
mysql-cluster7.6.8應用測試,對比單機innodb
應用測試
java連線jdbc連線url調整:
jdbc:mysql:loadbalance://192.168.1.174:3306,192.168.1.176:3306/test_db?roundRobinLoadBalance=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8
建一張表,包含各種資料型別欄位

先造一批資料寫入,確保測試資料的合理性,此處用到隨機生成漢字、隨機字母、隨機數字:
// 隨機漢字 public static String getRandomStr(long length) { StringBuilder sb = new StringBuilder(); for (int i = 0; i < length; i++) { sb.append((char) (0x4e00 + (int) (Math.random() * (0x9fa5 - 0x4e00 + 1)))); } return sb.toString(); }
測試資料效果是這樣嬸兒的
空表開始
-> 單條連續插入100條,行資料0.3k左右 => ndbcluster:平均0.03s/條 => 單機innodb 平均0.03s/條
-> ndbcluster:停用其中一個sql節點,單條連續插入100條 => 可以成功寫入,可以看到多數請求在0.03s,穿插少數請求在1.03s,可以看出叢集容錯在起作用 => 繼續停用一個data節點,仍可正常寫入資料,效果同上 => 繼續停用一個manage節點,仍可正常寫入資料,效果同上新增節點
# 進入管理節點shell客戶端 ndb_mgm # 當前各節點狀態(可以看到新增節點顯示no nodegroup,這樣是無法被使用的) show # 新節點建立分組(新建後再show可以看到分組,但已有表不會自動關聯這部分節點) CREATE NODEGROUP 3,4 # 資料分佈情況(看到新增節點沒有應用0%) ALL REPORT MEMORY # 進入mysql客戶端,執行指令碼,對已有表進行重新分割槽 ALTER TABLE test_alert ALGORITHM=INPLACE, REORGANIZE PARTITION # 再次檢視資料分佈情況會看到新分割槽已經有使用了 # 通過sql可以看到分割槽情況,由原有2個分割槽變成了4個分割槽 select partition_name,table_rows from information_schema.PARTITIONS where table_name='test_alert'
繼續測試,空表開始 -> 批量插入1000條連續執行10次,行資料0.3k左右 => ndbcluster:平均2s/1k條 => 單機innodb 平均0.55s/1k條 cluster寫入明顯地域innodb,這個差距隨著node節點的增多而加大,兩個節點1.5s左右,四個節點2s左右,可以看出分發資料犧牲了不少時間,不過這樣的成績,是能夠接受的。
1w條資料量,繼續寫入 -> 批量插入2000條連續執行10次,行資料0.3k左右 => ndbcluster:平均3.5s/2k條 => 單機innodb 平均1.6s/2k條
3w資料,繼續寫入 -> 批量插入2000條連續執行50次,行資料0.3k左右 => ndbcluster:平均3.4s/2k條 => 單機innodb 平均1.6s/2k條
13w資料,繼續寫入 -> 批量插入4000條連續執行20次,行資料0.3k左右 => ndbcluster:平均7.47s/4k條 => 單機innodb 平均3.6s/2k條 此時批量數量的增加對效能提升已經沒什麼幫助了,接下來就穩定在3k條的批量測試。 順便一提,此時資料量已經達到21w,此時innodb的count全表已經變慢,2s左右,而ndbcluster還在毫秒的零頭,當然count本來就不是innodb的優勢,不能說明什麼。
21w資料下,再測試一下單條寫入效能 -> 連續插入1000條,行資料0.3k左右 => ndbcluster:平均0.029s/條 => 單機innodb 平均0.03s/條 差別不大,在這個量級測試一下隨機更新、刪除操作效果與寫入情況一致
21w資料,檢索情況 -> count全表 => ndbcluster 0.003s => 單機innodb 2.370s
-> count 主鍵範圍,同數量級(>33333,<99999) => ndbcluster 0.062s => 單機innodb 0.790s -> count 無索引欄位,同數量級(time_type = 21) => ndbcluster 0.045s = 7070 => 單機innodb 2.376s = 6995 -> count 無索引欄位,同數量級(threshold >0) => ndbcluster 0.104s = 105226 => 單機innodb 2.350s = 105478 ndbcluster引擎count多種情況下表現都比較好
-> 全表 limit 1000,100 => ndbcluster 0.213s => 單機innodb 0.057s -> 全表 limit 9000,100 => ndbcluster 1.501s => 單機innodb 0.135s -> limit 1000,10 檢索無索引欄位(time_type = 21) => ndbcluster 0.190s => 單機innodb 0.324s limit情況一致,越靠後越慢,innodb表現無條件時表現較好,有條件時略差 -> 隨機主鍵檢索 => ndbcluster 0.003s => 單機innodb 0.003s 基本沒有差別
-> 常用場景1,檢索+倒序+分頁 ( select * from test_alert where threshold >0 order by msg_publish_time desc limit 20,20) => ndbcluster 0.292s => 單機innodb 2.383s
-> 常用場景1,檢索+正序+分頁 (select * from test_alert where time_type = 13 order by msg_publish_time asc limit 20,20) => ndbcluster 0.159s => 單機innodb 2.581s ndbcluster優勢較明顯
開始加索引
ALTER TABLE `test_alert` ADD INDEX `ix_t_ptime` (`msg_publish_time`) ; ALTER TABLE `test_alert` ADD INDEX `ix_t_threshold` (`threshold`) ; ALTER TABLE `test_alert` ADD INDEX `ix_t_ttype` (`time_type`) ; => cluster平均索引時間是0.5s => innodb平均索引時間是2.5s
再測試一下常用場景
-> 常用場景1,檢索+倒序+分頁 (欄位均有索引) => ndbcluster 0.022s => 單機innodb 0.065ss
-> 常用場景1,檢索+正序+分頁 (欄位均有索引) => ndbcluster 0.085s => 單機innodb 0.061s 索引後差距不大了
索引後寫入測試 -> 連續單條插入1000條,行資料0.3k左右 => ndbcluster:平均0.029s/條 => 單機innodb 平均0.026s/條 索引前後區別不大
把資料量提到100w
此時記憶體佔用情況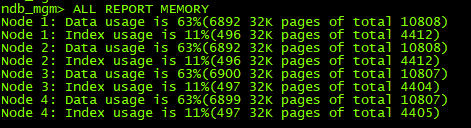
調整DataMemory(MB)=1024,IndexMemory(MB)=96
此時空間佔用情況變為: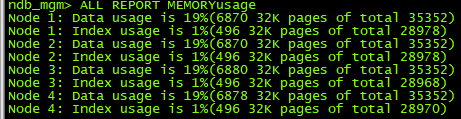 由此粗略估算,1G記憶體大概可存5百萬資料,資料庫伺服器記憶體32G~128G較為常見,按64G分配50G計算,可存2.5億行資料。
(僅做參考,實際記憶體消耗會受資料size、欄位型別blob或text、索引數量等綜合因素影響。測試表為磁碟儲存模式,如果是記憶體表則消耗加倍)
由此粗略估算,1G記憶體大概可存5百萬資料,資料庫伺服器記憶體32G~128G較為常見,按64G分配50G計算,可存2.5億行資料。
(僅做參考,實際記憶體消耗會受資料size、欄位型別blob或text、索引數量等綜合因素影響。測試表為磁碟儲存模式,如果是記憶體表則消耗加倍)
再測試讀寫效能,結果並沒有太大變化。
在測試檢索效能時,上面測試過的結果均沒有太大變化。 在百萬級資料行做字串like檢索時,ndbcluster23.507s,innodb9.617s完成,不可思議,不同欄位效果不同,估計與欄位定長有關。
總結:
ndbcluster在count上的表現碾壓innodb,但單機表引擎更換為MyISAM後,這個優勢就沒有了。
ndbcluster的定位是高可用,主要實現自動分片、分散式儲存、跨節點備份等功能。
作為應用端,比較關注的特性cluster都有所體現:伺服器橫向擴充套件能力,突破單機儲存瓶頸。cluster較好的完成了這個任務,可以動態調整資料節點。伺服器負載能力。cluster提供了多sql節點平衡負載。資料容災,硬體損壞造成資料丟失問題。通過跨節點備份最大降低資料丟失概率。高可用,個別服務異常,通過manager監聽服務自動切換,manager多節點互相監聽客戶端無感,不必大量修改sql即可支援。
單講每個特性都有相應代替方案,比入主從複製、讀寫分離、分庫分表、增量備份、keepalivevip漂移等。 mysqlcluster雖然較為全面,但總覺得力量不足,再三考慮後仍然放棄了投入生產。 最初考慮mysqlcluster主要從橫向擴充套件方面,但綜合考慮記憶體與效能方面的代價,還是不太適合當前的場景,當前對高可用需求不大,事物要求不高可用MyISAM引擎,容災能力通過主從複製及增量備份代替,磁碟問題採用多磁碟多分割槽方式過渡,如果資料量更大時再做其它考慮。