
Python 氣象資料分析
資料分析例項 -- 氣象資料
一、實驗介紹
本實驗將對義大利北部沿海地區的氣象資料進行分析與視覺化。我們在實驗過程中先會運用 Python 中matplotlib庫的對資料進行圖表化處理,然後呼叫 scikit-learn 庫當中的的 SVM 庫對資料進行迴歸分析,最終在圖表分析的支援下得出我們的結論。
1.1 課程來源
本課程基於 圖靈教育 的 《Python資料分析實戰》 第2章製作,感謝 圖靈教育 授權實驗樓釋出。如需系統的學習本書,請購買《Python資料分析實戰》。
為了保證可以在實驗樓環境中完成本次實驗,我們在原書內容基礎上補充了一系列的實驗指導,比如實驗截圖,程式碼註釋,幫助您更好得實戰。
如果您對於實驗有疑惑或者建議可以隨時在討論區中提問,與同學們一起探討。
1.2 實驗知識點
- matplotlib 庫畫出影象
- scikit-learn 庫對資料進行迴歸分析
- numpy 庫對資料進行切片
1.3 實驗環境
- python2.7
- spyder
- Xfce終端
1.4 適合人群
本課程難度為中等,適合具有Python基礎的使用者,如果對 matplotlib 模組有了解會更快的上手。
1.5 程式碼獲取
你可以通過下面命令將程式碼下載到實驗樓環境中,作為參照對比進行學習。
$ wget http://labfile.oss.aliyuncs.com/courses/780/SourceCode.zip$ wget http://labfile.oss.aliyuncs.com/courses/780/WeatherData.zip
本實驗在互動式的環境當中完成,程式碼不能直接在命令列中執行(因為要畫圖)。如果想要看效果的同學可以把 SourceCode.zip 和 WeatherData.zip解壓,然後開啟桌面上的 spyder, 在Ipython console的互動式環境中進入WeatherData所在路徑,然後把程式碼黏貼到 console 當中去。具體方式請看如下的 gif 圖。
在這裡還是要呼籲大家不要簡單的複製貼上程式碼,還是要依照本實驗的教程自己一步步得實現。
二、實驗原理
氣象資料是在網上很容易找到的一類資料。很多網站都提供以往的氣壓、氣溫、溼度和降雨量等氣象資料。只需指定位置和日期,就能獲取一個氣象資料檔案。這些測量資料是由氣象站收集的。氣象資料這類資料來源涵蓋的資訊範圍較廣。資料分析的目的是把原始資料轉化為資訊,再把資訊轉化為知識,因此拿氣象資料作為資料分析的物件來講解資料分析全過程再合適不過。
2.1 待檢驗的假設:靠海對氣候的影響
寫作本章時,雖正值夏初,卻已酷熱難耐,住在大城市的人感受更為強烈。於是週末很多人到山村或海濱城市去遊玩,放鬆一下身心,遠離內陸城市的悶熱天氣。我常常想,靠海對氣候有什麼影響?這個問題可以作為資料分析的一個不錯的出發點。我不想把本章寫成科學類讀物,只是想借助這樣一種方式,讓資料分析愛好者能夠把所學用於實踐,解決“海洋對一個地區的氣候有何影響”這個問題。
研究系統:亞得里亞海和波河流域
既然已定義好問題,就需要尋找適合研究資料的系統,提供適合回答這個問題的環境。首先,需要找到一片海域供你研究。我住在義大利,可選擇的海有很多,因為義大利是一個被海洋包圍的半島國家。為什麼要把自己的選擇侷限在義大利呢?因為我們所研究的問題剛好和義大利人的一種典行為相關,也就是夏天我們喜歡躲在海邊,以躲避內陸的酷熱。我不知道在其他國家這種行為是否也很普遍,因此我只把自己熟悉的義大利作為一個系統進行研究。但是你可能會考慮研究義大利的哪個地區呢?上面說過,義大利是半島國家,找到可研究的海域不是問題,但是如何衡量海洋對其遠近不同的地方的影響?這就引出了一個大問題。義大利其實多山地,離海差不多遠,可以彼此作為參照的內陸區域較少。為了衡量海洋對氣候的影響,我排除了山地,因為山地也許會引入其他很多因素,比如海拔。
義大利波河流域這塊區域就很適合研究海洋對氣候的影響。這一片平原東起亞得里亞海,向內陸延伸數百公里(見圖9-1)。它周邊雖不乏群山環繞,但由於它很寬廣,削弱了群山的影響。此外,該區域城鎮密集,也便於選取一組離海遠近不同的城市。我們所選的幾個城市,兩個城市間的最大距離約為400公里。

第一步,選10個城市作為參照組。選擇城市時,注意它們要能代表整個平原地區(見圖9-2)。

如圖9-2所示,我們選取了10個城市。隨後將分析它們的天氣資料,其中5個城市在距海100公里範圍內,其餘5個距海100~400公里。
選作樣本的城市列表如下:
- Ferrara(費拉拉)
- Torino(都靈)
- Mantova(曼託瓦)
- Milano(米蘭)
- Ravenna(拉文納)
- Asti(阿斯蒂)
- Bologna(博洛尼亞)
- Piacenza(皮亞琴察)
- Cesena(切塞納)
- Faenza(法恩莎)
現在,我們需要弄清楚這些城市離海有多遠。方法有多種。這裡使用TheTimeNow網站提供的服務,它支援多種語言(見圖9-3)。

有了計算兩城市間距離這樣的服務,我們就可以計算每個城市與海之間的距離。你可以選擇 海濱城市Comacchio作為基點,計算其他城市與它之間的距離(見圖9-2)。使用上述服務計算完 所有距離後,得到的結果如表9-1所示。


三、開發準備
定義好要研究的系統之後,我們就需要建立資料來源,以獲取研究所需的資料。上網瀏覽一番,你就會發現很多網站都提供世界各地的氣象資料,其中就有Open Weather Map,它的網址是 http://openweathermap.org/ (見圖9-4)。


該網站提供以下功能:在請求的URL中指定城市,即可獲取該城市的氣象資料。我們已經準備好了資料,不需要大家再去呼叫該網站的 API。
啟動桌面上的spyder。如果您發現您桌面上沒有spyder,請在該實驗中重新開一個實驗環境(實驗樓為不同的實驗建立不同的實驗環境):


我們首先來獲取我們的資料檔案。開啟 Xfce 終端
$ cd Code$ mkdir WeatherAnalysis$ cd WeatherAnalysis$ wget http://labfile.oss.aliyuncs.com/courses/780/WeatherData.zip$ unzip WeatherData.zip這時候應該能夠再 WeatherData 中間看到 10 個城市的天氣資料檔案(以 .csv 結尾)
雙擊開啟 spyder ,在 Ipython Console 中進入我們的目標目錄
cd Codecd WeatherAnalysiscd WeatherData我們在實驗裡只需要用到 Ipython Console 所以別的不相關的視窗可以關閉。

import numpy as npimport pandas as pdimport datetime如果你想用本章的資料,需要載入寫作本章時儲存的10個CSV檔案。
df_ferrara = pd.read_csv('ferrara_270615.csv')df_milano = pd.read_csv('milano_270615.csv')df_mantova = pd.read_csv('mantova_270615.csv')df_ravenna = pd.read_csv('ravenna_270615.csv')df_torino = pd.read_csv('torino_270615.csv')df_asti = pd.read_csv('asti_270615.csv')df_bologna = pd.read_csv('bologna_270615.csv')df_piacenza = pd.read_csv('piacenza_270615.csv')df_cesena = pd.read_csv('cesena_270615.csv')df_faenza = pd.read_csv('faenza_270615.csv')我們把這些資料讀入記憶體,完成了實驗準備的部分。
四、專案檔案結構

Pic9-* 代表的是每一張分析圖所使用的程式碼。
WeatherData 是我們的資料。
五、實驗步驟
從資料視覺化入手分析收集到的資料是常見的做法。前面講過,matplotlib庫提供一系列圖表生成工具,能夠以視覺化形式表示資料。資料視覺化在資料分析階段非常有助於發現研究系統的一些特點。
匯入以下必要的庫:
%matplotlib inlineimport matplotlib.pyplot as pltimport matplotlib.dates as mdatesfrom dateutil import parser5.1 溫度資料分析
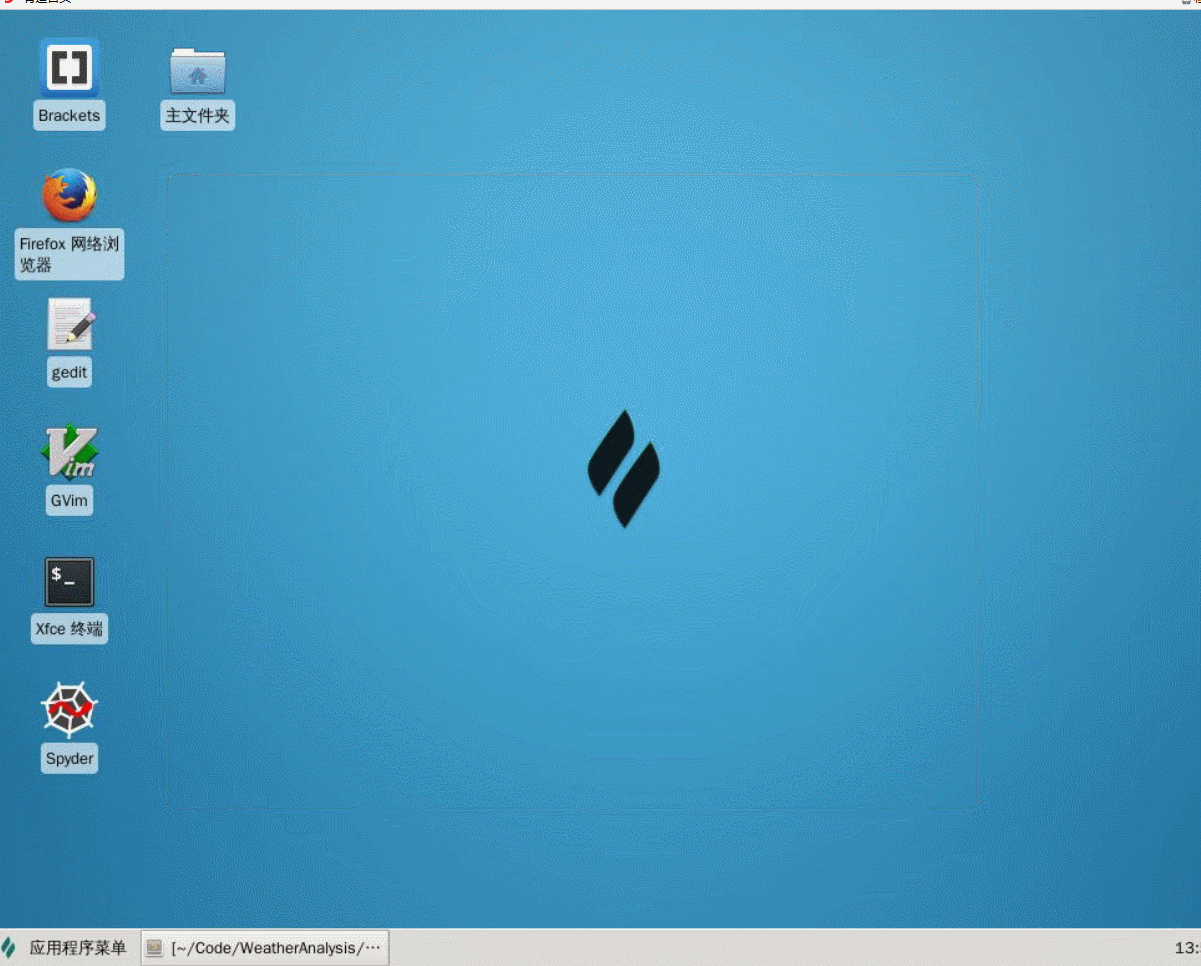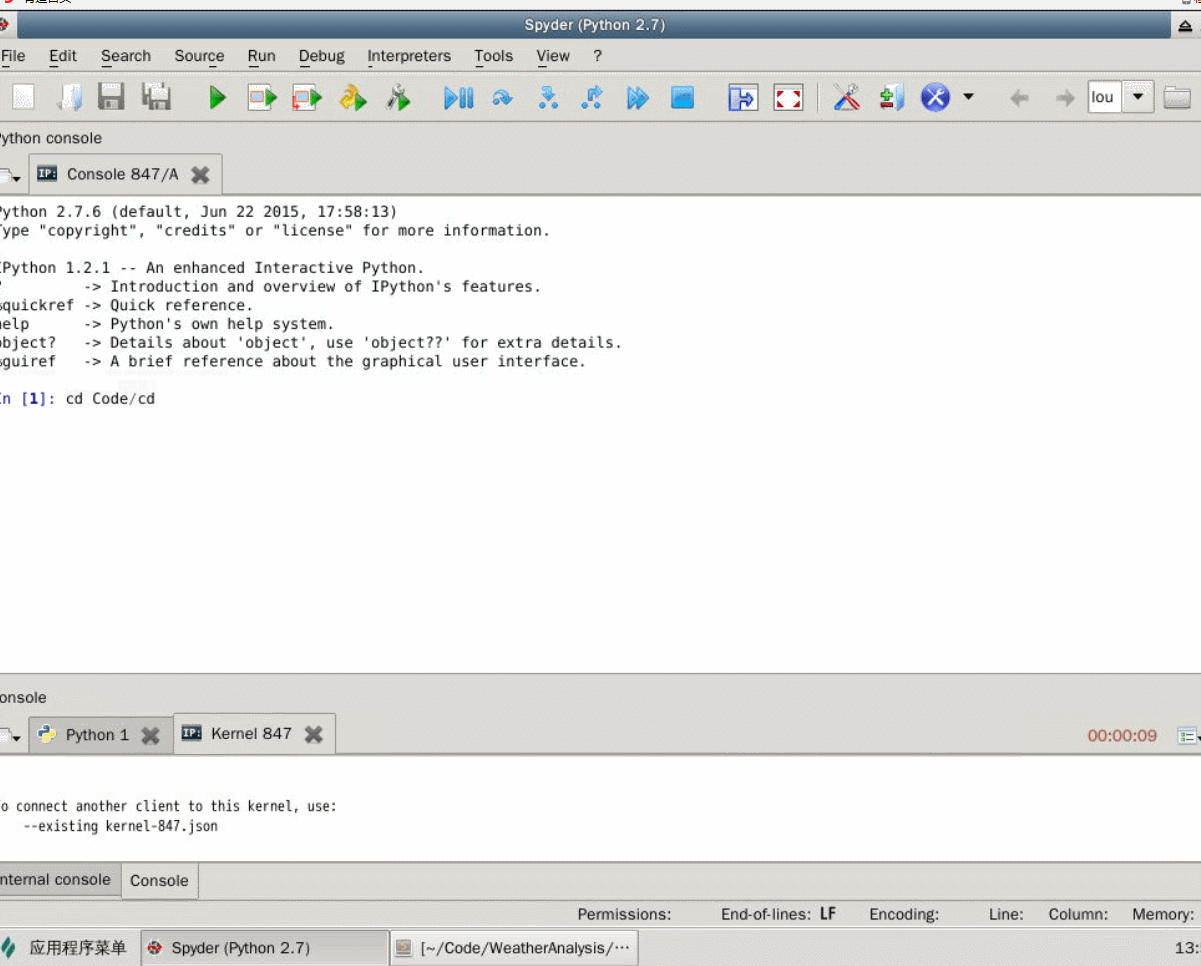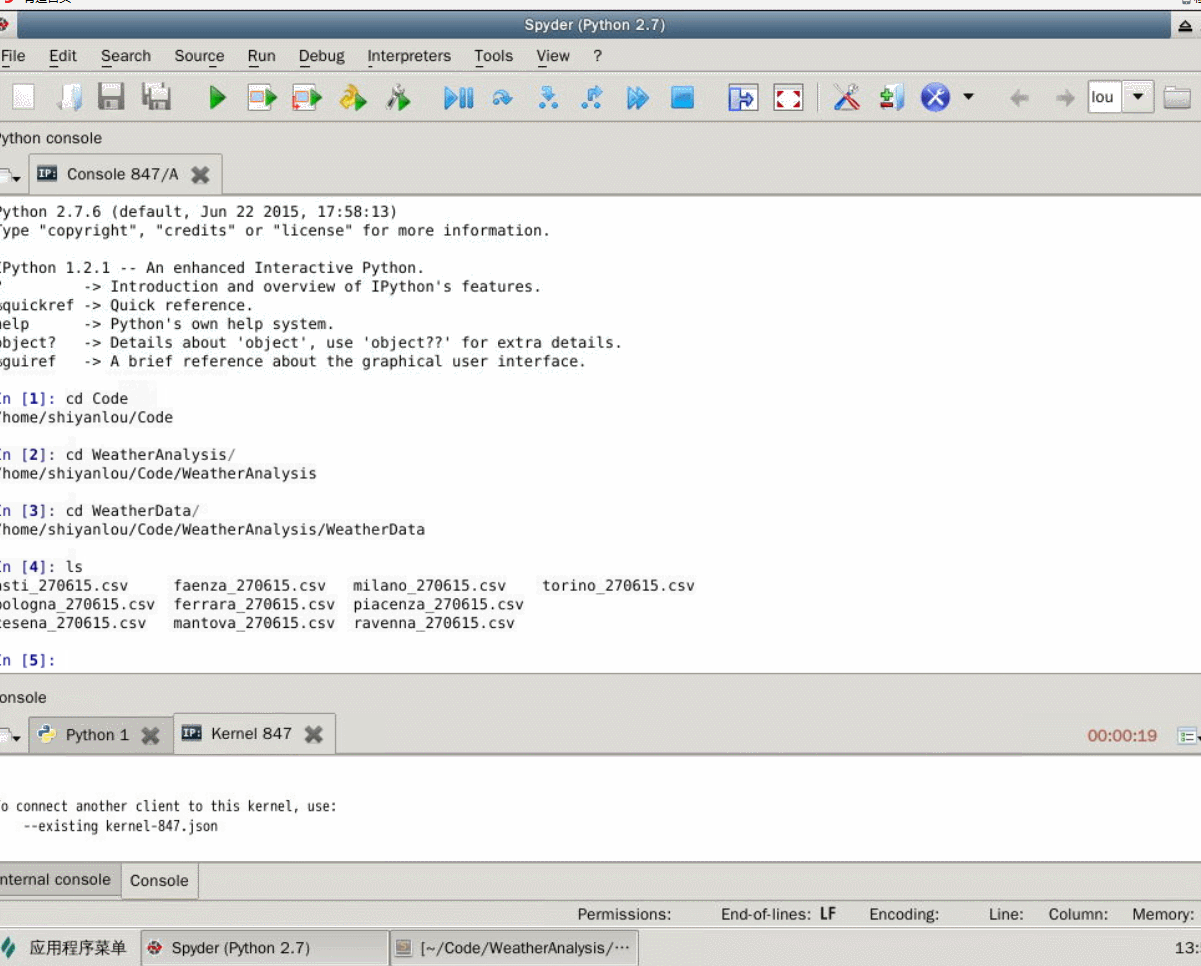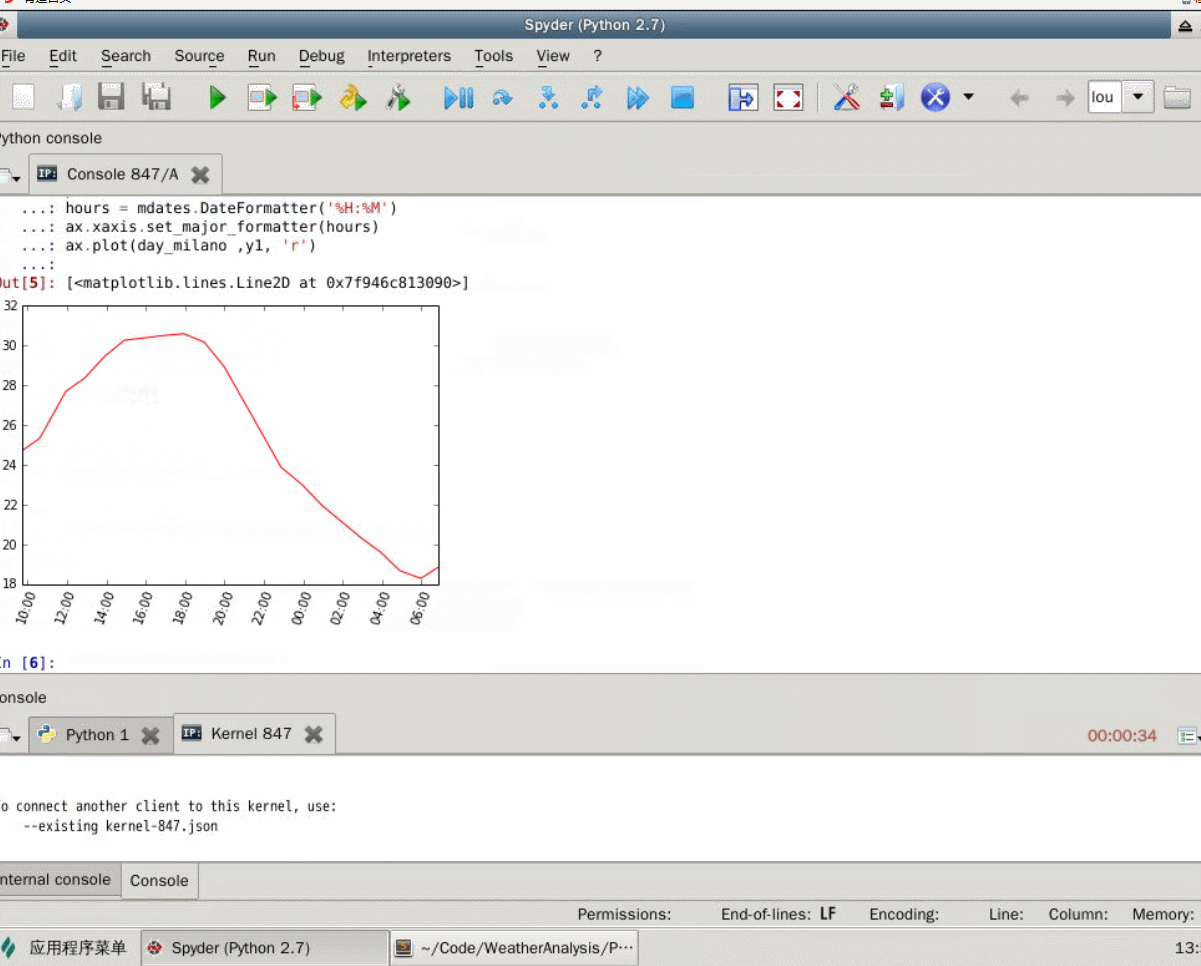
舉例來說,非常簡單的分析方法是先分析一天中氣溫的變化趨勢。我們以城市米蘭為例。
# 讀取米蘭的城市氣象資料df_milano = pd.read_csv('milano_270615.csv')# 取出我們要分析的溫度和日期資料y1 = df_milano['temp']x1 = df_milano['day']# 把日期資料轉換成 datetime 的格式day_milano = [parser.parse(x) for x in x1]# 呼叫 subplot 函式, fig 是影象物件,ax 是座標軸物件fig, ax = plt.subplots()# 調整x軸座標刻度,使其旋轉70度,方便檢視plt.xticks(rotation=70)# 設定時間的格式hours = mdates.DateFormatter('%H:%M')# 設定X軸顯示的格式ax.xaxis.set_major_formatter(hours)# 畫出影象,day_milano是X軸資料,y1是Y軸資料,‘r’代表的是'red' 紅色ax.plot(day_milano ,y1, 'r')# 顯示影象fig執行上述程式碼,將得到如圖9-8所示的影象。由圖可見,氣溫走勢接近正弦曲線,從早上開始氣溫逐漸升高,最高溫出現在下午兩點到六點之間,隨後氣溫逐漸下降,在第二天早上六點時達到最低值。


我們進行資料分析的目的是嘗試解釋是否能夠評估海洋是怎樣影響氣溫的,以及是否能夠影響氣溫趨勢,因此我們同時來看幾個不同城市的氣溫趨勢。這是檢驗分析方向是否正確的唯一方式。因此,我們選擇三個離海最近以及三個離海最遠的城市。
# 讀取資料檔案(之前沒讀取資料的同學,這裡一定要讀取啦)df_ravenna = pd.read_csv('ravenna_270615.csv')df_faenza = pd.read_csv('faenza_270615.csv')df_cesena = pd.read_csv('cesena_270615.csv')df_asti = pd.read_csv('asti_270615.csv')df_torino = pd.read_csv('torino_270615.csv')df_milano = pd.read_csv('milano_270615.csv')# 讀取溫度和日期資料y1 = df_ravenna['temp']x1 = df_ravenna['day']y2 = df_faenza['temp']x2 = df_faenza['day']y3 = df_cesena['temp']x3 = df_cesena['day']y4 = df_milano['temp']x4 = df_milano['day']y5 = df_asti['temp']x5 = df_asti['day']y6 = df_torino['temp']x6 = df_torino['day']# 把日期從 string 型別轉化為標準的 datetime 型別day_ravenna = [parser.parse(x) for x in x1]day_faenza = [parser.parse(x) for x in x2]day_cesena = [parser.parse(x) for x in x3]dat_milano = [parser.parse(x) for x in x4]day_asti = [parser.parse(x) for x in x5]day_torino = [parser.parse(x) for x in x6]# 呼叫 subplots() 函式,重新定義 fig, ax 變數fig, ax = plt.subplots()plt.xticks(rotation=70)hours = mdates.DateFormatter('%H:%M')ax.xaxis.set_major_formatter(hours)#這裡需要畫出三根線,所以需要三組引數, 'g'代表'green'ax.plot(day_ravenna,y1,'r',day_faenza,y2,'r',day_cesena,y3,'r')ax.plot(dat_milano,y4,'g',day_asti,y5,'g',day_torino,y6,'g')fig上述程式碼將生成如圖9-9所示的圖表。離海最近的三個城市的氣溫曲線使用紅色,而離海最遠的三個城市的曲線使用綠色。


如圖9-9所示,結果看起來不錯。離海最近的三個城市的最高氣溫比離海最遠的三個城市低不少,而最低氣溫看起來差別較小。
我們可以沿著這個方向做深入研究,收集10個城市的最高溫和最低溫,用線性圖表示氣溫最值點和離海遠近之間的關係。
# dist 是一個裝城市距離海邊距離的列表dist = [df_ravenna['dist'][0], df_cesena['dist'][0], df_faenza['dist'][0], df_ferrara['dist'][0], df_bologna['dist'][0], df_mantova['dist'][0], df_piacenza['dist'][0], df_milano['dist'][0], df_asti['dist'][0], df_torino['dist'][0]]# temp_max 是一個存放每個城市最高溫度的列表temp_max = [df_ravenna['temp'].max(), df_cesena['temp'].max(), df_faenza['temp'].max(), df_ferrara['temp'].max(), df_bologna['temp'].max(), df_mantova['temp'].max(), df_piacenza['temp'].max(), df_milano['temp'].max(), df_asti['temp'].max(), df_torino['temp'].max()]# temp_min 是一個存放每個城市最低溫度的列表temp_min = [df_ravenna['temp'].min(), df_cesena['temp'].min(), df_faenza['temp'].min(), df_ferrara['temp'].min(), df_bologna['temp'].min(), df_mantova['temp'].min(), df_piacenza['temp'].min(), df_milano['temp'].min(), df_asti['temp'].min(), df_torino['temp'].min()]先把最高溫畫出來。
fig, ax = plt.subplots()ax.plot(dist,temp_max,'ro')fig結果如圖9-10所示。


如圖9-10所示,現在你可以證實,海洋對氣象資料具有一定程度的影響這個假設是正確的(至 少這一天如此)。
進一步觀察上圖,你會發現海洋的影響衰減得很快,離海60~70公里開外,氣溫就已攀升到 高位。
用線性迴歸演算法得到兩條直線,分別表示兩種不同的氣溫趨勢,這樣做很有趣。我們可以使 用scikit-learn庫的SVR方法。(注意:這段程式碼會跑比較久的時間)
from sklearn.svm import SVR# dist1是靠近海的城市集合,dist2是遠離海洋的城市集合dist1 = dist[0:5]dist2 = dist[5:10]# 改變列表的結構,dist1現在是5個列表的集合# 之後我們會看到 numpy 中 reshape() 函式也有同樣的作用dist1 = [[x] for x in dist1]dist2 = [[x] for x in dist2]# temp_max1 是 dist1 中城市的對應最高溫度temp_max1 = temp_max[0:5]# temp_max2 是 dist2 中城市的對應最高溫度temp_max2 = temp_max[5:10]# 我們呼叫SVR函式,在引數中規定了使用線性的擬合函式# 並且把 C 設為1000來儘量擬合數據(因為不需要精確預測不用擔心過擬合)svr_lin1 = SVR(kernel='linear', C=1e3)svr_lin2 = SVR(kernel='linear', C=1e3)# 加入資料,進行擬合(這一步可能會跑很久,大概10多分鐘,休息一下:) )svr_lin1.fit(dist1, temp_max1)svr_lin2.fit(dist2, temp_max2)# 關於 reshape 函式請看程式碼後面的詳細討論xp1 = np.arange(10,100,10).reshape((9,1))xp2 = np.arange(50,400,50).reshape((7,1))yp1 = svr_lin1.predict(xp1)yp2 = svr_lin2.predict(xp2)# 限制了 x 軸的取值範圍ax.set_xlim(0,400)# 畫出影象ax.plot(xp1, yp1, c='b', label='Strong sea effect')ax.plot(xp2, yp2, c='g', label='Light sea effect')fig這裡 np.arange(10,100,10) 會返回 [10, 20, 30,..., 90],如果把列表看成是一個矩陣,那麼這個矩陣是 1 9 的。這裡 reshape((9,1)) 函式就會把該列表變為 1 9 的, [[10], [20], ..., [90]]。這麼做的原因是因為 predict() 函式的只能接受一個 N 1 的列表,返回一個 1 N 的列表。
上述程式碼將生成如圖9-11所示的影象。


如上所見,離海60公里以內,氣溫上升速度很快,從28度陡升至31度,隨後增速漸趨緩和(如果還繼續增長的話),更長的距離才會有小幅上升。這兩種趨勢可分別用兩條直線來表示,直線的表示式為:
其中a為斜率,b為截距。
print svr_lin1.coef_ #斜率print svr_lin1.intercept_ # 截距print svr_lin2.coef_print svr_lin2.intercept_[[0.04794118]][ 27.65617647][[0.00401274]][ 29.98745223]你可能會考慮將這兩條直線的交點作為受海洋影響和不受海洋影響的區域的分界點,或者至少是海洋影響較弱的分界點。
from scipy.optimize import fsolve# 定義了第一條擬合直線defline1(x): a1 = svr_lin1.coef_[0][0] b1 = svr_lin1.intercept_[0] return a1*x + b1# 定義了第二條擬合直線defline2(x): a2 = svr_lin2.coef_[0][0] b2 = svr_lin2.intercept_[0] return a2*x + b2# 定義了找到兩條直線的交點的 x 座標的函式deffindIntersection(fun1,fun2,x0): return fsolve(lambda x : fun1(x) - fun2(x),x0)result = findIntersection(line1,line2,0.0)print "[x,y] = [ %d , %d ]" % (result,line1(result))# x = [0,10,20, ..., 300]x = np.linspace(0,300,31)plt.plot(x,line1(x),x,line2(x),result,line1(result),'ro')執行上述程式碼,將得到交點的座標
[x,y] = [ 53, 30 ]
並得到如圖9-12所示的圖表。


因此,你可以說海洋對氣溫產生影響的平均距離(該天的情況)為53公里。
現在,我們可以轉而分析最低氣溫。
# axis 函式規定了 x 軸和 y 軸的取值範圍plt.axis((0,400,15,25))plt.plot(dist,temp_min,'bo')

在這個例子中,很明顯夜間或早上6點左右的最低溫與海洋無關。如果沒記錯的話,小時候老師教給大家的是海洋能夠緩和低溫,或者說夜間海洋釋放白天吸收的熱量。但是從我們得到情況來看並非如此。我們剛使用的是義大利夏天的氣溫資料,而驗證該假設在冬天或其他地方是否也成立,將會非常有趣。
5.2 溼度資料分析
10個DataFrame物件中還包含溼度這個氣象資料。因此,你也可以考察當天三個近海城市和 三個內陸城市的溼度趨勢。
# 讀取溼度資料y1 = df_ravenna['humidity']x1 = df_ravenna['day']y2 = df_faenza['humidity']x2 = df_faenza['day']y3 = df_cesena['humidity']x3 = df_cesena['day']y4 = df_milano['humidity']x4 = df_milano['day']y5 = df_asti['humidity']x5 = df_asti['day']y6 = df_torino['humidity']x6 = df_torino['day']# 重新定義 fig 和 ax 變數fig, ax = plt.subplots()plt.xticks(rotation=70)# 把時間從 string 型別轉化為標準的 datetime 型別day_ravenna = [parser.parse(x) for x in x1]day_faenza = [parser.parse(x) for x in x2]day_cesena = [parser.parse(x) for x in x3]day_milano = [parser.parse(x) for x in x4]day_asti = [parser.parse(x) for x in x5]day_torino = [parser.parse(x) for x in x6]# 規定時間的表示方式hours = mdates.DateFormatter('%H:%M')ax.xaxis.set_major_formatter(hours)#表示在圖上ax.plot(day_ravenna,y1,'r',day_faenza,y2,'r',day_cesena,y3,'r')ax.plot(day_milano,y4,'g',day_asti,y5,'g',day_torino,y6,'g')fig上述程式碼將生成如圖9-14所示的圖表。


乍看上去好像近海城市的溼度要大於內陸城市,全天溼度差距在20%左右。我們再來看一下溼度的極值和離海遠近之間的關係,是否跟我們的第一印象相符。
# 獲取最大溼度資料hum_max = [df_ravenna['humidity'].max(),df_cesena['humidity'].max(),df_faenza['humidity'].max(),df_ferrara['humidity'].max(),df_bologna['humidity'].max(),df_mantova['humidity'].max(),df_piacenza['humidity'].max(),df_milano['humidity'].max(),df_asti['humidity'].max(),df_torino['humidity'].max()]plt.plot(dist,hum_max,'bo')我們把10個城市的最大溼度與離海遠近之間的關係做成圖表,請見圖9-15。


# 獲取最小溼度hum_min = [df_ravenna['humidity'].min(),df_cesena['humidity'].min(),df_faenza['humidity'].min(),df_ferrara['humidity'].min(),df_bologna['humidity'].min(),df_mantova['humidity'].min(),df_piacenza['humidity'].min(),df_milano['humidity'].min(),df_asti['humidity'].min(),df_torino['humidity'].min()]plt.plot(dist,hum_min,'bo')再來把10個城市的最小溼度與離海遠近之間的關係做成圖表,請見圖9-16。


由圖9-15和圖9-16可以確定,近海城市無論是最大還是最小溼度都要高於內陸城市。然而在 我看來,我們還不能說溼度和距離之間存線上性關係或者其他能用曲線表示的關係。我們採集的 資料點數量(10)太少,不足以描述這類趨勢。
5.3 風向頻率玫瑰圖
在我們採集的每個城市的氣象資料中,下面兩個與風有關:
- 風力(風向)
- 風速
分析存放每個城市氣象資料的DataFrame就會發現,風速不僅跟一天的時間段相關聯,還與 一個介於0~360度的方向有關。例如,每一條測量資料也包含風吹來的方向(圖9-17)。


為了更好地分析這類資料,有必要將其做成視覺化形式,但是對於風力資料,將其製作成使用笛卡兒座標系的線性圖不再是最佳選擇。
要是把一個DataFrame中的資料點做成散點圖
plt.plot(df_ravenna['wind_deg'],df_ravenna['wind_speed'],'ro')就會得到圖9-18這樣的圖表,很顯然該圖的表現力也有不足。


要表示呈360度分佈的資料點,最好使用另一種視覺化方法:極區圖。
首先,建立一個直方圖,也就是將360度分為八個面元,每個面元為45度,把所有的資料點分到這八個面元中。
hist, bins = np.histogram(df_ravenna['wind_deg'],8,[0,360])print histprint binshistogram()函式返回結果中的陣列hist為落在每個面元的資料點數量。
[ 0 5 11 1 0 1 0 0]
返回結果中的陣列bins定義了360度範圍內各面元的邊界。
[ 0. 45. 90. 135. 180. 225. 270. 315. 360.]
要想正確定義極區圖,離不開這兩個陣列。我們將建立一個函式來繪製極區圖,其中部分程式碼在第7章已講過。我們把這個函式定義為showRoseWind(),它有三個引數:values陣列,指的是想為其作圖的資料,也就是這裡的hist陣列;第二個引數city_name為字串型別,指定圖表標題所用的城市名稱;最後一個引數max_value為整型,指定最大的藍色值。
定義這樣一個函式很有用,它既能避免多次重複編寫相同的程式碼,還能增強程式碼的模組化程度,便於你把精力放到與函式內部操作相關的概念上。
defshowRoseWind(values,city_name,max_value): N = 8 # theta = [pi*1/4, pi*2/4, pi*3/4, ..., pi*2] theta = np.arange(0.,2 * np.pi, 2 * np.pi / N) radii = np.array(values) # 繪製極區圖的座標系 plt.axes([0.025, 0.025, 0.95, 0.95], polar=True) # 列表中包含的是每一個扇區的 rgb 值,x越大,對應的color越接近藍色 colors = [(1-x/max_value, 1-x/max_value, 0.75) for x in radii] # 畫出每個扇區 plt.bar(theta, radii, width=(2*np.pi/N), bottom=0.0, color=colors) # 設定極區圖的標題 plt.title(city_name, x=0.2, fontsize=20)你需要修改變數colors儲存的顏色表。這裡,扇形的顏色越接近藍色,值越大。定義好函式之後,呼叫它即可:
showRoseWind(hist,'Ravenna',max(hist))執行上述函式,將得到如圖9-19所示的極區圖。


由圖9-19可見,整個360度的範圍被分成八個區域(面元),每個區域弧長為45度,此外每個區域還有一列呈放射狀排列的刻度值。在每個區域中,用半徑長度可以改變的扇形表示一個數值,半徑越長,扇形所表示的數值就越大。為了增強圖表的可讀性,我們使用與扇形半徑相對應的顏色表。半徑越長,扇形跨度越大,顏色越接近於深藍色。
從剛得到的極區圖可以得知風向在極座標系中的分佈方式。該圖表示這一天大部分時間風都 吹向西南和正西方向。
定義好showRoseWind()函式之後,檢視其他城市的風向情況也非常簡單。
hist, bin = np.histogram(df_ferrara['wind_deg'],8,[0,360])print histshowRoseWind(hist,'Ferrara', max(hist))
計算風速均值的分佈情況
即使是跟風速相關的其他資料,也可以用極區圖來表示。
定義RoseWind_Speed函式,計算將360度範圍劃分成的八個面元中每個面元的平均風速。
defRoseWind_Speed(df_city): # degs = [45, 90, ..., 360] degs = np.arange(45,361,45) tmp = [] for deg in degs: # 獲取 wind_deg 在指定範圍的風速平均值資料 tmp.append(df_city[(df_city['wind_deg']>(deg-46)) & (df_city['wind_deg']<deg)] ['wind_speed'].mean()) return np.array(tmp)這裡 df_city[(df_city['wind_deg']>(deg-46)) & (df_city['wind_deg']<deg)] 獲取的是風向大於 'deg-46' 度和風向小於 'deg' 的資料。
RoseWind_Speed() 函式返回一個包含八個平均風速值的NumPy陣列。該陣列將作為先前定義的showRoseWind()函式的第一個引數,這個函式是用來繪製極區圖的。
showRoseWind(RoseWind_Speed(df_ravenna),'Ravenna',max(hist))圖9-21所示的風向頻率玫瑰圖表示風速在360度範圍內的分佈情況。


六、實驗總結
本章主要目的是演示如何從原始資料獲取資訊。其中有些資訊無法給出重要結論,而有些資訊能夠驗證假設,增加我們對系統狀態的認識,而找出這種資訊也就意味著資料分析取得了成功。
如果學完本課程,對書籍其他內容感興趣歡迎點選以下連結購買書籍: