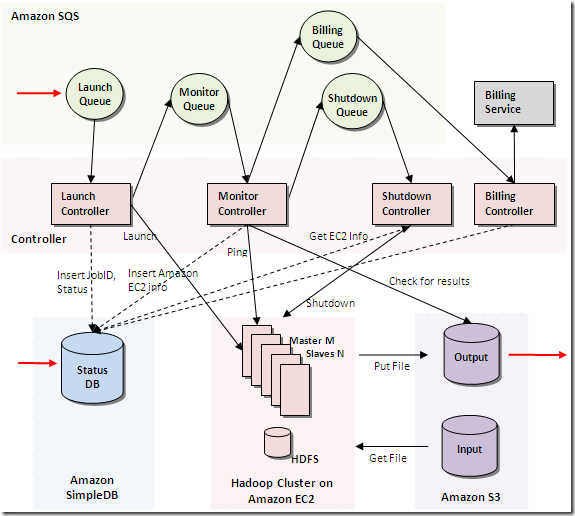
6、Amazon技術架構
Amazon的Dynamo Key-Value儲存架構圖
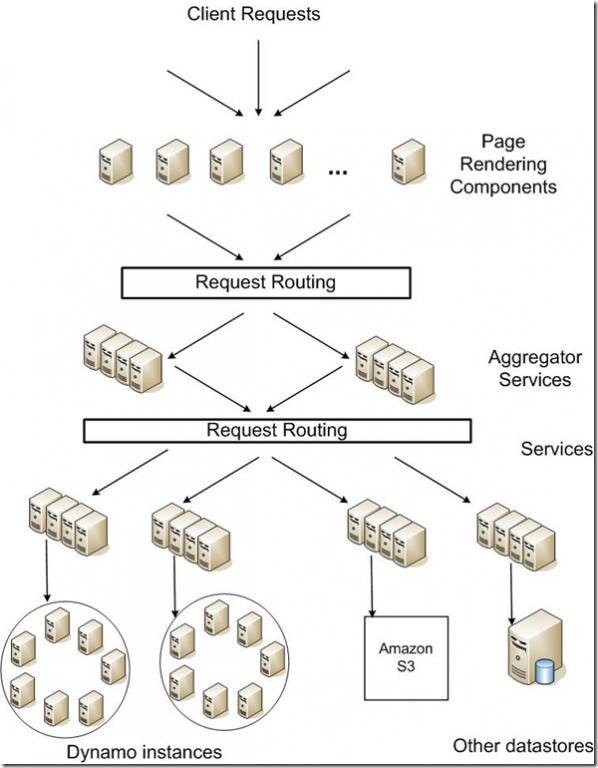
可能有讀者並不熟悉Amazon,它現在已經是全球商品品種最多的網上零售商和全球第2大網際網路公司。而之前它僅僅是一個小小的網上書店。ok,下面,咱們來見識下它的架構。
Dynamo是亞馬遜的key-value模式的儲存平臺,可用性和擴充套件性都很好,效能也不錯:讀寫訪問中99.9%的響應時間都在300ms內。按分散式系統常用的雜湊演算法切分資料,分放在不同的node上。Read操作時,也是根據key的雜湊值尋找對應的node。Dynamo使用了 Consistent Hashing演算法,node對應的不再是一個確定的hash值,而是一個hash值範圍,key的hash值落在這個範圍內,則順時針沿ring找,碰到的第一個node即為所需。
Dynamo對Consistent Hashing演算法的改進在於:它放在環上作為一個node的是一組機器(而不是memcached把一臺機器作為node),這一組機器是通過同步機制保證資料一致的。
下圖是分散式儲存系統的示意圖,讀者可觀摩之:
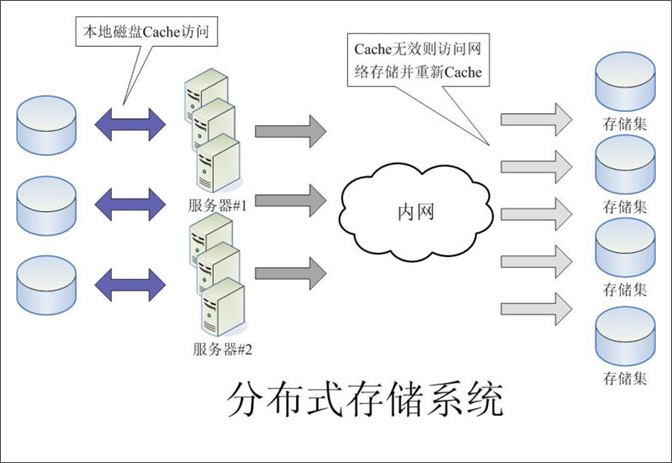
Amazon的雲架構圖如下:
Amazon的雲架構圖
7、優酷網的技術架構
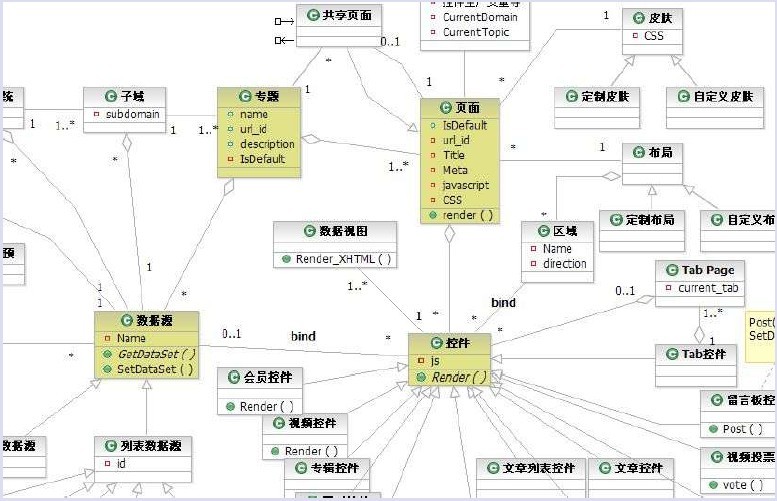
從一開始,優酷網就自建了一套CMS來解決前端的頁面顯示,各個模組之間分離得比較恰當,前端可擴充套件性很好,UI的分離,讓開發與維護變得十分簡單和靈活,下圖是優酷前端的模組呼叫關係:

這樣,就根據module、method及params來確定呼叫相對獨立的模組,顯得非常簡潔。下圖是優酷的前端區域性架構圖:
優酷的資料庫架構也是經歷了許多波折,從一開始的單臺MySQL伺服器(Just Running)到簡單的MySQL主從複製、SSD優化、垂直分庫、水平sharding分庫。
- 簡單的MySQL主從複製。MySQL的主從複製解決了資料庫的讀寫分離,並很好的提升了讀的效能,其原來圖如下:
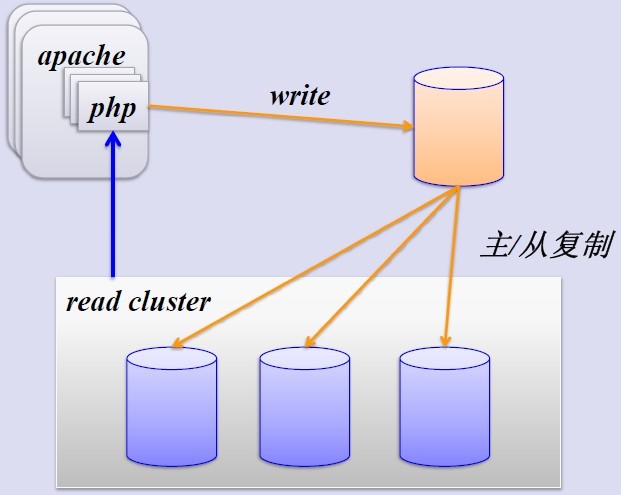
其主從複製的過程如下圖所示:
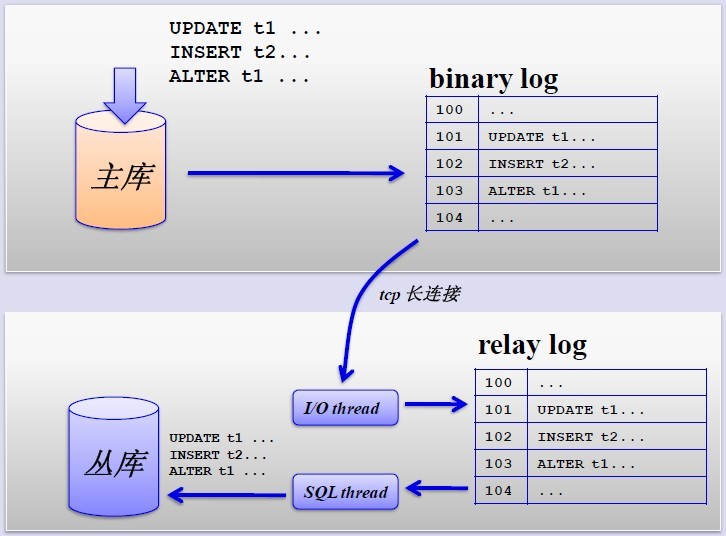
但是,主從複製也帶來其他一系列效能瓶頸問題:
- 寫入無法擴充套件
- 寫入無法快取
- 複製延時
- 鎖表率上升
- 表變大,快取率下降
那問題產生總得解決的,這就產生下面的優化方案。
MySQL垂直分割槽
如果把業務切割得足夠獨立,那把不同業務的資料放到不同的資料庫伺服器將是一個不錯的方案,而且萬一其中一個業務崩潰了也不會影響其他業務的正常進行,並且也起到了負載分流的作用,大大提升了資料庫的吞吐能力。經過垂直分割槽後的資料庫架構圖如下:
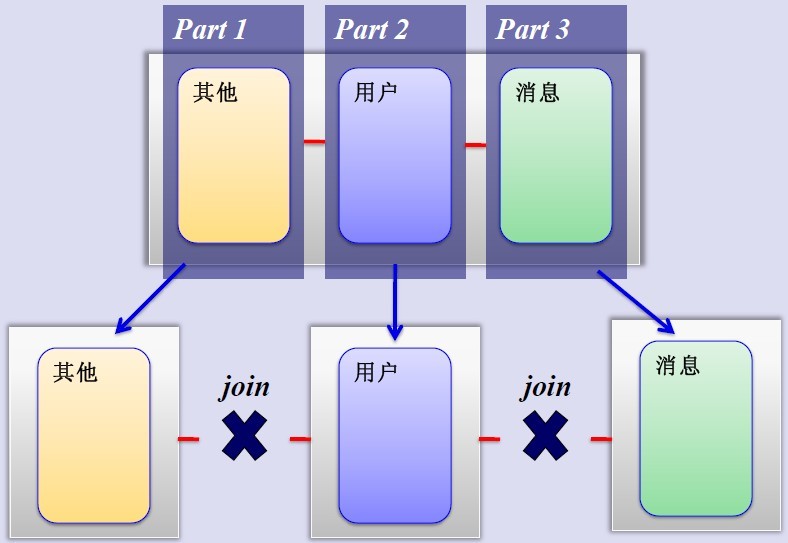
然而,儘管業務之間已經足夠獨立了,但是有些業務之間或多或少總會有點聯絡,如使用者,基本上都會和每個業務相關聯,況且這種分割槽方式,也不能解決單張表資料量暴漲的問題,因此為何不試試水平sharding呢?
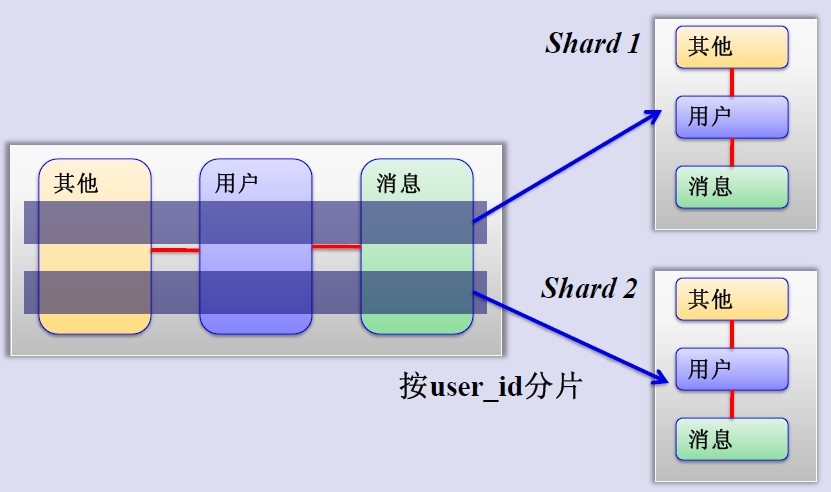
MySQL水平分片(Sharding)
這是一個非常好的思路,將使用者按一定規則(按id雜湊)分組,並把該組使用者的資料儲存到一個數據庫分片中,即一個sharding,這樣隨著使用者數量的增加,只要簡單地配置一臺伺服器即可,原理圖如下:
如何來確定某個使用者所在的shard呢,可以建一張使用者和shard對應的資料表,每次請求先從這張表找使用者的shard id,再從對應shard中查詢相關資料,如下圖所示:
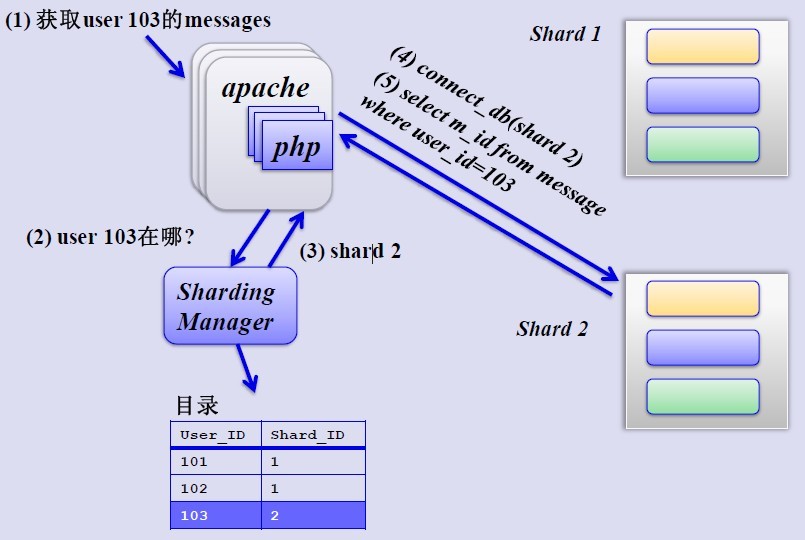 但是,優酷是如何解決跨shard的查詢呢,這個是個難點,據介紹優酷是儘量不跨shard查詢,實在不行通過多維分片索引、分散式搜尋引擎,下策是分散式資料庫查詢(這個非常麻煩而且耗效能)。
但是,優酷是如何解決跨shard的查詢呢,這個是個難點,據介紹優酷是儘量不跨shard查詢,實在不行通過多維分片索引、分散式搜尋引擎,下策是分散式資料庫查詢(這個非常麻煩而且耗效能)。快取策略
貌似大的系統都對“快取”情有獨鍾,從http快取到memcached記憶體資料快取,但優酷表示沒有用記憶體快取,理由如下:
- 避免記憶體拷貝,避免記憶體鎖
- 如接到老大哥通知要把某個視訊撤下來,如果在快取裡是比較麻煩的
而且Squid 的 write() 使用者程序空間有消耗,Lighttpd 1.5 的 AIO(非同步I/O) 讀取檔案到使用者記憶體導致效率也比較低下。
但為何我們訪問優酷會如此流暢,與土豆相比優酷的視訊載入速度略勝一籌?這個要歸功於優酷建立的比較完善的內容分發網路(CDN),它通過多種方式保證分佈在全國各地的使用者進行就近訪問——使用者點選視訊請求後,優酷網將根據使用者所處地區位置,將離使用者最近、服務狀況最好的視訊伺服器地址傳送給使用者,從而保證使用者可以得到快速的視訊體驗。這就是CDN帶來的優勢,就近訪問。
後記
此篇文章終於寫完了,從昨日有整理此文的動機後,到今日上午找電腦上網而不得,再到此刻在網咖完成此文。著實也體味了一把什麼叫做為技術狂熱的感覺。大型網站架構是一個實戰性很強的東西,而你我或許現在暫時還只是一個在外看熱鬧的門外漢而已。不過,沒關係,小魚小蝦照樣能暢遊汪汪大洋,更何況日後亦能成長為大魚大鯊。
ok,歡迎關注從上百幅架構圖中學得半點大型網站建設經驗(下)。有任何問題或錯誤,歡迎不吝指正。謝謝大家。本文完。