
Linux Raid相關知識
一、基本原理
RAID ( Redundant Array of Independent Disks )即獨立磁碟冗餘陣列,通常簡稱為磁碟陣列。簡單地說, RAID 是由多個獨立的高效能磁碟驅動器組成的磁碟子系統,從而提供比單個磁碟更高的儲存效能和資料冗餘的技術。 RAID 是一類多磁碟管理技術,其向主機環境提供了成本適中、資料可靠性高的高效能儲存。 SNIA 對 RAID 的定義是 [2] :一種磁碟陣列,部分物理儲存空間用來記錄儲存在剩餘空間上的使用者資料的冗餘資訊。當其中某一個磁碟或訪問路徑發生故障時,冗餘資訊可用來重建使用者資料。磁碟條帶化雖然與 RAID 定義不符,通常還是稱為 RAID (即 RAID0)。
RAID 的兩個關鍵目標是提高資料可靠性和 I/O 效能。磁碟陣列中,資料分散在多個磁碟中,然而對於計算機系統來說,就像一個單獨的磁碟。通過把相同資料同時寫入到多塊磁碟(典型地如映象),或者將計算的校驗資料寫入陣列中來獲得冗餘能力,當單塊磁碟出現故障時可以保證不會導致資料丟失。有些 RAID 等級允許更多地 磁碟同時發生故障,比如 RAID6 ,可以是兩塊磁碟同時損壞。在這樣的冗餘機制下,可以用新磁碟替換故障磁碟, RAID 會自動根據剩餘磁碟中的資料和校驗資料重建丟失的資料,保證資料一致性和完整性。資料分散儲存在 RAID 中的多個不同磁碟上,併發資料讀寫要大大優於單個磁碟,因此可以獲得更高的聚合 I/O 頻寬。當然,磁碟陣列會減少全體磁碟的總可用儲存空間,犧牲空間換取更高的可靠性和效能。比如, RAID1 儲存空間利用率僅有 50% , RAID5 會損失其中一個磁碟的儲存容量,空間利用率為 (n-1)/n 。 磁碟陣列可以在部分磁碟(單塊或多塊,根據實現而論)損壞的情況下,仍能保證系統不中斷地連續執行。在重建故障磁碟資料至新磁碟的過程中,系統可以繼續正常執行,但是效能方面會有一定程度上的降低。一些磁碟陣列在新增或刪除磁碟時必須停機,而有些則支援熱交換 ( Hot Swapping ),允許不停機下替換磁碟驅動器。這種高階磁碟陣列主要用於要求高可能性的應用系統,系統不能停機或儘可能少的停機時間。一般來說, RAID 不可作為資料備份的替代方案,它對非磁碟故障等造成的資料丟失無能為力,比如病毒、人為破壞、意外刪除等情形
(1) 大容量 這是 RAID 的一個顯然優勢,它擴大了磁碟的容量,由多個磁碟組成的 RAID 系統具有海量的儲存空間。一般來說, RAID 可用容量要小於所有成員磁碟的總容量。不同等級的 RAID 演算法需要一定的冗餘開銷,具體容量開銷與採用演算法相關。如果已知 RAID 演算法和容量,可以計算出 RAID 的可用容量。通常, RAID 容量利用率在 50% ~ 90% 之間。
(2) 高效能 RAID 的高效能受益於資料條帶化技術。單個磁碟的 I/O 效能受到介面、頻寬等計算機技術的限制,效能往往很有 限,容易成為系統性能的瓶頸。通過資料條帶化, RAID 將資料 I/O 分散到各個成員磁碟上,從而獲得比單個磁碟成倍增長的聚合 I/O 效能。
(3) 可靠性
(4) 可管理性 實際上, RAID 是一種虛擬化技術,它對多個物理磁碟驅動器虛擬成一個大容量的邏輯驅動器。對於外部主機系統來說, RAID 是一個單一的、快速可靠的大容量磁碟驅動器。這樣,使用者就可以在這個虛擬驅動器上來組織和儲存應用系統資料。 從使用者應用角度看,可使儲存系統簡單易用,管理也很便利。 由於 RAID 內部完成了大量的儲存管理工作,管理員只需要管理單個虛擬驅動器,可以節省大量的管理工作。 RAID 可以動態增減磁碟驅動器,可自動進行資料校驗和資料重建,這些都可以 大大簡化管理工作。
二、關鍵技術
2.1 映象
映象是一種冗餘技術,為磁碟提供保護功能,防止磁碟發生故障而造成資料丟失。對於 RAID 而言,採用映象技術 典型地 將會同時在陣列中產生兩個完全相同的資料副本,分佈在兩個不同的磁碟驅動器組上。映象提供了完全的資料冗餘能力,當一個數據副本失效不可用時,外部系統仍可正常訪問另一副本,不會對應用系統執行和效能產生影響。而且,映象不需要額外的計算和校驗,故障修復非常快,直接複製即可。映象技術可以從多個副本進行併發讀取資料,提供更高的讀 I/O 效能,但不能並行寫資料,寫多個副本會會導致一定的 I/O 效能降低。
映象技術提供了非常高的資料安全性,其代價也是非常昂貴的,需要至少雙倍的儲存空間。高成本限制了映象的廣泛應用,主要應用於至關重要的資料保護,這種場合下資料丟失會造成巨大的損失。另外,映象通過“ 拆分 ”能獲得特定時間點的上資料快照,從而可以實現一種備份視窗幾乎為零的資料備份技術。
2.2 資料條帶
磁碟儲存的效能瓶頸在於磁頭尋道定位,它是一種慢速機械運動,無法與高速的 CPU 匹配。再者,單個磁碟驅動器效能存在物理極限, I/O 效能非常有限。 RAID 由多塊磁碟組成,資料條帶技術將資料以塊的方式分佈儲存在多個磁碟中,從而可以對資料進行併發處理。這樣寫入和讀取資料就可以在多個磁碟上同時進行,併發產生非常高的聚合 I/O ,有效提高了整體 I/O 效能,而且具有良好的線性擴充套件性。這對大容量資料尤其顯著,如果不分塊,資料只能按順序儲存在磁碟陣列的磁碟上,需要時再按順序讀取。而通過條帶技術,可獲得數倍與順序訪問的效能提升。
資料條帶技術的分塊大小選擇非常關鍵。條帶粒度可以是一個位元組至幾 KB 大小,分塊越小,並行處理能力就越強,資料存取速度就越高,但同時就會增加塊存取的隨機性和塊定址時間。實際應用中,要根據資料特徵和需求來選擇合適的分塊大小,在資料存取隨機性和併發處理能力之間進行平衡,以爭取儘可能高的整體效能。 資料條帶是基於提高 I/O 效能而提出的,也就是說它只關注效能, 而對資料可靠性、可用性沒有任何改善。實際上,其中任何一個數據條帶損壞都會導致整個資料不可用,採用資料條帶技術反而增加了資料發生丟失的概念率。
2.3 資料校驗
映象具有高安全性、高讀效能,但冗餘開銷太昂貴。資料條帶通過併發性來大幅提高效能,然而對資料安全性、可靠性未作考慮。資料校驗是一種冗餘技術,它用校驗資料來提供資料的安全,可以檢測資料錯誤,並在能力允許的前提下進行資料重構。相對映象,資料校驗大幅縮減了冗餘開銷,用較小的代價換取了極佳的資料完整性和可靠性。資料條帶技術提供高效能,資料校驗提供資料安全性, RAID 不同等級往往同時結合使用這兩種技術。
採用資料校驗時, RAID 要在寫入資料同時進行校驗計算,並將得到的校驗資料儲存在 RAID 成員磁碟中。校驗資料可以集中儲存在某個磁碟或分散儲存在多個不同磁碟中,甚至校驗資料也可以分塊,不同 RAID 等級實現各不相同。當其中一部分資料出錯時,就可以對剩餘資料和校驗資料進行反校驗計算重建丟失的資料。校驗技術相對於映象技術的優勢在於節省大量開銷,但由於每次資料讀寫都要進行大量的校驗運算,對計算機的運算速度要求很高,必須使用硬體 RAID 控制器。在資料重建恢復方面,檢驗技術比映象技術複雜得多且慢得多。
海明校驗碼和 異或校驗是兩種最為常用的 資料校驗演算法。海明校驗碼是由理查德.海明提出的,不僅能檢測錯誤,還能給出錯誤位置並自動糾正。海明校驗的基本思想是:將有效資訊按照某種規律分成若干組,對每一個組作奇偶測試並安排一個校驗位,從而能提供多位檢錯資訊,以定位錯誤點並糾正。可見海明校驗實質上是一種多重奇偶校驗。異或校驗通過異或邏輯運算產生,將一個有效資訊與一個給定的初始值進行異或運算,會得到校驗資訊。如果有效資訊出現錯誤,通過校驗資訊與初始值的異或運算能還原正確的有效資訊。
三、Raid等級
標準 RAID 等級 SNIA 、 Berkeley 等組織機構把 RAID0 、 RAID1 、 RAID2 、 RAID3 、 RAID4 、 RAID5 、 RAID6 七個等級定為標準的 RAID 等級,這也被業界和學術界所公認。標準等級是最基本的 RAID 配置集合,單獨或綜合利用資料條帶、映象和資料校驗技術。標準 RAID 可以組合,即 RAID 組合等級,滿足 對效能、安全性、可靠性要求更高的儲存應用需求。 [6][7][8][9][10][11]
1.RAID0
RAID0 是一種簡單的、無資料校驗的資料條帶化技術。實際上不是一種真正的 RAID ,因為它並不提供任何形式的冗餘策略。 RAID0 將所在磁碟條帶化後組成大容量的儲存空間(如圖 2 所示),將資料分散儲存在所有磁碟中,以獨立訪問方式實現多塊磁碟的並讀訪問。由於可以併發執行 I/O 操作,匯流排頻寬得到充分利用。再加上不需要進行資料校驗,RAID0 的效能在所有 RAID 等級中是最高的。理論上講,一個由 n 塊磁碟組成的 RAID0 ,它的讀寫效能是單個磁碟效能的 n 倍,但由於匯流排頻寬等多種因素的限制,實際的效能提升低於理論值。
RAID0 具有低成本、高讀寫效能、 100% 的高儲存空間利用率等優點,但是它不提供資料冗餘保護,一旦資料損壞,將無法恢復。 因此, RAID0 一般適用於對效能要求嚴格但對資料安全性和可靠性不高的應用,如視訊、音訊儲存、臨時資料快取空間等。
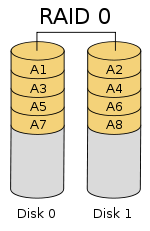 圖2 RAID0 :無冗錯的資料條帶
圖2 RAID0 :無冗錯的資料條帶
2.RAID1
RAID1 稱為映象,它將資料完全一致地分別寫到工作磁碟和映象 磁碟,它的磁碟空間利用率為 50% 。 RAID1 在資料寫入時,響應時間會有所影響,但是讀資料的時候沒有影響。 RAID1 提供了最佳的資料保護,一旦工作磁碟發生故障,系統自動從映象磁碟讀取資料,不會影響使用者工作。工作原理如圖 3 所示。
RAID1 與 RAID0 剛好相反,是為了增強資料安全性使兩塊 磁碟資料呈現完全映象,從而達到安全性好、技術簡單、管理方便。 RAID1 擁有完全容錯的能力,但實現成本高。 RAID1 應用於對順序讀寫效能要求高以及對資料保護極為重視的應用,如對郵件系統的資料保護。
 圖3 RAID1 :無校驗的相互映象
圖3 RAID1 :無校驗的相互映象
3.RAID2
RAID2 稱為糾錯海明碼磁碟陣列,其設計思想是利用海明碼實現資料校驗冗餘。海明碼是一種在原始資料中加入若干校驗碼來進行錯誤檢測和糾正的編碼技術,其中第 2n 位( 1, 2, 4, 8, … )是校驗碼,其他位置是資料碼。因此在 RAID2 中,資料按位儲存,每塊磁碟儲存一位資料編碼,磁碟數量取決於所設定的資料儲存寬度,可由使用者設定。圖 4 所示的為資料寬度為 4 的 RAID2 ,它需要 4 塊資料磁碟和 3 塊校驗磁碟。如果是 64 位資料寬度,則需要 64 塊 資料磁碟和 7 塊校驗磁碟。可見, RAID2 的資料寬度越大,儲存空間利用率越高,但同時需要的磁碟數量也越多。
海明碼自身具備糾錯能力,因此 RAID2 可以在資料發生錯誤的情況下對糾正錯誤,保證資料的安全性。它的資料傳輸效能相當高,設計複雜性要低於後面介紹的 RAID3 、 RAID4 和 RAID5 。
但是,海明碼的資料冗餘開銷太大,而且 RAID2 的資料輸出效能受陣列中最慢磁碟驅動器的限制。再者,海明碼是按位運算, RAID2 資料重建非常耗時。由於這些顯著的缺陷,再加上大部分磁碟驅動器本身都具備了糾錯功能,因此 RAID2 在實際中很少應用,沒有形成商業產品,目前主流儲存磁碟陣列均不提供 RAID2 支援。
 圖 4 RAID2 :海明碼校驗
圖 4 RAID2 :海明碼校驗
4.RAID3
RAID3 (圖 5 )是使用專用校驗盤的並行訪問陣列,它採用一個專用的磁碟作為校驗盤,其餘磁碟作為資料盤,資料按位可位元組的方式交叉儲存到各個資料盤中。RAID3 至少需要三塊磁碟,不同磁碟上同一帶區的資料作 XOR 校驗,校驗值寫入校驗盤中。 RAID3 完好時讀效能與 RAID0 完全一致,並行從多個磁碟條帶讀取資料,效能非常高,同時還提供了資料容錯能力。向 RAID3 寫入資料時,必須計算與所有同條帶的校驗值,並將新校驗值寫入校驗盤中。一次寫操作包含了寫資料塊、讀取同條帶的資料塊、計算校驗值、寫入校驗值等多個操作,系統開銷非常大,效能較低。
如果 RAID3 中某一磁碟出現故障,不會影響資料讀取,可以藉助校驗資料和其他完好資料來重建資料。假如所要讀取的資料塊正好位於失效磁碟,則系統需要讀取所有同一條帶的資料塊,並根據校驗值重建丟失的資料,系統性能將受到影響。當故障磁碟被更換後,系統按相同的方式重建故障盤中的資料至新磁碟。
RAID3 只需要一個校驗盤,陣列的儲存空間利用率高,再加上並行訪問的特徵,能夠為高頻寬的大量讀寫提供高效能,適用大容量資料的順序訪問應用,如影像處理、流媒體服務等。目前, RAID5 演算法不斷改進,在大資料量讀取時能夠模擬 RAID3 ,而且 RAID3 在出現壞盤時效能會大幅下降,因此常使用 RAID5 替代 RAID3 來執行具有持續性、高頻寬、大量讀寫特徵的應用。
 圖5 RAID3 :帶有專用位校驗的資料條帶
圖5 RAID3 :帶有專用位校驗的資料條帶
5.RAID4
RAID4 與 RAID3 的原理大致相同,區別在於條帶化的方式不同。 RAID4 (圖 6 )按照 塊的方式來組織資料,寫操作只涉及當前資料盤和校驗盤兩個盤,多個 I/O 請求可以同時得到處理,提高了系統性能。 RAID4 按塊儲存可以保證單塊的完整性,可以避免受到其他磁碟上同條帶產生的不利影響。
RAID4 在不同磁碟上的同級資料塊同樣使用 XOR 校驗,結果儲存在校驗盤中。寫入資料時, RAID4 按這種方式把各磁碟上的同級資料的校驗值寫入校驗 盤,讀取時進行即時校驗。因此,當某塊磁碟的資料塊損壞, RAID4 可以通過校驗值以及其他磁碟上的同級資料塊進行資料重建。
RAID4 提供了 非常好的讀效能,但單一的校驗盤往往成為系統性能的瓶頸。對於寫操作, RAID4 只能一個磁碟一個磁碟地寫,並且還要寫入校驗資料,因此寫效能比較差。而且隨著成員磁碟數量的增加,校驗盤的系統瓶頸將更加突出。正是如上這些限制和不足, RAID4 在實際應用中很少見,主流儲存產品也很少使用 RAID4 保護。
RAID 圖6 RAID4 :帶有專用塊級校驗的資料條帶
6.RAID5
RAID5 應該是目前最常見的 RAID 等級,它的原理與 RAID4 相似,區別在於校驗資料分佈在陣列中的所有磁碟上,而沒有采用專門的校驗磁碟。對於資料和校驗資料,它們的寫操作可以同時發生在完全不同的磁碟上。因此, RAID5 不存在 RAID4 中的併發寫操作時的校驗盤效能瓶頸問題。另外, RAID5 還具備很好的擴充套件性。當陣列磁碟 數量增加時,並行操作量的能力也隨之增長,可比 RAID4 支援更多的磁碟,從而擁有更高的容量以及更高的效能。
RAID5 (圖 7)的磁碟上同時儲存資料和校驗資料,資料塊和對應的校驗資訊存儲存在不同的磁碟上,當一個數據盤損壞時,系統可以根據同一條帶的其他資料塊和對應的校驗資料來重建損壞的資料。與其他 RAID 等級一樣,重建資料時, RAID5 的效能會受到較大的影響。
RAID5 兼顧儲存效能、資料安全和儲存成本等各方面因素,它可以理解為 RAID0 和 RAID1 的折中方案,是目前綜合性能最佳的資料保護解決方案。 RAID5 基本上可以滿足大部分的儲存應用需求,資料中心大多采用它作為應用資料的保護方案。
 圖7 RAID5 :帶分散校驗的資料條帶
圖7 RAID5 :帶分散校驗的資料條帶
7.RAID6
前面所述的各個 RAID 等級都只能保護因單個磁碟失效而造成的資料丟失。如果兩個磁碟同時發生故障,資料將無法恢復。 RAID6 (如圖 8 )引入雙重校驗的概念,它可以保護陣列中同時出現兩個磁碟失效時,陣列仍能夠繼續工作,不會發生資料丟失。 RAID6 等級是在 RAID5 的基礎上為了進一步增強資料保護而設計的一種 RAID 方式,它可以看作是一種擴充套件的 RAID5 等級。
RAID6 不僅要支援資料的恢復,還要支援校驗資料的恢復,因此實現代價很高,控制器的設計也比其他等級更復雜、更昂貴。 RAID6 思想最常見的實現方式是採用兩個獨立的校驗演算法,假設稱為 P 和 Q ,校驗資料可以分別儲存在兩個不同的校驗盤上,或者分散儲存在所有成員磁碟中。當兩個磁碟同時失效時,即可通過求解兩元方程來重建兩個磁碟上的資料。
RAID6 具有快速的讀取效能、更高的容錯能力。但是,它的成本要高於 RAID5 許多,寫效能也較差,並有設計和實施非常複雜。因此, RAID6 很少得到實際應用,主要用於對資料安全等級要求非常高的場合。它一般是替代 RAID10 方案的經濟性選擇。
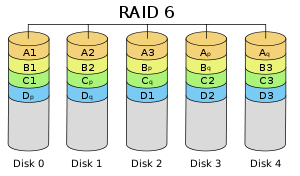 圖8 RAID6 :帶雙重分散校驗的資料條帶
圖8 RAID6 :帶雙重分散校驗的資料條帶
4.3 RAID 組合等級
標準 RAID 等級各有優勢和不足。自然地,我們想到把多個 RAID 等級組合起來,實現優勢互補,彌補相互的不足,從而達到在效能、資料安全性等指標上更高的 RAID 系統。目前在業界和學術研究中提到的 RAID 組合等級主要有 RAID00 、 RAID01 、 RAID10 、 RAID100 、 RAID30 、 RAID50 、 RAID53 、 RAID60 ,但實際得到較為廣泛應用的只有 RAID01 和 RAID10 兩個等級。當然,組合等級的實現成本一般都非常昂貴,只是在 少數特定場合應用。 [12]
1.RAID00
簡單地說, RAID00 是由多個成員 RAID0 組成的高階 RAID0 。它與 RAID0 的區別在於, RAID0 陣列替換了原先的成員磁碟。可以把 RAID00 理解為兩層條帶化結構的磁碟陣列,即對條帶再進行條帶化。這種陣列可以提供更大的儲存容量、更高的 I/O 效能和更好的 I/O 負均衡。
- RAID01 和 RAID10
一些文獻把這兩種 RAID 等級看作是等同的,本文認為是不同的。 RAID01 是先做條帶化再作映象,本質是對物理磁碟實現映象;而 RAID10 是先做映象再作條帶化,是對虛擬磁碟實現映象。相同的配置下,通常 RAID01 比 RAID10 具有更好的容錯能力,原理如圖 9 所示。
RAID01 兼備了 RAID0 和 RAID1 的優點,它先用兩塊磁碟建立映象,然後再在映象內部做條帶化。 RAID01 的資料將同時寫入到兩個磁碟陣列中,如果其中一個陣列損壞,仍可繼續工作,保證資料安全性的同時又提高了效能。 RAID01 和 RAID10 內部都含有 RAID1 模式,因此整體磁碟利用率均僅為 50% 。
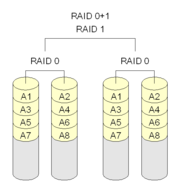
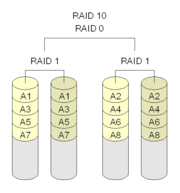 圖 9 典型的 RAID01 (上)和 RAID10 (下)模型
圖 9 典型的 RAID01 (上)和 RAID10 (下)模型
3.RAID100
通常看作 RAID 1+0+0 ,有時也稱為 RAID 10+0 ,即條帶化的 RAID10 。原理如圖 10 所示。 RAID100 的缺陷與 RAID10 相同,任意一個 RAID1 損壞一個磁碟不會發生資料丟失,但是剩下的磁碟存在單點故障的危險。最頂層的 RAID0 ,即條帶化任務,通常由軟體層來完成。
RAID100 突破了單個 RAID 控制器對物理磁碟數量的限制,可以獲得更高的 I/O 負載均衡, I/O 壓力分散到更多的磁碟上,進一步提高隨機讀效能,並有效降低熱點盤故障風險。因此, RAID100 通常是大資料庫的最佳選擇。
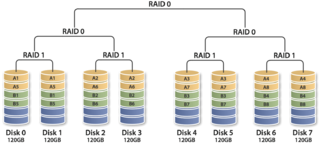 圖10 典型的 RAID100 模型
圖10 典型的 RAID100 模型
4.RAID30 ( RAID53 )、 RAID50 和 RAID60
這三種 RAID 等級與 RAID00 原理基本相同,區別在於成員 “ 磁碟 ” 換成了 RAID3 、 RAID5 和 RAID6 ,分別如圖 11 、 12 、 13 所示。其中, RAID30 通常又被稱為 RAID53[13] 。其實,可把這些等級 RAID 統稱為 RAID X0 等級, X 可為標準 RAID 等級,甚至組合等級(如 RAID100 )。利用多層 RAID 配置,充分利用 RAID X 與 RAID0 的優點,從而獲得在儲存容量、資料安全性和 I/O 負載均衡等方面的大幅效能提升。
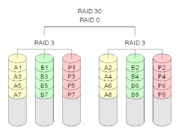 圖11 典型的 RAID30 模型
圖11 典型的 RAID30 模型
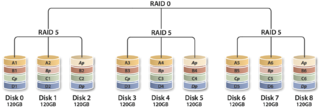 圖12 典型的 RAID50 模型
圖12 典型的 RAID50 模型
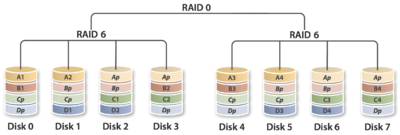 圖13 典型的 RAID60 模型
圖13 典型的 RAID60 模型
四、Raid實現方式
4.1軟RAID
軟 RAID 沒有專用的控制晶片和 I/O 晶片,完全由作業系統和 CPU 來實現所的 RAID 的功能。現代作業系統基本上都提供軟 RAID 支援,通過在磁碟裝置驅動程式上新增一個軟體層,提供一個物理驅動器與邏輯驅動器之間的抽象層。目前,作業系統支援的最常見的 RAID 等級有 RAID0 、 RAID1 、 RAID10 、 RAID01 和 RAID5 等。比如, Windows Server 支援 RAID0 、 RAID1 和 RAID5 三種等級, Linux 支援 RAID0 、 RAID1 、 RAID4 、 RAID5 、 RAID6 等, Mac OS X Server 、 FreeBSD 、 NetBSD 、 OpenBSD 、 Solaris 等作業系統也都支援相應的 RAID 等級。
軟 RAID 的配置管理和資料恢復都比較簡單,但是 RAID 所有任務的處理完全由 CPU 來完成,如計算校驗值,所以執行效率比較低下,這種方式需要消耗大量的運算資源,支援 RAID 模式較少,很難廣泛應用。
軟 RAID 由作業系統來實現,因此係統所在分割槽不能作為 RAID 的邏輯成員磁碟,軟 RAID 不能保護系統盤 D 。對於部分作業系統而言, RAID 的配置資訊儲存在系統資訊中,而不是單獨以檔案形式儲存在磁碟上。這樣當系統意外崩潰而需要重新安裝時, RAID 資訊就會丟失。另外,磁碟的容錯技術並不等於完全支援線上更換、熱插拔或熱交換,能否支援錯誤磁碟的熱交換與作業系統實現相關,有的作業系統熱交換。
4.2硬raid
硬 RAID 擁有自己的 RAID 控制處理與 I/O 處理晶片,甚至還有陣列緩衝,對 CPU 的佔用率和整體效能是三類實現中最優的,但實現成本也最高的。硬 RAID 通常都支援熱交換技術,在系統執行下更換故障磁碟。 硬 RAID 包含 RAID 卡和主機板上整合的 RAID 晶片, 伺服器平臺多采用 RAID 卡。 RAID 卡由 RAID 核心處理晶片( RAID 卡上的 CPU )、埠、快取和電池 4 部分組成。其中,埠是指 RAID 卡支援的磁碟介面型別,如 IDE/ATA 、 SCSI 、 SATA 、 SAS 、 FC 等介面。
4.3軟硬混合raid
軟 RAID 效能欠佳,而且不能保護系統分割槽,因此很難應用於桌面系統。而硬 RAID 成本非常昂貴,不同 RAID 相互獨立,不具互操作性。因此,人們採取軟體與硬體結合的方式來實現 RAID ,從而獲得在效能和成本上的一個折中,即較高的價效比。
這種 RAID 雖然採用了處理控制晶片,但是為了節省成本,晶片往往比較廉價且處理能力較弱, RAID 的任務處理大部分還是通過韌體驅動程式由 CPU 來完成。
五、Linux配置raid
5.1軟raid
5.1.1概念
mdadm是multiple devices admin的簡稱,它是Linux下的一款標準的軟體 RAID 管理工具,作者是Neil Brown
5.1.2特點
mdadm能夠診斷、監控和收集詳細的陣列資訊
mdadm是一個單獨整合化的程式而不是一些分散程式的集合,因此對不同RAID管理命令有共通的語法
mdadm能夠執行幾乎所有的功能而不需要配置檔案(也沒有預設的配置檔案)
5.1.3作用 (引用)
在linux系統中目前以MD(Multiple Devices)虛擬塊裝置的方式實現軟體RAID,利用多個底層的塊裝置虛擬出一個新的虛擬裝置,並且利用條帶化(stripping)技術將資料塊均勻分佈到多個磁碟上來提高虛擬裝置的讀寫效能,利用不同的資料冗祭演算法來保護使用者資料不會因為某個塊裝置的故障而完全丟失,而且還能在裝置被替換後將丟失的資料恢復到新的裝置上.
目前MD支援linear,multipath,raid0(stripping),raid1(mirror),raid4,raid5,raid6,raid10等不同的冗餘級別和級成方式,當然也能支援多個RAID陳列的層疊組成raid1 0,raid5 1等型別的陳列
5.1.4.實驗
試題:建立4個大小為1G的磁碟,並將其中3個建立為raid5的陣列磁碟,1個為熱備份磁碟。測試熱備份磁碟替換陣列中的磁碟並同步資料。移除損壞的磁碟,新增一個新磁碟作為熱備份磁碟。最後要求開機自動掛載。
5.1.4.1建立磁碟
[[email protected] ~]# fdisk /dev/sda
WARNING: DOS-compatible mode is deprecated. It’s strongly recommended to switch off the mode (command ‘c’) and change display units to sectors (command ‘u’). Command (m for help): n First cylinder (10486-13054, default 10486): Using default value 10486 Last cylinder, +cylinders or +size{K,M,G} (10486-13054, default 13054): +1G
Command (m for help): n First cylinder (10618-13054, default 10618): Using default value 10618 Last cylinder, +cylinders or +size{K,M,G} (10618-13054, default 13054): +1G
Command (m for help): n First cylinder (10750-13054, default 10750): Using default value 10750 Last cylinder, +cylinders or +size{K,M,G} (10750-13054, default 13054): +1G
Command (m for help): n First cylinder (10882-13054, default 10882): Using default value 10882 Last cylinder, +cylinders or +size{K,M,G} (10882-13054, default 13054): +1G
Command (m for help): t Partition number (1-8): 8 Hex code (type L to list codes): fd Changed system type of partition 8 to fd (Linux raid autodetect)
Command (m for help): t Partition number (1-8): 7 Hex code (type L to list codes): fd Changed system type of partition 7 to fd (Linux raid autodetect)
Command (m for help): t Partition number (1-8): 6 Hex code (type L to list codes): fd Changed system type of partition 6 to fd (Linux raid autodetect)
Command (m for help): t Partition number (1-8): 5 Hex code (type L to list codes): fd Changed system type of partition 5 to fd (Linux raid autodetect)
Command (m for help): p
Disk /dev/sda: 107.4 GB, 107374182400 bytes 255 heads, 63 sectors/track, 13054 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x0008ed57
Device Boot Start End Blocks Id System /dev/sda1 * 1 26 204800 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 26 10225 81920000 83 Linux /dev/sda3 10225 10486 2097152 82 Linux swap / Solaris /dev/sda4 10486 13054 20633279 5 Extended /dev/sda5 10486 10617 1058045 fd Linux raid autodetect /dev/sda6 10618 10749 1060258+ fd Linux raid autodetect /dev/sda7 10750 10881 1060258+ fd Linux raid autodetect /dev/sda8 10882 11013 1060258+ fd Linux raid autodetect
Command (m for help): w The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: 裝置或資源忙. The kernel still uses the old table. The new table will be used at the next reboot or after you run partprobe(8) or kpartx(8) Syncing disks.
5.1.4.2載入核心
[[email protected] ~]# partx -a /dev/sda5 /dev/sda [[email protected] ~]# partx -a /dev/sda6 /dev/sda [[email protected] ~]# partx -a /dev/sda7 /dev/sda [[email protected] ~]# partx -a /dev/sda8 /dev/sda
5.1.4.3建立raid5及其熱備份盤
[[email protected] ~]# mdadm -C /dev/md0 -l 5 -n 3 -x 1 /dev/sda{5,6,7,8} mdadm: /dev/sda5 appears to be part of a raid array: level=raid5 devices=3 ctime=Wed Dec 17 00:58:24 2014 mdadm: /dev/sda6 appears to be part of a raid array: level=raid5 devices=3 ctime=Wed Dec 17 00:58:24 2014 mdadm: /dev/sda7 appears to be part of a raid array: level=raid5 devices=3 ctime=Wed Dec 17 00:58:24 2014 mdadm: /dev/sda8 appears to be part of a raid array: level=raid5 devices=3 ctime=Wed Dec 17 00:58:24 2014 Continue creating array? y mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started.
5.1.4.4初始化時間和磁碟陣列的讀寫的應用相關,使用cat /proc/mdstat資訊查詢RAID陣列當前重構的速度和預期的完成時間。
[[email protected] ~]# cat /proc/mdstat Personalities : [raid1] [raid0] [raid6] [raid5] [raid4] md0 : active raid5 sda7[4] sda83 sda6[1] sda5[0] 2113536 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [UU_] [=========>…] recovery = 45.5% (482048/1056768) finish=0.3min speed=30128K/sec
unused devices: [[email protected] ~]# cat /proc/mdstat Personalities : [raid1] [raid0] [raid6] [raid5] [raid4] md0 : active raid5 sda7[4] sda83 sda6[1] sda5[0] 2113536 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
unused devices:
[[email protected] ~]# mke2fs -t ext3 /dev/md0 //格式化raid
5.1.4.5掛載raid到/mnt目錄下,並檢視是否正常(顯示lost+found為正常)
[[email protected] ~]# mount /dev/md0 /mnt [[email protected] ~]# ls /mnt lost+found
5.1.4.6檢視raid陣列的詳細資訊
[[email protected] ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Wed Dec 17 03:38:08 2014 Raid Level : raid5 Array Size : 2113536 (2.02 GiB 2.16 GB) Used Dev Size : 1056768 (1032.17 MiB 1082.13 MB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent
Update Time : Wed Dec 17 03:55:11 2014
State : clean
Active Devices : 3 Working Devices : 4 Failed Devices : 0 Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Name : xiao:0 (local to host xiao)
UUID : bce110f2:34f3fbf1:8de472ed:633a374f
Events : 18
Number Major Minor RaidDevice State
0 8 5 0 active sync /dev/sda5
1 8 6 1 active sync /dev/sda6
4 8 7 2 active sync /dev/sda7
3 8 8 - spare /dev/sda8
5.1.4.7模擬損壞其中的一個磁碟,這裡我選擇 /dev/sda6磁碟
[[email protected] ~]# mdadm /dev/md0 --fail /dev/sda6 mdadm: set /dev/sda6 faulty in /dev/md0
5.1.4.8檢視raid陣列詳細資訊,發現/dev/sda8自動替換了損壞的/dev/sda6磁碟。
[[email protected] ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Wed Dec 17 03:38:08 2014 Raid Level : raid5 Array Size : 2113536 (2.02 GiB 2.16 GB) Used Dev Size : 1056768 (1032.17 MiB 1082.13 MB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent
Update Time : Wed Dec 17 04:13:59 2014
State : clean, degraded, recovering
Active Devices : 2 Working Devices : 3 Failed Devices : 1 Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Rebuild Status : 43% complete
Name : xiao:0 (local to host xiao)
UUID : bce110f2:34f3fbf1:8de472ed:633a374f
Events : 26
Number Major Minor RaidDevice State
0 8 5 0 active sync /dev/sda5
3 8 8 1 spare rebuilding /dev/sda8
4 8 7 2 active sync /dev/sda7
1 8 6 - faulty /dev/sda6
[[email protected] ~]# cat /proc/mdstat Personalities : [raid1] [raid0] [raid6] [raid5] [raid4] md0 : active raid5 sda7[4] sda8[3] sda61 sda5[0] 2113536 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU] #正常的情況會是[UUU],若第一個磁碟損壞則顯示[ _UU ].
5.1.4.9 移除損壞的硬碟
[[email protected] ~]# mdadm /dev/md0 -r /dev/sda6 mdadm: hot removed /dev/sda6 from /dev/md0
5.1.4.10新增一個新硬碟作為熱備份盤
[[email protected] ~]# fdisk /dev/sda
WARNING: DOS-compatible mode is deprecated. It’s strongly recommended to switch off the mode (command ‘c’) and change display units to sectors (command ‘u’).
Command (m for help): n First cylinder (11014-13054, default 11014): Using default value 11014 Last cylinder, +cylinders or +size{K,M,G} (11014-13054, default 13054): +1G
Command (m for help): t Partition number (1-9): 9 Hex code (type L to list codes): fd Changed system type of partition 9 to fd (Linux raid autodetect)
Command (m for help): p
Disk /dev/sda: 107.4 GB, 107374182400 bytes 255 heads, 63 sectors/track, 13054 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x0008ed57
Device Boot Start End Blocks Id System /dev/sda1 * 1 26 204800 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 26 10225 81920000 83 Linux /dev/sda3 10225 10486 2097152 82 Linux swap / Solaris /dev/sda4 10486 13054 20633279 5 Extended /dev/sda5 10486 10617 1058045 fd Linux raid autodetect /dev/sda6 10618 10749 1060258+ fd Linux raid autodetect /dev/sda7 10750 10881 1060258+ fd Linux raid autodetect /dev/sda8 10882 11013 1060258+ fd Linux raid autodetect /dev/sda9 11014 11145 1060258+ fd Linux raid autodetect
Command (m for help): w The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: 裝置或資源忙. The kernel still uses the old table. The new table will be used at the next reboot or after you run partprobe(8) or kpartx(8) Syncing disks. [[email protected] ~]# partx -a /dev/sda9 /dev/sda
[[email protected] ~]# mdadm /dev/md0 --add /dev/sda9 mdadm: added /dev/sda9
[[email protected] ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Wed Dec 17 03:38:08 2014 Raid Level : raid5 Array Size : 2113536 (2.02 GiB 2.16 GB) Used Dev Size : 1056768 (1032.17 MiB 1082.13 MB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent
Update Time : Wed Dec 17 04:39:35 2014
State : clean
Active Devices : 3 Working Devices : 4 Failed Devices : 0 Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Name : xiao:0 (local to host xiao)
UUID : bce110f2:34f3fbf1:8de472ed:633a374f
Events : 41
Number Major Minor RaidDevice State
0 8 5 0 active sync /dev/sda5
3 8 8 1 active sync /dev/sda8
4 8 7 2 active sync /dev/sda7
5 8 9 - spare /dev/sda9
5.1.4.11開機自動掛載
編輯/etc/fsab檔案 /dev/md0 /mnt ext4 defaults 0 0 :wq
5.2硬raid
5.2.1硬raid的刪除
1.當BIOS啟動到如圖4-1所示畫面時,按Ctrl + C鍵,進入raid卡的選擇介面,如圖所示。
 BIOS啟動介面
BIOS啟動介面
 raid卡選擇介面
2.選擇“LSI2308-IR”,進入到RAID配置首頁,如圖4-3所示。
raid卡選擇介面
2.選擇“LSI2308-IR”,進入到RAID配置首頁,如圖4-3所示。
 3.刪除RAID
在RAID配置主介面,依次選擇RAID Properties->View Existing Array
3.刪除RAID
在RAID配置主介面,依次選擇RAID Properties->View Existing Array
 已存在raid資訊
選擇Manage Array 出現以下介面:
已存在raid資訊
選擇Manage Array 出現以下介面:
 刪除raid
選擇Delete Array,可刪除RAID 陣列。
刪除raid
選擇Delete Array,可刪除RAID 陣列。